
Heim >Backend-Entwicklung >Python-Tutorial >Durchsuchen von Seiten mit Infinite Scroll mit Scrapy und Playwright
Durchsuchen von Seiten mit Infinite Scroll mit Scrapy und Playwright

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-10 06:58:331665Durchsuche
Beim Crawlen von Websites mit Scrapy werden Sie schnell auf alle möglichen Szenarien stoßen, in denen Sie kreativ werden oder mit der Seite interagieren müssen, die Sie crawlen möchten. Eines dieser Szenarios ist, wenn Sie eine Seite mit unendlichem Bildlauf crawlen müssen. Diese Art von Website-Seite lädt mehr Inhalt, wenn Sie auf der Seite nach unten scrollen, wie bei einem Social-Media-Feed.
Es gibt definitiv mehr als eine Möglichkeit, diese Art von Seiten zu crawlen. Eine Möglichkeit, die ich kürzlich angegangen bin, bestand darin, so lange weiterzuscrollen, bis die Seitenlänge nicht mehr zunahm (d. h. nach unten scrollen). Dieser Beitrag führt Sie Schritt für Schritt durch diesen Prozess.
In diesem Beitrag wird davon ausgegangen, dass Sie ein Scrapy-Projekt eingerichtet haben, das ausgeführt wird, und einen Spider, den Sie ändern und ausführen können.
Verwendung von Playwright mit Scrapy
Diese Integration verwendet das Scrapy-Playwright-Plugin, um Playwright für Python mit Scrapy zu integrieren. Playwright ist eine Headless-Browser-Automatisierungsbibliothek, die zur Interaktion mit Webseiten und zum Extrahieren von Daten verwendet wird.
Ich habe uv für die Installation und Verwaltung von Python-Paketen verwendet.
Dann verwende ich virtuelle Umgebungen direkt von UV mit:
uv venv source .venv/bin/activate
Installieren Sie das Scrapy-Playwright-Plugin und Playwright mit dem folgenden Befehl in Ihrer virtuellen Umgebung:
uv pip install scrapy-playwright
Installieren Sie den Browser, den Sie mit Playwright verwenden möchten. Um beispielsweise Chromium zu installieren, können Sie den folgenden Befehl ausführen:
playwright install chromium
Bei Bedarf können Sie auch andere Browser wie Firefox installieren.
Hinweis: Der untenstehende Scrapy-Code und die Playwright-Integration wurden nur mit Chromium getestet.
Aktualisieren Sie die Datei „settings.py“ oder das Attribut „custom_settings“ im Spider, um die Einstellungen DOWNLOAD_HANDLERS und PLAYWRIGHT_LAUNCH_OPTIONS einzuschließen.
# settings.py
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_LAUNCH_OPTIONS = {
# optional for CORS issues
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
# optional for debugging
"headless": False,
},
Für PLAYWRIGHT_LAUNCH_OPTIONS können Sie die Headless-Option auf False setzen, um die Browserinstanz zu öffnen und die Ausführung des Prozesses zu beobachten. Dies ist gut zum Debuggen und Erstellen des anfänglichen Scrapers.
Umgang mit CORS-Problemen
Ich übergebe die zusätzlichen Argumente, um die Websicherheit zu deaktivieren und Ursprünge zu isolieren. Dies ist nützlich, wenn Sie Websites crawlen, die CORS-Probleme haben.
Zum Beispiel kann es Situationen geben, in denen erforderliche JavaScript-Assets aufgrund von CORS nicht geladen werden oder Netzwerkanfragen nicht gestellt werden. Sie können dies schneller isolieren, indem Sie die Browserkonsole auf Fehler überprüfen, wenn bestimmte Seitenaktionen (z. B. das Klicken auf eine Schaltfläche) nicht wie erwartet funktionieren, alles andere jedoch.
