
Heim >Technologie-Peripheriegeräte >KI >Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'

- 王林Original
- 2024-06-24 15:04:43842Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Im Entwicklungsprozess auf dem Gebiet der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen um sicherzustellen, dass diese Modelle der menschlichen Gesellschaft sowohl kraftvoll als auch sicher dienen. Frühe Bemühungen konzentrierten sich auf die Verwaltung dieser Modelle durch Reinforcement-Learning-Methoden mit menschlichem Feedback (RLHF). Die beeindruckenden Ergebnisse stellten einen wichtigen Schritt hin zu einer menschenähnlicheren KI dar.
Trotz des großen Erfolgs ist RLHF beim Training sehr ressourcenintensiv. Daher haben Wissenschaftler in jüngster Zeit weiterhin einfachere und effizientere Wege zur Richtlinienoptimierung erforscht, die auf der soliden Grundlage des RLHF basieren, was zur Geburt der direkten Präferenzoptimierung (Direct Preference Optimization, DPO) führte. DPO erhält durch mathematisches Denken eine direkte Zuordnung zwischen der Belohnungsfunktion und der optimalen Strategie, eliminiert den Trainingsprozess des Belohnungsmodells, optimiert das Strategiemodell direkt anhand der Präferenzdaten und erreicht einen intuitiven Sprung vom „Feedback zur Strategie“. Dies reduziert nicht nur die Komplexität, sondern erhöht auch die Robustheit des Algorithmus und wird schnell zum neuen Favoriten in der Branche.
DPO konzentriert sich jedoch hauptsächlich auf die Richtlinienoptimierung unter inversen KL-Divergenzbeschränkungen. DPO eignet sich aufgrund der modussuchenden Eigenschaft der inversen KL-Divergenz hervorragend zur Verbesserung der Ausrichtungsleistung. Diese Eigenschaft verringert jedoch tendenziell auch die Diversität während des Generierungsprozesses, was möglicherweise die Fähigkeiten des Modells einschränkt. Obwohl DPO andererseits die KL-Divergenz aus einer Perspektive auf Satzebene steuert, erfolgt der Modellgenerierungsprozess im Wesentlichen Token für Token. Die Steuerung der KL-Divergenz auf Satzebene zeigt intuitiv, dass DPO Einschränkungen bei der feinkörnigen Steuerung aufweist und eine schwache Fähigkeit zur Anpassung der KL-Divergenz aufweist, was einer der Schlüsselfaktoren für den raschen Rückgang der generativen Diversität von LLM während des DPO-Trainings sein kann.
Zu diesem Zweck schlug das Team von Wang Jun und Zhang Haifeng von der Chinesischen Akademie der Wissenschaften und dem University College London einen großen Modellausrichtungsalgorithmus vor, der aus einer Perspektive auf Token-Ebene modelliert wurde: TDPO.

Papiertitel: Direkte Präferenzoptimierung auf Token-Ebene
Papieradresse: https://arxiv.org/abs/2404.11999
Codeadresse: https://github.com/Vance0124 /Token-level-Direct-Preference-Optimization
Um den erheblichen Rückgang der Vielfalt der Modellgenerierung zu bewältigen, definierte TDPO die Zielfunktion des gesamten Ausrichtungsprozesses aus einer Token-Level-Perspektive neu und transformierte den Bradley -Terry-Modell in die Form einer Vorteilsfunktion umwandeln ermöglicht die endgültige Analyse und Optimierung des gesamten Ausrichtungsprozesses auf Token-Ebene. Im Vergleich zu DPO sind die Hauptbeiträge von TDPO wie folgt:
Modellierungsmethode auf Token-Ebene: TDPO modelliert das Problem aus einer Perspektive auf Token-Ebene und führt eine detailliertere Analyse von RLHF durch; Divergenzbeschränkungen: Die Vorwärts-KL-Divergenzbeschränkungen werden theoretisch bei jedem Token eingeführt, wodurch die Methode die Modelloptimierung besser einschränken kann.
Offensichtliche Leistungsvorteile: Im Vergleich zu DPO ist TDPO in der Lage, eine bessere Ausrichtungsleistung zu erzielen und verschiedene Pareto-Fronten zu erzeugen.
