
Heim >Hardware-Tutorial >Hardware-Rezension >Große Models haben ihr eigenes Sprachverständnis! MIT-Papier enthüllt den „Denkprozess' großer Modelle
Große Models haben ihr eigenes Sprachverständnis! MIT-Papier enthüllt den „Denkprozess' großer Modelle

- 王林Original
- 2024-08-17 15:40:45746Durchsuche
Große Modelle können Ihr eigenes Verständnis der realen Welt entwickeln!
Eine Studie des MIT ergab, dass mit zunehmender Leistungsfähigkeit eines Modells sein Verständnis der Realität möglicherweise über die bloße Nachahmung hinausgeht.
Wenn das große Model beispielsweise noch nie einen Geruch gerochen hat, bedeutet das dann, dass es Gerüche nicht verstehen kann?
Untersuchungen haben ergeben, dass einige Konzepte spontan simuliert werden können, um das Verständnis zu erleichtern.
Diese Forschung bedeutet, dass von großen Modellen in Zukunft ein tieferes Verständnis der Sprache und der Welt erwartet wird. Das Papier wurde von der Spitzenkonferenz ICML 24 angenommen.

Die Autoren dieses Papiers sind der chinesische Doktorand Charles Jin und sein Betreuer Professor Martin Rinard vom MIT Computer and Artificial Intelligence Laboratory (CSAIL).
In der Studie bat der Autor das große Modell, nur den Codetext zu lernen, und stellte fest, dass das Modell nach und nach die Bedeutung dahinter erfasste.
Professor Rinard sagte, dass diese Forschung direkt eine Kernfrage der modernen künstlichen Intelligenz anspricht –
Ob die Fähigkeiten großer Modelle einfach auf groß angelegten statistischen Korrelationen beruhen oder ob sie ein aussagekräftiges Verständnis der realen Probleme generieren, um die es sich dabei handelt beabsichtigt zu lösen?
△Quelle: Offizielle Website des MIT
Gleichzeitig löste diese Forschung auch viele Diskussionen aus.
Einige Internetnutzer sagten, dass große Modelle zwar Sprache anders verstehen als Menschen, diese Studie aber zumindest zeigt, dass das Modell mehr kann, als nur Trainingsdaten zu speichern.

Lassen Sie das große Modell reinen Code lernen
Um zu untersuchen, ob das große Modell ein Verständnis auf semantischer Ebene erzeugen kann, erstellte der Autor einen synthetischen Datensatz, der aus Programmcode und den entsprechenden Eingaben und Ausgaben besteht.
Diese Codeprogramme sind in einer Lehrsprache namens Karel geschrieben und werden hauptsächlich zur Umsetzung der Aufgabe von Robotern verwendet, die in einer 2D-Gitterwelt navigieren.
Diese Gitterwelt besteht aus 8x8 Gittern, jedes Gitter kann Hindernisse, Markierungen oder offene Räume enthalten. Der Roboter kann sich zwischen Gittern bewegen und Vorgänge wie das Platzieren/Aufnehmen von Markierungen ausführen.
Karel-Sprache enthält 5 Grundoperationen – move (einen Schritt vorwärts), turnLeft (um 90 Grad nach links drehen), turnRight (um 90 Grad nach rechts drehen), pickMarker (Marker aufnehmen), putMarker (Marker platzieren), aus denen das Programm besteht Eine Folge dieser primitiven Operationen.