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
}
Crawlen von Seiten mit unendlichem Scrollen
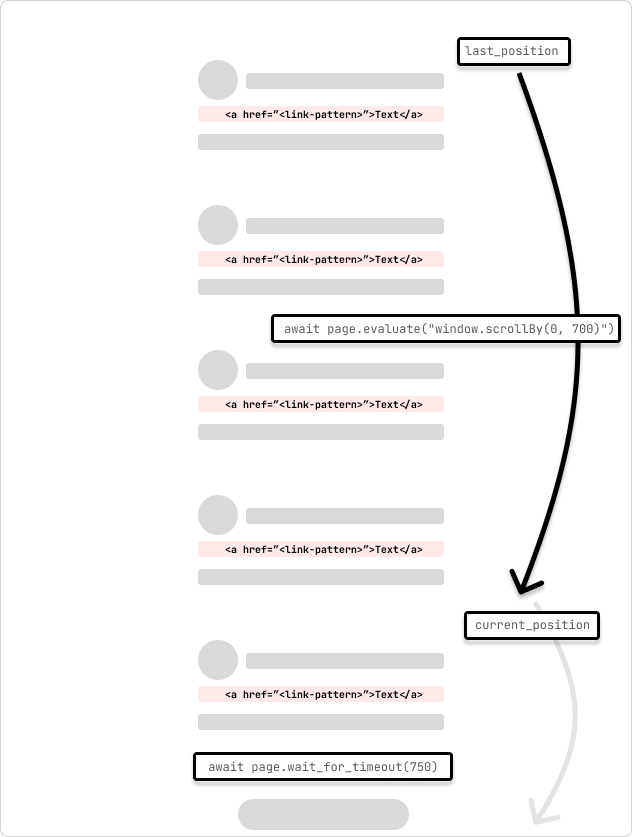
Dies ist ein Beispiel für eine Spinne, die eine unendliche Bildlaufseite crawlt. Der Spider scrollt die Seite um 700 Pixel und wartet 750 ms auf den Abschluss der Anfrage. Die Spinne scrollt weiter, bis sie das Ende der Seite erreicht, was dadurch angezeigt wird, dass sich die Scrollposition beim Durchlaufen der Schleife nicht ändert.
Ich ändere die Einstellungen im Spider selbst mithilfe von „custom_settings“, um die Einstellungen an einem Ort zu behalten. Sie können diese Einstellungen auch zur Datei „settings.py“ hinzufügen.
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
class InfinitePageSpider(CrawlSpider):
"""
Spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
"DOWNLOAD_HANDLERS": {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
},
"LOG_LEVEL": "INFO",
}
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrollY")
while True:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollBy(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrollY")
if current_position == last_position:
print("Reached the bottom of the page.")
break
last_position = current_position
except Exception as error:
print(f"Error: {error}")
pass
print("Getting content")
content = await page.content()
print("Parsing content")
selector = Selector(text=content)
print("Extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"Found {len(links)} links...")
print("Yielding links")
for link in links:
yield {"link": link}
Eine Sache, die ich gelernt habe, ist, dass keine zwei Seiten oder Websites gleich sind. Daher müssen Sie möglicherweise die Scrollmenge und die Wartezeit anpassen, um die Seite und auch etwaige Latenzen in den Netzwerk-Roundtrips für die Anfragen zu berücksichtigen vollständig. Sie können dies programmgesteuert dynamisch anpassen, indem Sie die Bildlaufposition und die Zeit überprüfen, die für den Abschluss der Anfrage benötigt wird.
Beim Laden der Seite warte ich etwas länger darauf, dass die Assets geladen und die Seite gerendert wird. Die Playwright-Seite wird an die Parse-Callback-Methode im Response.meta-Objekt übergeben. Dies wird verwendet, um mit der Seite zu interagieren und auf der Seite zu scrollen. Dies wird in den scrapy.Request-Argumenten mit den Optionen playwright=True und playwright_include_page=True angegeben.
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
Dieser Spider scrollt die Seite mit page.evaluate und der JavaScript-Methode scrollBy() um 700 Pixel und wartet dann 750 ms, bis die Anfrage abgeschlossen ist. Anschließend wird der Inhalt der Playwright-Seite in einen Scrapy-Selektor kopiert und die Links aus der Seite extrahiert. Die Links werden dann an die Scrapy-Pipeline übergeben, um die Verarbeitung fortzusetzen.
In Situationen, in denen die Seitenanfragen beginnen, doppelten Inhalt zu laden, können Sie eine Prüfung hinzufügen, um zu sehen, ob der Inhalt bereits geladen wurde, und dann die Schleife verlassen. Oder, wenn Sie eine Vorstellung von der Anzahl der Scroll-Ladevorgänge haben, können Sie einen Zähler hinzufügen, um nach einer bestimmten Anzahl von Scrolls plus/minus einem Puffer aus der Schleife auszubrechen.
Infinite Scroll with an Element Click
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Wrapping Up
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
Das obige ist der detaillierte Inhalt vonDurchsuchen von Seiten mit Infinite Scroll mit Scrapy und Playwright. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!