
Heim >System-Tutorial >LINUX >Redis-Hochverfügbarkeitspraxis
Redis-Hochverfügbarkeitspraxis

- 王林Original
- 2024-08-20 16:51:02908Durchsuche
Redis ist eine Open-Source-Schlüsselwertdatenbank im Protokolltyp, die in der ANSI-C-Sprache geschrieben ist, Netzwerke unterstützt, speicherbasiert und persistent sein kann und APIs in mehreren Sprachen bereitstellt.
Heutzutage wachsen Internet-Geschäftsdaten schneller und die Datentypen werden immer zahlreicher, was höhere Anforderungen an die Geschwindigkeit und Fähigkeiten der Datenverarbeitung stellt. Redis ist eine nicht relationale Open-Source-In-Memory-Datenbank, die Entwicklern ein disruptives Erlebnis bietet. Redis wurde von Anfang bis Ende mit Blick auf hohe Leistung entwickelt und ist die schnellste heute verfügbare NoSQL-Datenbank.
Neben der hohen Leistung ist auch die hohe Verfügbarkeit ein wichtiger Gesichtspunkt. Das Internet bietet 7x24 ununterbrochenen Service und Failover mit der höchsten Geschwindigkeit bei einem Ausfall, was zu minimalen Verlusten für das Unternehmen führen kann.
Was sind also die Hochverfügbarkeitsarchitekturen in praktischen Anwendungen? Welche Vor- und Nachteile gibt es zwischen den Architekturen? Wie sollen wir wählen? Was sind einige Best Practices?
Bevor wir die Hochverfügbarkeitslösung von Redis erläutern, werfen wir zunächst einen Blick auf das Redis Sentinel-Prinzip.
- Der Sentinel-Cluster erkennt den Master über die angegebene Konfigurationsdatei und überwacht den Master beim Start. Erhalten Sie alle Slave-Server unter diesem Server, indem Sie Informationsinformationen an den Master senden.
- Der Sentinel-Cluster sendet über Befehlsverbindungen Hallo-Informationen (einmal pro Sekunde) an die überwachten Master- und Slave-Server. Diese Informationen umfassen Sentinels eigene IP, Port, ID usw., um seine Existenz anderen Sentinels mitzuteilen.
- Der Sentinel-Cluster empfängt Hallo-Informationen, die von anderen Sentinels über Abonnementverbindungen gesendet werden, um andere Sentinels zu erkennen, die denselben Master-Server überwachen. Die Cluster erstellen Befehlsverbindungen untereinander für die Kommunikation, da es bereits Master-Slave-Server als Absender gibt Es wird eine Abonnementverbindung zwischen Sentinel und dem Vermittler erstellt, der die Hallo-Informationen erhält.
- Der Sentinel-Cluster verwendet den Ping-Befehl, um den Status der Instanz zu erkennen. Wenn innerhalb der angegebenen Zeit (Down-After-Millisekunden) keine Antwort erfolgt oder eine falsche Antwort zurückgegeben wird, wird die Instanz als offline eingestuft.
- Wenn die Failover-Aktiv/Standby-Umschaltung ausgelöst wird, wird der Failover nicht sofort fortgesetzt. Die Mehrheit der Sentinels im Sentinel muss autorisiert werden, bevor der Failover durchgeführt werden kann Erhalten Sie die Genehmigung der benannten Quorum-Sentinels und wechseln Sie nach Erfolg in den ODOWN-Status. Wenn beispielsweise 2 Quoren unter 5 Sentinels konfiguriert sind, wird ein Failover ausgeführt, wenn die 2 Sentinels glauben, dass der Master tot ist.
- Sentinel sendet den Befehl SLAVEOF NO ONE an den als Master ausgewählten Slave. Voraussetzung für die Auswahl des Slaves ist, dass Sentinel die Slaves zunächst nach ihrer Priorität sortiert. Wenn die Prioritäten gleich sind, überprüfen Sie das Replikationssubskript. Dasjenige, das mehr Replikationsdaten vom Master erhält, wird zuerst eingestuft. Wenn Priorität und Index gleich sind, wird derjenige mit der kleineren Prozess-ID ausgewählt.
- Nachdem Sentinel autorisiert wurde, erhält es die neueste Konfigurationsversionsnummer (config-epoch) des ausgefallenen Masters. Wenn die Failover-Ausführung abgeschlossen ist, wird diese Versionsnummer für die neueste Konfiguration per Broadcast verwendet. Andere Sentinels benachrichtigen das Formular und andere Sentinels aktualisieren die Konfiguration des entsprechenden Masters.