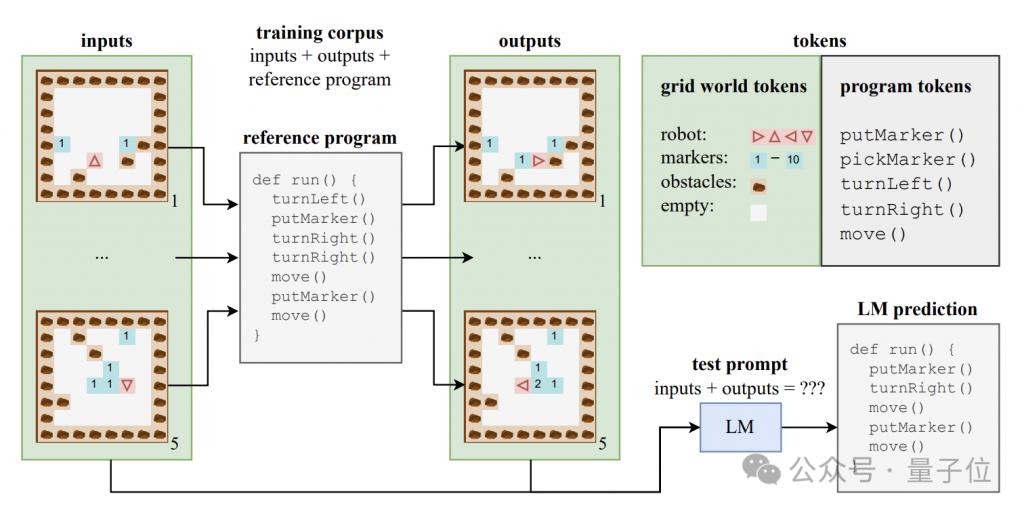
Der Autor hat zufällig einen Trainingssatz mit 500.000 Karel-Programmen generiert, wobei jedes Programm eine Länge zwischen 6 und 10 hat.
Jedes Trainingsbeispiel besteht aus drei Teilen: 5 Eingabezustände, 5 Ausgabezustände und vollständiger Programmcode. Die Eingabe- und Ausgabezustände werden in einem bestimmten Format in Zeichenfolgen codiert.
Anhand dieser Daten trainierten die Autoren eine Variante des CodeGen-Modells der Standard-Transformer-Architektur.
Während des Trainingsprozesses kann das Modell auf die Eingabe- und Ausgabeinformationen und Programmpräfixe in jedem Beispiel zugreifen, es kann jedoch nicht den vollständigen Verlauf und die Zwischenzustände der Programmausführung sehen.
Zusätzlich zum Trainingssatz hat der Autor auch einen Testsatz mit 10.000 Proben erstellt, um die Generalisierungsleistung des Modells zu bewerten.
Um zu untersuchen, ob das Sprachmodell die Semantik hinter dem Code erfasst, und gleichzeitig ein tiefes Verständnis des „Denkprozesses“ des Modells zu erlangen, entwarf der Autor eine Detektorkombination, die einen linearen Klassifikator und einen einfachen/doppelten versteckten Klassifikator umfasst Schicht MLP.
Die Eingabe des Detektors ist der verborgene Zustand des Sprachmodells beim Generieren von Programm-Tokens, und das Vorhersageziel ist der Zwischenzustand der Programmausführung, insbesondere einschließlich der Ausrichtung (Richtung) des Roboters, versetzt relativ zur Anfangsposition (Position) und ob die Vorderseite dem Hindernis (Hindernis) zugewandt ist, sind diese drei Merkmale.
Während des Trainingsprozesses des generativen Modells zeichnete der Autor alle 4000 Schritte die oben genannten drei Merkmale auf und zeichnete auch den verborgenen Zustand des generativen Modells auf, um einen Trainingsdatensatz für den Detektor zu bilden.
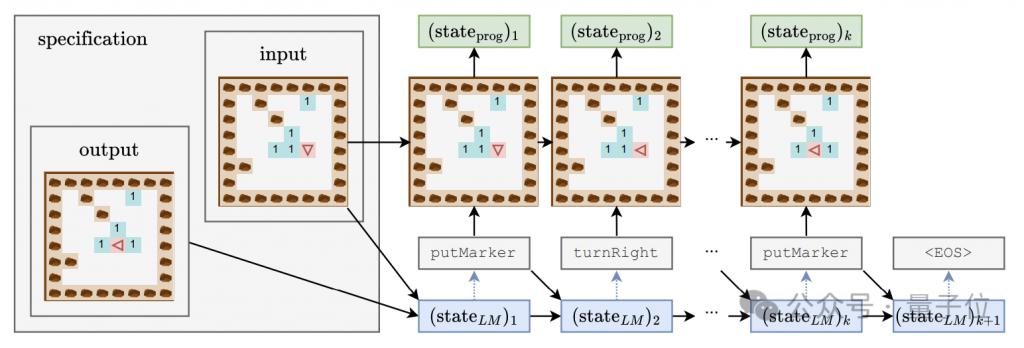
Drei Phasen des Lernens mit großen Modellen
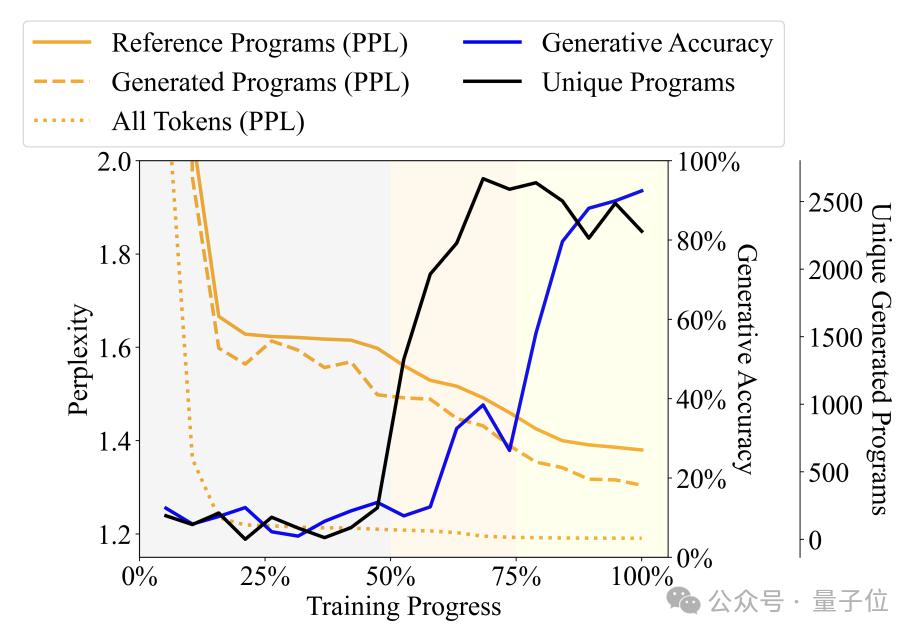
