
Heim >System-Tutorial >LINUX >Rekursive Operationen in der Softwareentwicklung
Rekursive Operationen in der Softwareentwicklung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-16 19:54:301231Durchsuche

Werfen wir einen Blick auf diese klassische rekursive Fakultät:
#include
int factorial(int n)
{
int previous = 0xdeadbeef;
if (n == 0 || n == 1) {
return 1;
}
previous = factorial(n-1);
return n * previous;
}
int main(int argc)
{
int answer = factorial(5);
printf("%d\n", answer);
}
Rekursive Fakultät - factial.c
Die Idee, dass sich eine Funktion selbst aufruft, ist zunächst schwer zu verstehen. Um diesen Vorgang anschaulicher und konkreter zu gestalten, zeigt die folgende Abbildung den Endpunkt auf dem Stapel, wenn Factorial(5) aufgerufen wird und die Codezeile n == 1 erreicht wird:

Jedes Mal, wenn die Fakultät aufgerufen wird, wird ein neuer Stapelrahmen generiert. Die Erstellung und Zerstörung dieser Stapelrahmen macht die rekursive Version faktoriell langsamer als die entsprechende iterative Version. Die Anhäufung dieser Stapelrahmen kann den Stapelspeicher erschöpfen, bevor der Aufruf zurückkehrt, was zum Absturz Ihres Programms führt.
Und diese Sorgen bestehen oft in der Theorie. Der Stapelrahmen benötigt beispielsweise 16 Byte für jede Fakultät (dies kann von der Stapelanordnung und anderen Faktoren abhängen). Wenn Sie einen modernen x86-Linux-Kernel auf Ihrem Computer ausführen, verfügen Sie normalerweise über 8 GB Stapelspeicher, sodass n in einem Faktorprogramm bis zu etwa 512.000 betragen kann. Das ist ein riesiges Ergebnis, und es benötigt 8.971.833 Bits, um es darzustellen, sodass der Stapelspeicherplatz überhaupt kein Problem darstellt: Eine winzige Ganzzahl – sogar eine 64-Bit-Ganzzahl – wird in unserem Stapelspeicher gespeichert. Sie ist schon tausende Male übergelaufen es ist ausgegangen.
Wir werden uns gleich mit der CPU-Nutzung befassen. Lassen Sie uns zunächst einen Schritt von Bits und Bytes zurücktreten und die Rekursion als allgemeine Technologie betrachten. Unser faktorieller Algorithmus läuft darauf hinaus, die ganzen Zahlen N, N-1, … 1 auf einen Stapel zu legen und sie in umgekehrter Reihenfolge zu multiplizieren. Um dies zu erreichen, verwenden wir tatsächlich einen Programmaufrufstapel. Hier sind die Details: Wir weisen einen Stapel auf dem Heap zu und verwenden ihn. Obwohl der Aufrufstapel besondere Eigenschaften aufweist, handelt es sich lediglich um eine weitere Datenstruktur, die Sie nach Belieben verwenden können. Ich hoffe, dieses Diagramm hilft Ihnen, dies zu verstehen.
Wenn Sie sich den Aufrufstapel als Datenstruktur vorstellen, wird etwas klarer: Es ist keine gute Idee, diese ganzen Zahlen anzuhäufen und sie dann zu multiplizieren. Das ist eine fehlerhafte Umsetzung: Es ist, als würde man mit einem Schraubenzieher einen Nagel einschlagen. Es ist sinnvoller, einen iterativen Prozess zur Berechnung der Fakultät zu verwenden.
Allerdings gibt es so viele Schrauben, dass wir uns nur für eine entscheiden können. Es gibt eine klassische Interviewfrage, bei der sich eine Maus in einem Labyrinth befindet und man der Maus helfen muss, ein Stück Käse zu finden. Angenommen, eine Ratte kann sich in einem Labyrinth nach links oder rechts drehen. Wie modellieren Sie, um dieses Problem zu lösen?
Wie viele Probleme im wirklichen Leben können Sie dieses Problem, bei dem Mäuse nach Käse suchen, in einem Diagramm vereinfachen, wobei jeder Knoten eines Binärbaums eine Position im Labyrinth darstellt. Sie können die Maus dann nach Möglichkeit nach links drehen lassen, und wenn sie eine Sackgasse erreicht, zurückgehen und wieder nach rechts abbiegen. Dies ist ein Beispiel für eine Maus, die durch ein Labyrinth läuft:
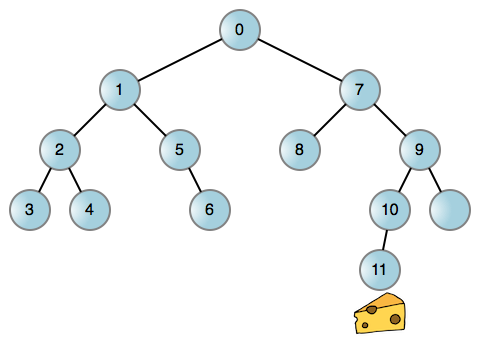
Jedes Mal, wenn die Kante (Linie) erreicht wird, lassen Sie die Maus nach links oder rechts drehen, um eine neue Position zu erreichen. Wenn Sie in irgendeiner Richtung, in die Sie sich drehen, blockiert sind, bedeutet das, dass die entsprechende Kante nicht existiert. Jetzt lasst uns darüber diskutieren! Dieser Prozess ist unabhängig davon, ob Sie einen Aufrufstapel oder andere Datenstrukturen verwenden, untrennbar mit einem rekursiven Prozess verbunden. Und die Verwendung des Call Stacks ist ganz einfach:
#include
#include "maze.h"
int explore(maze_t *node)
{
int found = 0;
if (node == NULL)
{
return 0;
}
if (node->hasCheese){
return 1;// found cheese
}
found = explore(node->left) || explore(node->right);
return found;
}
int main(int argc)
{
int found = explore(&maze);
}
Rekursive Labyrinthlösung herunterladen
Wenn wir Käse in maze.c:13 finden, sieht der Stapel so aus. Detailliertere Daten können Sie auch in der GDB-Ausgabe sehen, bei der es sich um die mit dem Befehl erfassten Daten handelt.