1 bis 3 sind automatische Erkennungsmechanismen:
- Senden Sie alle 10 Sekunden den Info-Befehl an den überwachten Master und erhalten Sie anhand der Antwort die aktuellen Master-Informationen.
- Senden Sie PING-Befehle mit einer Frequenz von 1 Sekunde an alle Redis-Server, einschließlich Sentinel, und ermitteln Sie anhand der Antwort, ob der Server online ist.
- Senden Sie die aktuelle Sentinel-Master-Informationsnachricht im Abstand von 2 Sekunden an alle überwachten Master- und Slave-Server.
4 ist der Erkennungsmechanismus, 5 und 6 sind Failover-Mechanismen und 7 ist der Update-Konfigurationsmechanismus. [1]
Nachdem wir das Prinzip von Redis Sentinel erklärt haben, erklären wir nun die häufig verwendete Redis-Hochverfügbarkeitsarchitektur.
- Redis Sentinel-Cluster + Intranet-DNS + benutzerdefiniertes Skript
- Redis Sentinel Cluster + VIP + benutzerdefiniertes Skript
- Kapseln Sie den Client, um eine direkte Verbindung zum Redis Sentinel-Port herzustellen
- JedisSentinelPool, geeignet für Java
- PHP ist selbstverpackt und basiert auf PHPREDIS
- Redis Sentinel Cluster + Keepalived/Haproxy
- Redis M/S + Keepalived
- Redis-Cluster
- Twemproxy
- Codis
Das Folgende wird einzeln mit Bildern und Text erklärt.
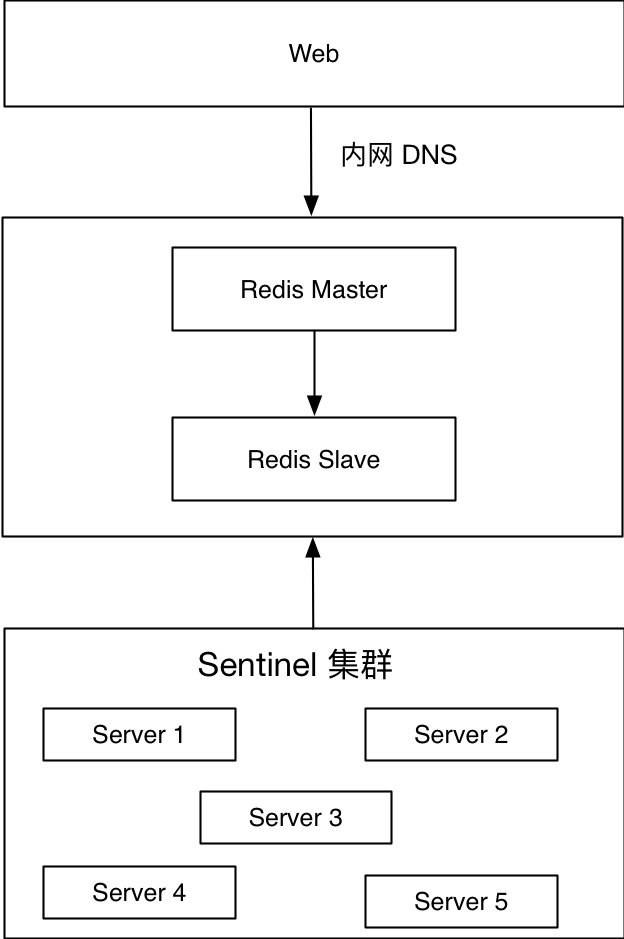
Das Bild oben zeigt eine Lösung, die in einer Online-Umgebung angewendet wurde. Die unterste Ebene ist der Redis Sentinel-Cluster, der als Agent für den Redis-Master und -Slave fungiert. Die Webseite stellt eine Verbindung zum Intranet-DNS her, um Dienste bereitzustellen. Intranet-DNS wird nach bestimmten Regeln zugewiesen, z. B. xxxx.redis.cache/queue.port.xxx.xxx Das erste Segment gibt die Geschäftsabkürzung an, das zweite Segment gibt an, dass es sich um den Redis-Intranet-Domänennamen handelt Das dritte Segment repräsentiert den Redis-Typ, der Cache repräsentiert den Cache, die Warteschlange repräsentiert die Warteschlange, das vierte Segment repräsentiert den Redis-Port und das fünfte und sechste Segment repräsentieren den Hauptdomänennamen des Intranets.