Durch Beobachtung der Veränderungen in der Vielfalt, Verwirrung und anderen Indikatoren der vom Sprachmodell während des Trainingsprozesses generierten Programme hat der Autor den Trainingsprozess in drei Phasen unterteilt -
Phase des Plapperns (Unsinn): Das Ausgabeprogramm wiederholt sich stark und die Genauigkeit des Detektors ist instabil.
Grammatikerwerbsphase: Die Programmvielfalt nimmt schnell zu, die Generierungsgenauigkeit nimmt leicht zu und die Verwirrung nimmt ab, was darauf hinweist, dass das Sprachmodell die syntaktische Struktur des Programms gelernt hat.
Semantische Erfassungsphase: Der Grad der Programmvielfalt und die Beherrschung der syntaktischen Struktur sind stabil, aber die Generierungsgenauigkeit und die Detektorleistung sind erheblich verbessert, was darauf hinweist, dass das Sprachmodell die Semantik des Programms gelernt hat.
Konkret nimmt die Babbling-Phase die ersten 50 % des gesamten Trainingsprozesses ein. Wenn das Training beispielsweise etwa 20 % erreicht, generiert das Modell unabhängig von der eingegebenen Spezifikation nur ein festes Programm – „pickMarker“ wird neunmal wiederholt .
Die Grammatikerwerbsphase liegt bei 50 % bis 75 % des Trainingsprozesses. Die Ratlosigkeit des Modells beim Karel-Programm ist deutlich zurückgegangen, was darauf hindeutet, dass sich das Sprachmodell besser an die statistischen Merkmale des Karel-Programms angepasst hat Die Genauigkeit des generierten Programms hat sich nicht wesentlich erhöht (von etwa 10 % auf etwa 25 %), aber die Aufgabe konnte immer noch nicht genau ausgeführt werden.
Die semantische Erfassungsphase beträgt die letzten 25 %. Die Genauigkeit des Programms hat sich dramatisch verbessert, von etwa 25 % auf über 90 %.
Weitere Experimente ergaben, dass der Detektor nicht nur den gleichzeitigen Zeitschritt zum Zeitpunkt t vorhersagen kann, sondern auch den Programmausführungsstatus nachfolgender Zeitschritte vorhersagen kann.
Angenommen, das generative Modell generiert zum Zeitpunkt t das Token „move“ und zum Zeitpunkt t+1 „turnLeft“.