Es zeigt das gute Verhalten der Rekursion, da dies ein Problem ist, das für die Verwendung der Rekursion geeignet ist. Und es ist keine Überraschung: Bei Algorithmen ist Rekursion die Regel und nicht die Ausnahme. Es erscheint, wenn Sie suchen, wenn Sie Bäume und andere Datenstrukturen durchqueren, wenn Sie Parsing durchführen, wenn Sie sortieren müssen – es ist überall. So wie pi oder e in der Mathematik als „Götter“ bekannt sind, weil sie die Grundlage für alles im Universum sind, ist die Rekursion dasselbe: Sie existiert lediglich in der Struktur von Berechnungen.
Das Schöne an Steven Skiennas ausgezeichnetem Buch A Guide to Algorithm Design ist, dass er seine Arbeit anhand von „Kriegsgeschichten“ erklärt, um die Algorithmen zu demonstrieren, die hinter der Lösung realer Probleme stehen. Dies ist die beste Ressource, die ich kenne, um Ihr Wissen über Algorithmen zu erweitern. Eine weitere Lektüre ist McCarthys Originalpapier zur LISP-Implementierung. Rekursion ist sowohl ihr Name als auch ihr Grundprinzip in der Sprache. Der Aufsatz ist sowohl lesbar als auch interessant und es ist spannend, die Arbeit eines Meisters bei der Arbeit zu beobachten.
Zurück zum Labyrinthproblem. Obwohl es hier schwierig ist, die Rekursion zu verlassen, bedeutet dies nicht, dass sie über den Aufrufstapel erreicht werden muss. Sie können eine Zeichenfolge wie RRLL verwenden, um die Drehung zu verfolgen, und diese Zeichenfolge dann verwenden, um die nächste Bewegung der Maus zu bestimmen. Oder Sie können etwas anderes zuweisen, um den gesamten Status der Käsesuche aufzuzeichnen. Sie implementieren immer noch einen rekursiven Prozess, Sie müssen lediglich Ihre eigene Datenstruktur implementieren.
Das erscheint komplizierter, da Stack-Aufrufe besser geeignet sind. Jeder Stapelrahmen zeichnet nicht nur den aktuellen Knoten auf, sondern auch den Status der Berechnung auf diesem Knoten (in diesem Fall, ob wir ihn nur nach links gehen lassen oder versucht haben, nach rechts zu gehen). Daher ist der Code unwichtig geworden. Manchmal geben wir diesen hervorragenden Algorithmus jedoch aus Angst vor einem Überlauf und der erwarteten Leistung auf. Das ist dumm!
Wie wir sehen können, ist der Stapelplatz sehr groß und es treten häufig andere Einschränkungen auf, bevor der Stapelplatz erschöpft ist. Einerseits können Sie die Größe des Problems überprüfen, um sicherzustellen, dass es sicher behandelt werden kann. Die CPU-Bedenken werden durch zwei weit verbreitete problematische Beispiele ausgelöst: die dumme Fakultät und die schreckliche erinnerungslose O(2n)-Fibonacci-Rekursion. Sie sind keine korrekten Darstellungen von rekursiven Stapelalgorithmen.
Tatsächlich sind Stapeloperationen sehr schnell. Typischerweise ist der Stapelversatz zu den Daten sehr genau, es handelt sich um heiße Daten im Cache und es werden spezielle Anweisungen darauf angewendet. Gleichzeitig ist der Overhead, der mit der Verwendung Ihrer eigenen, auf dem Heap zugewiesenen Datenstrukturen verbunden ist, erheblich. Es ist häufig zu beobachten, dass Menschen Implementierungsmethoden schreiben, die komplexer sind und eine schlechtere Leistung aufweisen als die Rekursion von Stack-Aufrufen. Schließlich ist die Leistung moderner CPUs sehr gut und die CPU stellt im Allgemeinen keinen Leistungsengpass dar. Seien Sie vorsichtig, wenn Sie erwägen, die Einfachheit eines Programms zu opfern, genauso wie Sie immer die Programmleistung und die Messung dieser Leistung berücksichtigen.
Der nächste Artikel wird der letzte in der Exploring Stack-Reihe sein. Wir werden mehr über Tail Calls, Schließungen und andere verwandte Konzepte erfahren. Dann ist es an der Zeit, in unseren alten Freund einzutauchen, den Linux-Kernel. Vielen Dank fürs Lesen!

Das obige ist der detaillierte Inhalt vonRekursive Operationen in der Softwareentwicklung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Das Reinigungsprinzip des Ordners /tmp/ im Linux-System und die Rolle der tmp-Datei
- Detaillierte Erläuterung der Berechnung der spezifischen CPU-Auslastung unter Linux
- So melden Sie sich in Debian 11 ab oder fahren das System herunter
- So ändern Sie den Desktop-Hintergrund in Ubuntu
- Ubuntu 21.04 Beta veröffentlicht, Update-Übersicht