
Heim >Backend-Entwicklung >Python-Tutorial >Etikettenkodierung in ML
Etikettenkodierung in ML

- 王林Original
- 2024-08-23 06:01:081396Durchsuche
Label Encoding ist eine der am häufigsten verwendeten Techniken beim maschinellen Lernen. Es wird verwendet, um die kategorialen Daten in numerische Form umzuwandeln. So können Daten in das Modell eingepasst werden.
Lassen Sie uns verstehen, warum wir die Label Encoding verwenden. Stellen Sie sich vor, Sie hätten die Daten, die die wesentlichen Spalten in Form einer Zeichenfolge enthalten. Sie können diese Daten jedoch nicht in das Modell integrieren, da die Modellierung nur mit numerischen Daten funktioniert. Was machen wir? Hier kommt die lebensrettende Technik zum Einsatz, die im Vorverarbeitungsschritt ausgewertet wird, wenn wir die Daten für die Anpassung vorbereiten: Label Encoding.
Wir werden den Datensatz iris aus der Bibliothek Scikit-Learn verwenden, um die Funktionsweise von Label Encoder zu verstehen. Stellen Sie sicher, dass die folgenden Bibliotheken installiert sind.
pandas scikit-learn
Für die Installation als Bibliotheken führen Sie den folgenden Befehl aus:
$ python install -U pandas scikit-learn
Öffnen Sie jetzt Google Colab Notebook und tauchen Sie ein in das Codieren und Erlernen von Label Encoder.
Lass uns programmieren
- Beginnen Sie mit dem Importieren der folgenden Bibliotheken:
import pandas as pd from sklearn import preprocessing
- Importieren Sie den Datensatz Iris und initialisieren Sie ihn für die Verwendung:
from sklearn.datasets import load_iris iris = load_iris()
- Jetzt müssen wir die Daten auswählen, die wir kodieren möchten. Wir werden die Arten-Namen für die Schwertlilien kodieren.
species = iris.target_names print(species)
Ausgabe:
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
- Instanziieren wir die Klasse LabelEncoder aus der Vorverarbeitung:
label_encoder = preprocessing.LabelEncoder()
- Jetzt können wir die Daten mit dem Label-Encoder anpassen:
label_encoder.fit(species)
Sie erhalten eine Ausgabe ähnlich dieser:
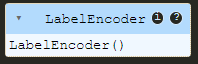
Wenn Sie diese Ausgabe erhalten, haben Sie die Daten erfolgreich angepasst. Die Frage ist jedoch, wie Sie herausfinden, welche Werte jeder Art zugeordnet werden und in welcher Reihenfolge.
Die Reihenfolge, in der Label Encoder die Daten anpasst, wird im Attribut Klassen_ gespeichert. Die Kodierung beginnt bei 0 bis data_length-1.
label_encoder.classes_
Ausgabe:
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
Der Etikettenkodierer sortiert die Daten automatisch und beginnt die Kodierung von der linken Seite. Hier:
setosa -> 0 versicolor -> 1 virginica -> 2
- Jetzt testen wir die angepassten Daten. Wir werden die Irisart Setosa umwandeln.
label_encoder.transform(['setosa'])
Ausgabe: array([0])
Nochmals, wenn Sie die Art virginica transformieren.
label_encoder.transform(['virginica'])
Ausgabe: array([2])
Sie können auch die Liste der Arten eingeben, z. B. ["setosa", "virginica"]
Scikit Learn-Dokumentation für Label-Encoder >>>
Das obige ist der detaillierte Inhalt vonEtikettenkodierung in ML. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!