Gleichzeitig ist der Programmstatus zum Zeitpunkt t, dass der Roboter nach Norden zeigt und sich bei den Koordinaten (0,0) befindet, während der Roboter zum Zeitpunkt t+1 so sein wird, dass der Roboter nach Westen zeigt die Position unverändert.
Wenn der Detektor aus dem verborgenen Zustand des Sprachmodells zum Zeitpunkt t erfolgreich vorhersagen kann, dass der Roboter zum Zeitpunkt t+1 nach Westen blicken wird, bedeutet dies, dass der verborgene Zustand vor der Generierung von „turnLeft“ bereits die Auswirkungen davon enthält Informationen zur Änderung des Betriebsstatus.
Dieses Phänomen zeigt, dass das Modell nicht nur über ein semantisches Verständnis des generierten Programmteils verfügt, sondern bei jedem Schritt der Generierung den als nächstes zu generierenden Inhalt bereits vorhergesehen und geplant hat, was eine vorläufige zukunftsorientierte Denkfähigkeit zeigt.
Aber diese Entdeckung hat neue Fragen zu dieser Forschung aufgeworfen –
Ist die im Experiment beobachtete Verbesserung der Genauigkeit wirklich eine Verbesserung des generativen Modells oder ist sie das Ergebnis der eigenen Schlussfolgerung des Detektors?
Um diesen Zweifel auszuräumen, fügte der Autor ein Interventionsexperiment zur semantischen Erkennung hinzu.
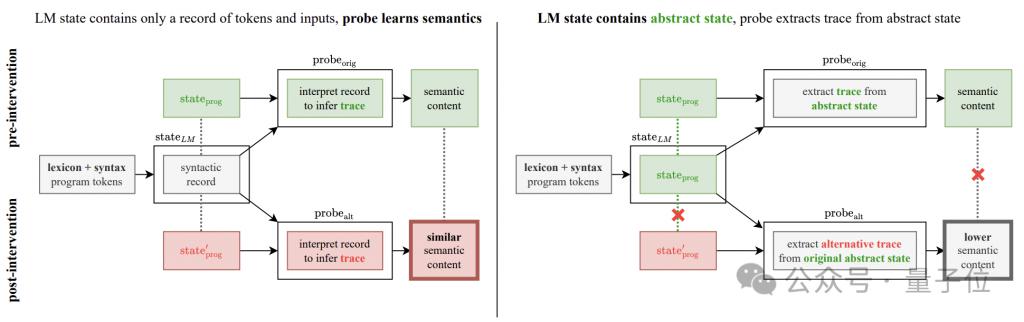
Die Grundidee des Experiments besteht darin, die semantischen Interpretationsregeln von Programmoperationen zu ändern, die in zwei Methoden unterteilt sind: „Flip“ und „Adversarial“.
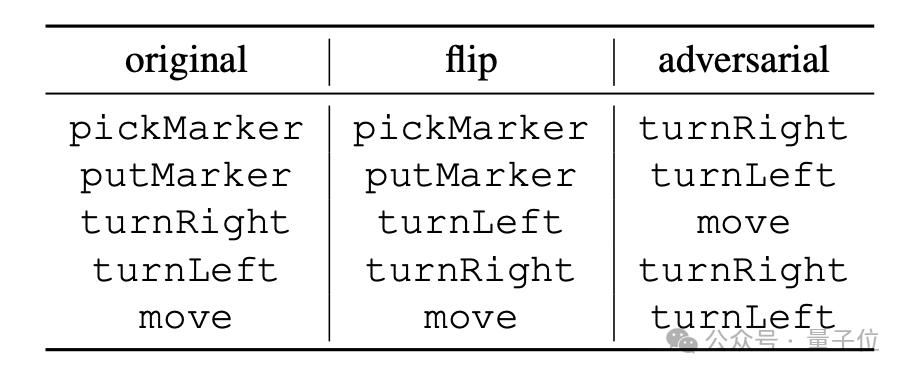
„umdrehen“ ist eine erzwungene Umkehrung der Bedeutung der Anweisung. Beispielsweise wird „turnRight“ zwangsweise als „turn left“ interpretiert. Allerdings können nur „turnLeft“ und „turnRight“ diese Art der Umkehrung durchführen
„gegnerisch“ soll erzwingen Die allen Anweisungen entsprechende Semantik wird zufällig gemischt, wie in der folgenden Tabelle gezeigt.