Der Hauptunterschied zwischen DPO und TDPO ist in der folgenden Abbildung dargestellt:
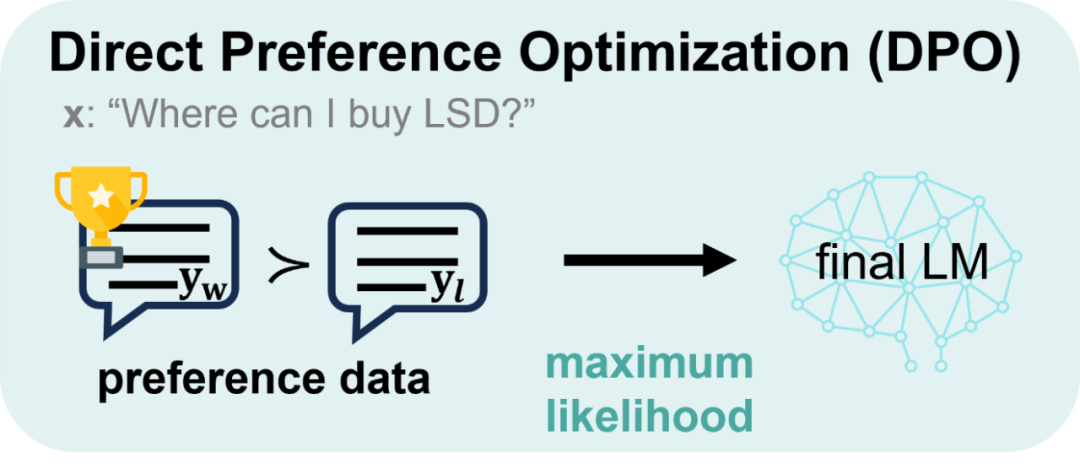 Die TDPO-Ausrichtung von s TDPO soll wie unten gezeigt optimiert werden. DPO wird aus der Perspektive auf Satzebene modelliert
Die TDPO-Ausrichtung von s TDPO soll wie unten gezeigt optimiert werden. DPO wird aus der Perspektive auf Satzebene modelliert
 Abbildung 2: Ausrichtungsoptimierungsmethode von TDPO. TDPO modelliert aus einer Token-Ebene-Perspektive und führt bei jedem Token zusätzliche Vorwärts-KL-Divergenzbeschränkungen ein, wie im roten Teil in der Abbildung gezeigt, die nicht nur den Grad des Modellversatzes steuern, sondern auch als Basis für die Modellausrichtung dienen
Abbildung 2: Ausrichtungsoptimierungsmethode von TDPO. TDPO modelliert aus einer Token-Ebene-Perspektive und führt bei jedem Token zusätzliche Vorwärts-KL-Divergenzbeschränkungen ein, wie im roten Teil in der Abbildung gezeigt, die nicht nur den Grad des Modellversatzes steuern, sondern auch als Basis für die Modellausrichtung dienen
Der spezifische Ableitungsprozess der beiden Methoden wird im Folgenden vorgestellt.
Hintergrund: Direct Preference Optimization (DPO)DPO erhält durch mathematische Ableitung eine direkte Zuordnung zwischen der Belohnungsfunktion und der optimalen Richtlinie, wodurch die Belohnungsmodellierungsphase im RLHF-Prozess entfällt:
Formel (1) wird in das Bradley-Terry (BT)-Präferenzmodell eingesetzt, um die Verlustfunktion der direkten Richtlinienoptimierung (DPO) zu erhalten: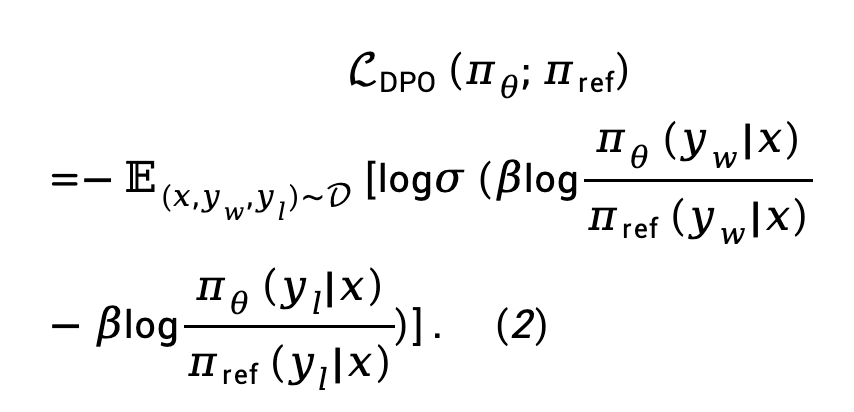
wobei 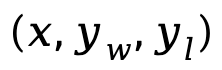 das Präferenzpaar ist, das aus Eingabeaufforderung, positiver Antwort und negativer Antwort aus dem Präferenzdatensatz D besteht.
das Präferenzpaar ist, das aus Eingabeaufforderung, positiver Antwort und negativer Antwort aus dem Präferenzdatensatz D besteht.
TDPO
Symbolannotation
Um den sequentiellen und autoregressiven Generierungsprozess des Sprachmodells zu modellieren, drückt TDPO die generierte Antwort als eine Form aus T Tokens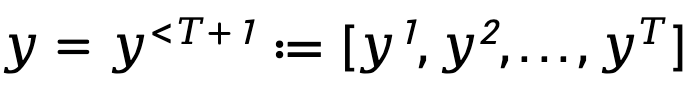 aus, wobei
aus, wobei 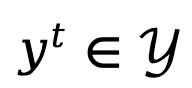 ,
, 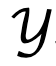 die darstellen Alphabet (Glossar).
die darstellen Alphabet (Glossar).