Wenn der Masterknoten ausfällt, z. B. aufgrund eines Maschinenausfalls, eines Redis-Knotenausfalls oder einer Nichterreichbarkeit des Netzwerks, ruft der Sentinel-Cluster das konfigurierte client-reconfig-script-Skript auf, um den Intranetdomänennamen des entsprechenden Ports zu ändern. Der Intranet-Domänenname des entsprechenden Ports verweist auf den neuen Redis-Masterknoten.
Vorteile:
- Schalten der zweiten Ebene, schließen Sie den gesamten Schaltvorgang innerhalb von 10 Sekunden ab
- Skriptanpassung und steuerbare Architektur
- Transparent für die Anwendung muss sich das Frontend nicht um Änderungen im Backend kümmern
Nachteile:
- Die Wartungskosten sind etwas hoch. Es wird empfohlen, in mehr als 3 Maschinen für den Redis Sentinel-Cluster zu investieren Abhängig vom DNS, es gibt eine Verzögerung bei der Auflösung
- Der Sentinel-Modus-Dienst wird für kurze Zeit nicht verfügbar sein
- Diese Lösung kann nicht verwendet werden, wenn auf den Dienst über das externe Netzwerk zugegriffen wird
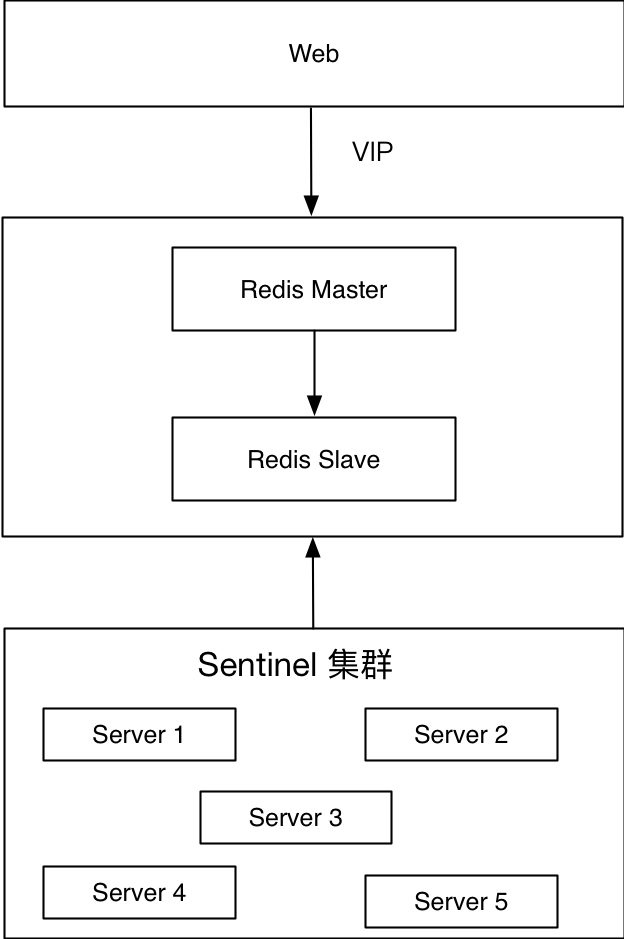
Vorteile:
Schalten der zweiten Ebene: Schließen Sie den gesamten Schaltvorgang innerhalb von 5 Sekunden ab
- Skriptanpassung und steuerbare Architektur
- Transparent für die Anwendung muss sich das Frontend nicht um Änderungen im Backend kümmern
- Nachteile:
Die Wartungskosten sind etwas hoch. Es wird empfohlen, in mehr als 3 Maschinen für den Redis Sentinel-Cluster zu investieren
Die Verwendung von VIP erhöht die Wartungskosten und birgt das Risiko eines IP-Chaos- Der Sentinel-Modus-Dienst wird für kurze Zeit nicht verfügbar sein