Wenn der verborgene Zustand des generativen Modells nur die syntaktische Struktur des Programms und nicht die semantischen Informationen kodiert, sollte der Detektor dennoch in der Lage sein, die geänderten semantischen Informationen mit der gleichen Leistung aus dem verborgenen Zustand zu extrahieren.
Wenn im Gegenteil die Leistung des Detektors erheblich sinkt, bedeutet dies, dass die vom Detektor angezeigte Leistungsverbesserung tatsächlich darauf zurückzuführen ist, dass der verborgene Zustand des generativen Modells die tatsächliche Semantik codiert.
Experimentelle Ergebnisse zeigen, dass die Leistung des Detektors unter beiden neuen Semantiken deutlich abnimmt.
Besonders deutlicher im „kontradiktorischen“ Modus, was auch mit der Eigenschaft übereinstimmt, dass sich die Semantik in diesem Modus deutlich von der ursprünglichen Semantik unterscheidet.
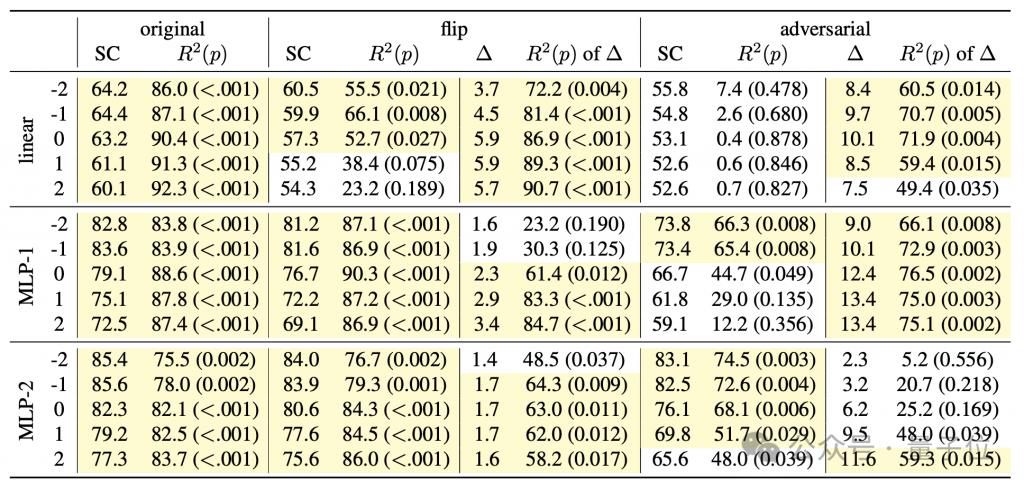
Diese Ergebnisse schließen die Möglichkeit, dass der Detektor „semantische Zuordnung selbst lernt“, stark aus und bestätigen damit weiter, dass das generative Modell tatsächlich die Bedeutung des Codes erfasst.
Papieradresse:
https://icml.cc/virtual/2024/poster/34849
Referenzlink:
[ 1 ] https://news.mit.edu/2024/llms-develop-own- Verständnis der Realität als Verbesserung der Sprachfähigkeiten 0814
[ 2 ] https://www.reddit.com/r/LocalLLaMA/comments/1esxkin/llms_develop_their_own_understanding_of_reality/
Das obige ist der detaillierte Inhalt vonGroße Models haben ihr eigenes Sprachverständnis! MIT-Papier enthüllt den „Denkprozess' großer Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Der Groll von Ni Shuihans intelligentem NPC bereitet mir ein schlechtes Gewissen ...
- Tatsächliche Messung der Signalstärke im Vergleich zwischen iPhone 15 und Mate60P, Ergebnisse enthüllt
- Huawei Mate 60 Pro-Signaltest: Es gibt Bedauern, aber es gibt noch mehr Überraschungen
- Schätzen Sie den facettenreichen Charme von Aichir Time Elf: sowohl frisch und smart als auch smart und multifunktional
- Tatsächliche Testergebnisse von Huawei-Satellitenanrufen: Die Klangqualität übertrifft die professioneller Satellitentelefone