- 3.3 Kapseln Sie den Client, um eine direkte Verbindung zum Redis Sentinel-Port herzustellen
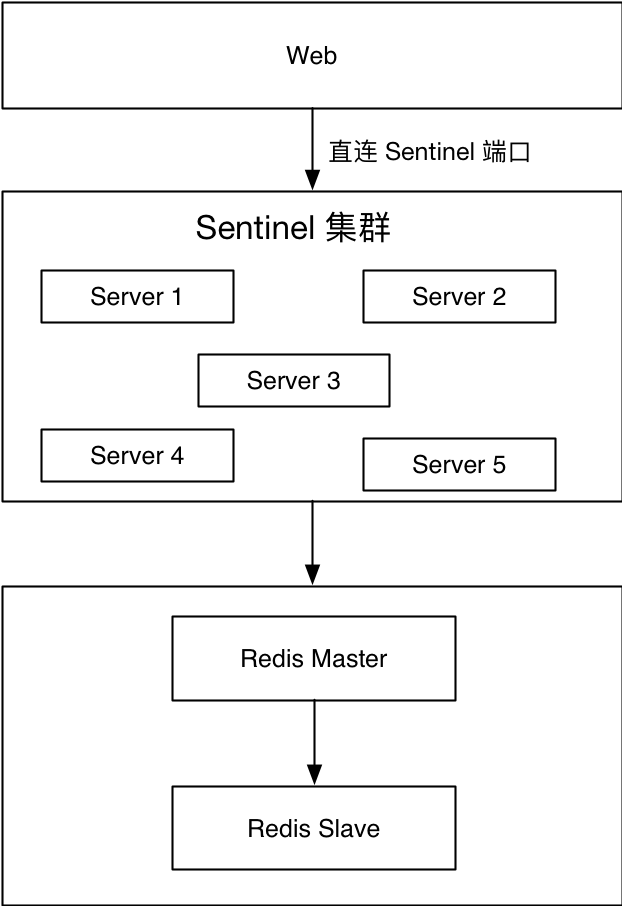
Einige Unternehmen können nur über das externe Netzwerk auf Redis zugreifen. Keine der beiden oben genannten Lösungen ist verfügbar, daher wurde diese Lösung abgeleitet. Web verwendet den Client, um eine Verbindung zu einem bestimmten Port einer Maschine in einem der Redis Sentinel-Cluster herzustellen, ruft dann über diesen Port den aktuellen Masterknoten ab und stellt dann eine Verbindung zum echten Redis-Masterknoten her, um entsprechende Verkäufervorgänge auszuführen. Es ist wichtig zu beachten, dass sowohl der Redis Sentinel-Port als auch der Redis-Masterknoten offenen Zugriff erfordern. Wenn das Front-End-Unternehmen Java verwendet, kann JedisSentinelPool wiederverwendet werden. Wenn das Front-End-Unternehmen PHP verwendet, kann die sekundäre Kapselung auf Basis von PHPREDIS erfolgen.
Vorteile:
- Service erkennt Störungen zeitnah
- DBA-Wartungskosten sind niedrig
Nachteile:
- Abhängig vom Kundensupport Sentinel
- Sentinel-Server und Redis-Knoten erfordern offenen Zugriff
- Aufdringlich für die Anwendung
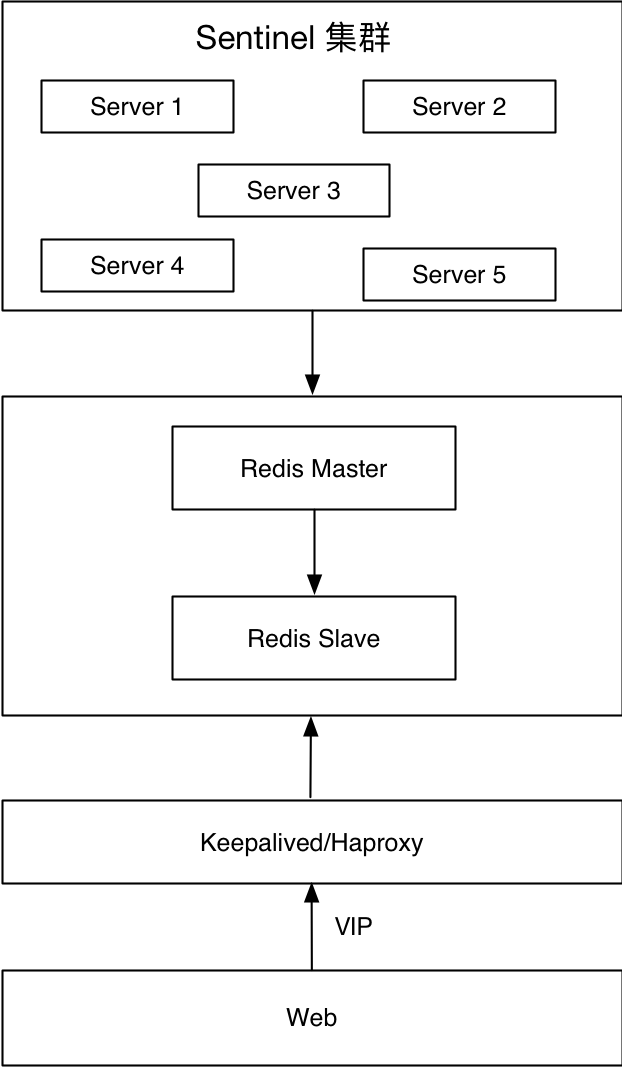
Die unterste Ebene ist der Redis Sentinel-Cluster, der als Agent für Redis-Master und -Slave fungiert, und die Webseite stellt Dienste über VIP bereit. Wenn der Masterknoten ausfällt, beispielsweise aufgrund eines Maschinenausfalls, eines Redis-Knotenausfalls oder einer Nichterreichbarkeit des Netzwerks, wird die Umschaltung zwischen Redis durch den internen Mechanismus von Redis Sentinel und die VIP-Umschaltung durch Keepalived garantiert.
Vorteile:
- Wechseln Sie in Sekundenschnelle
- Transparent für die Anwendung
Nachteile:
- Hohe Wartungskosten
- Gehirnspaltung
- Der Sentinel-Modus-Dienst wird für kurze Zeit nicht verfügbar sein
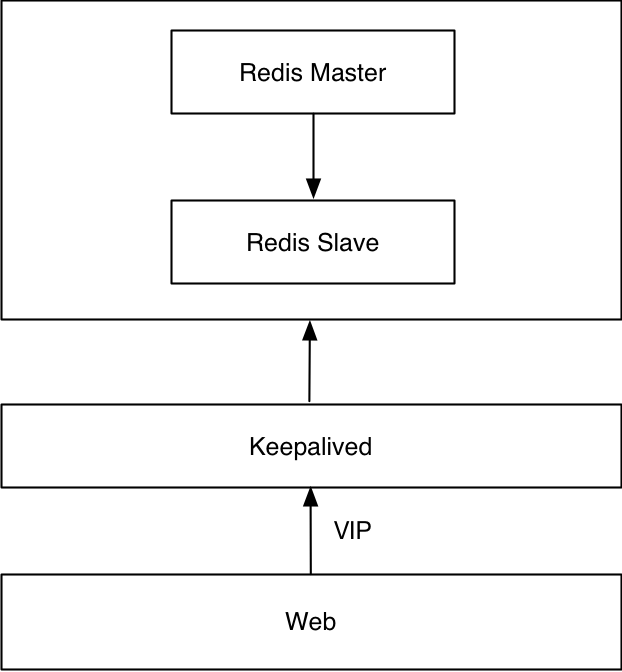
Diese Lösung verwendet Redis Sentinel nicht. Diese Lösung verwendet native Master-Slave- und Keepalived-VIP-Umschaltungen. Für die Umschaltung zwischen Redis-Master-Slave sind benutzerdefinierte Skripte erforderlich.
Vorteile:
- Wechseln Sie in Sekundenschnelle
- Transparent für die Anwendung
- Einfache Bereitstellung und geringe Wartungskosten
Nachteile:
- Erfordert Skript zur Implementierung der Umschaltfunktion
- Gehirnspaltung
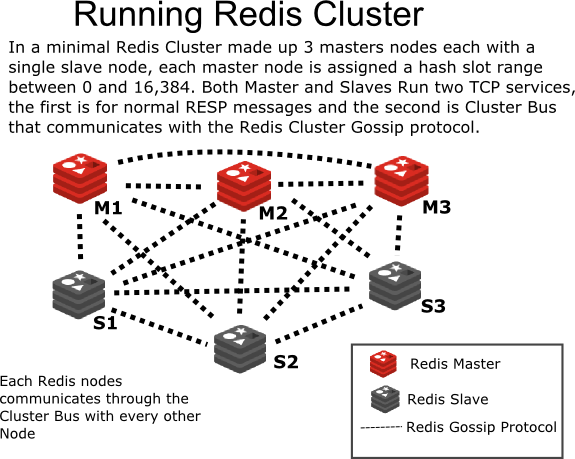
Von: http://intro2libsys.com/focused-redis-topics/day-one/intro-redis-cluster
Redis 3.0.0 wurde am 2. April 2015, also vor mehr als zwei Jahren, offiziell veröffentlicht. Der Redis-Cluster verwendet den P2P-Modus und ist nicht zentralisiert. Teilen Sie den Schlüssel in 16384 Slots auf, und jede Instanz ist für einen Teil der Slots verantwortlich. Der Client fordert die entsprechenden Daten an. Wenn der Instanz-Slot keine entsprechenden Daten hat, wird die Instanz an die entsprechende Instanz weitergeleitet. Darüber hinaus synchronisiert der Redis-Cluster Knoteninformationen über das Gossip-Protokoll.
Vorteile:
- Die Komponenten sind komplett im Lieferumfang enthalten, lassen sich einfach bereitstellen und sparen Maschinenressourcen
- Leistung ist besser als im Proxy-Modus
- Automatisches Failover und verfügbare Daten während der Slot-Migration
- Offizielle native Cluster-Lösung, garantierte Updates und Support
Nachteile:
- Die Architektur ist relativ neu und es gibt nur wenige Best Practices
- Die Unterstützung für die Mehrtastenbedienung ist begrenzt (der Fahrer kann das Land durch Kurven retten)
- Um die Leistung zu verbessern, muss der Client Routing-Tabelleninformationen zwischenspeichern
- Knotenerkennung und Reshard-Vorgänge sind nicht ausreichend automatisiert
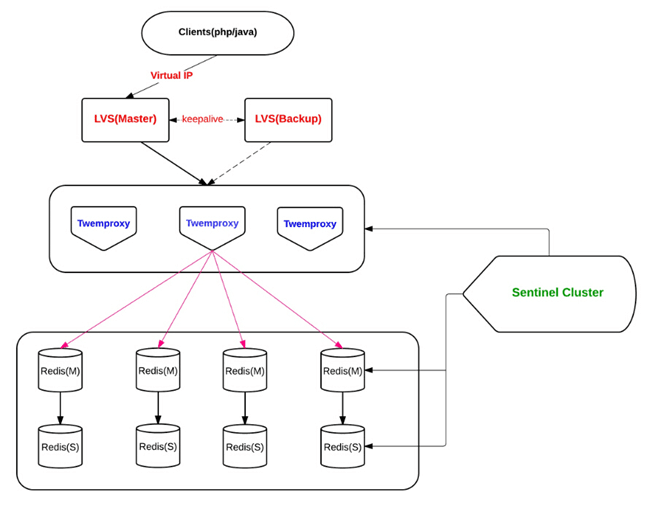
Von: http://engineering.bloomreach.com/the-evolution-of-fault-tolerant-redis-cluster
Mehrere isomorphe Twemproxy (gleiche Konfiguration) arbeiten gleichzeitig, akzeptieren Client-Anfragen und leiten sie gemäß dem Hash-Algorithmus an die entsprechenden Redis weiter.
Die Twemproxy-Lösung ist relativ ausgereift. Unser Team verwendet diese Lösung schon seit langem, aber die Wirkung ist nicht sehr zufriedenstellend. Einerseits ist das Positionierungsproblem schwieriger, andererseits ist die Unterstützung für die automatische Eliminierung von Knoten nicht sehr freundlich.
Vorteile:
- Einfach zu entwickeln und nahezu transparent für die Anwendung
- Lange Geschichte und ausgereifte Lösungen
Nachteile:
- Proxy beeinträchtigt die Leistung
- LVS und Twemproxy werden Engpässe bei der Knotenleistung haben
- Redis-Erweiterung ist sehr mühsam
- Twitter hat die interne Verwendung dieser Lösung aufgegeben und die neue Architektur ist nicht Open Source
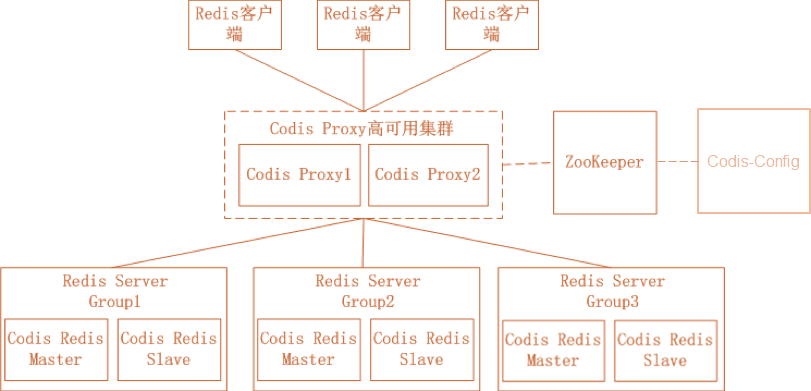
Von: https://github.com/CodisLabs/codis
Codis ist ein Open-Source-Produkt von Wandoujia und umfasst viele Komponenten. Darunter speichert ZooKeeper Routing-Tabellen und Proxy-Knoten-Metadaten und verteilt Codis-Config-Befehle. Proxy ist ein zustandsloser Proxy, der mit dem Redis-Protokoll kompatibel ist. Codis-Redis ist eine sekundäre Entwicklung, die auf der Redis 2.8-Version basiert und Slot-Unterstützung hinzufügt, um die Datenmigration zu erleichtern.
Vorteile:
- Einfach zu entwickeln und nahezu transparent für die Anwendung
- Leistung ist besser als Twemproxy
- Verfügt über eine grafische Oberfläche, einfache Erweiterung sowie bequeme Bedienung und Wartung
Nachteile:
- Proxy beeinträchtigt immer noch die Leistung
- Zu viele Komponenten, die viele Maschinenressourcen erfordern
- Der Redis-Code wurde geändert, was dazu führt, dass keine Synchronisierung mit dem offiziellen Code möglich ist und die Umsetzung neuer Funktionen langsam erfolgt
- Das Entwicklungsteam bereitet sich darauf vor, „reborndb“ basierend auf der Redis-Transformation zu fördern
Die sogenannten Best Practices sind Praktiken, die für bestimmte Szenarien am besten geeignet sind.
Wir empfehlen hauptsächlich die folgenden Pläne:
- Redis Sentinel-Cluster + Intranet-DNS + benutzerdefiniertes Skript
- Redis Sentinel Cluster + VIP + benutzerdefiniertes Skript
Im Folgenden sind die Best Practices während des tatsächlichen Kampfes zusammengefasst:
- Für den Redis Sentinel-Cluster wird die Verwendung von >= 5 Maschinen empfohlen
- Verschiedene große Unternehmen können einen Redis Sentinel-Cluster als Proxy für alle Ports unter dem Unternehmen verwenden
- Teilen Sie das Redis-Port-Sortiment nach verschiedenen Unternehmen auf
- Für eine einfache Erweiterung wird empfohlen, benutzerdefinierte Skripte in Python zu implementieren
- Benutzerdefinierte Skripte müssen beachtet werden, um die aktuelle Sentinel-Rolle zu bestimmen
- Übergeben Sie die Parameter des benutzerdefinierten Skripts:
- -Bibliothek zu verwenden, um den wiederholten Aufbau von SSH-Verbindungen und den Zeitaufwand zu vermeiden Um die SSH-Verbindung zu beschleunigen, wird empfohlen, die folgenden beiden Parameter zu deaktivieren DNS-Nr. verwenden
-
- GSSAPIAuthentication no
- Wenn Sie eine Benachrichtigung über WeChat oder E-Mail erhalten, wird empfohlen, einen Prozess zu forken, um eine Blockierung des Hauptprozesses zu vermeiden
Automatische Umschaltung und Failover. Es wird empfohlen, alle Vorgänge innerhalb von 15 Sekunden abzuschließen. - 0×05 Zusammenfassung
dbarobinwen@gmail.com senden Angehängter PPT-Download: https://github.com/dbarobin/slides
Videowiedergabe: Best Practices für die Redis-Hochverfügbarkeitsarchitektur
0×06 Danke
0×07 Referenz
[1] jyzhou (12.06.2016). Abgerufen von http://www.cnblogs.com/zhoujinyi/p/5570024.
Das obige ist der detaillierte Inhalt vonRedis-Hochverfügbarkeitspraxis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das Reinigungsprinzip des Ordners /tmp/ im Linux-System und die Rolle der tmp-Datei
- Detaillierte Erläuterung der Berechnung der spezifischen CPU-Auslastung unter Linux
- So melden Sie sich in Debian 11 ab oder fahren das System herunter
- So ändern Sie den Desktop-Hintergrund in Ubuntu
- Ubuntu 21.04 Beta veröffentlicht, Update-Übersicht