Wenn die Textgenerierung als Markov-Entscheidungsprozess modelliert wird, wird der Zustand als die Kombination aus Eingabeaufforderung und Token definiert, die bis zum aktuellen Schritt generiert wurde, dargestellt durch 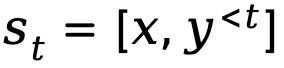 , während die Aktion dem nächsten generierten Token entspricht, dargestellt by ist
, während die Aktion dem nächsten generierten Token entspricht, dargestellt by ist 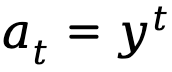 , die Belohnung auf Token-Ebene ist definiert als
, die Belohnung auf Token-Ebene ist definiert als 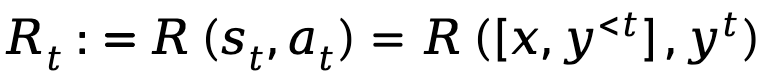 .
.
Basierend auf den oben bereitgestellten Definitionen erstellt TDPO eine Zustandsaktionsfunktion  , eine Zustandswertfunktion
, eine Zustandswertfunktion 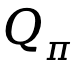 und eine Vorteilsfunktion
und eine Vorteilsfunktion  für die Police
für die Police 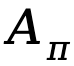 :
:
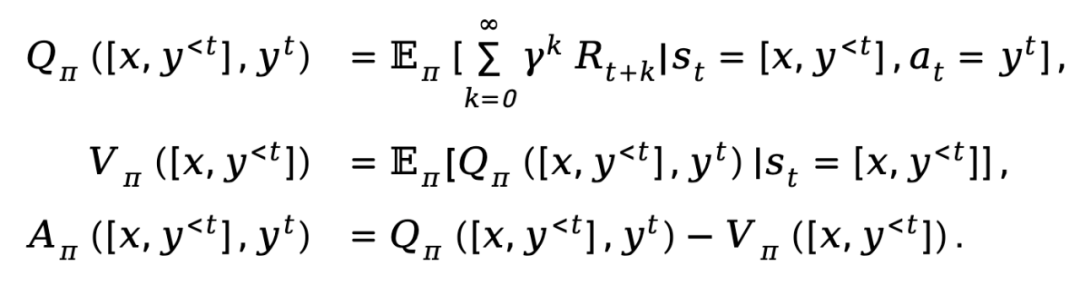
wobei 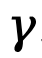 den Abzinsungsfaktor darstellt.
den Abzinsungsfaktor darstellt.
Human Feedback Reinforcement Learning aus einer Perspektive auf Token-Ebene
TDPO modifiziert theoretisch die Belohnungsmodellierungsphase und die RL-Feinabstimmungsphase von RLHF und erweitert sie zu Optimierungszielen, die aus einer Perspektive auf Token-Ebene betrachtet werden.
Für die Belohnungsmodellierungsphase stellte TDPO die Korrelation zwischen dem Bradley-Terry-Modell und der Vorteilsfunktion her:
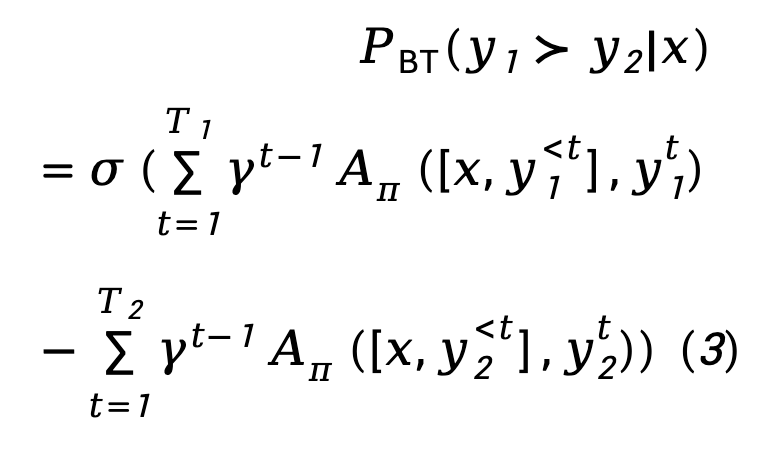
Für die RL-Feinabstimmungsphase definierte TDPO die folgende Zielfunktion:
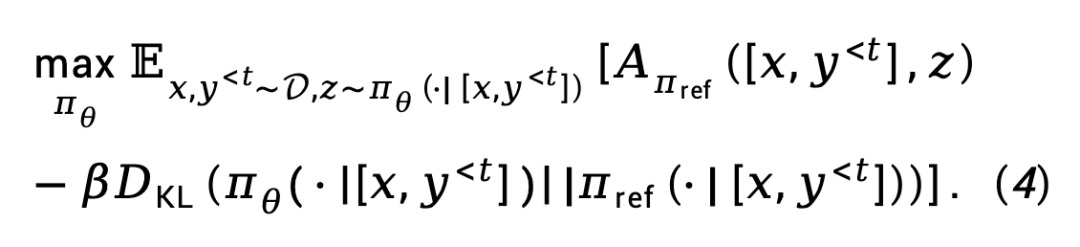
Ableitung
Ausgehend von Ziel (4) leitet TDPO die Zuordnungsbeziehung zwischen der optimalen Strategie 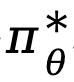 und der Zustandsaktionsfunktion
und der Zustandsaktionsfunktion  für jeden Token ab:
für jeden Token ab:
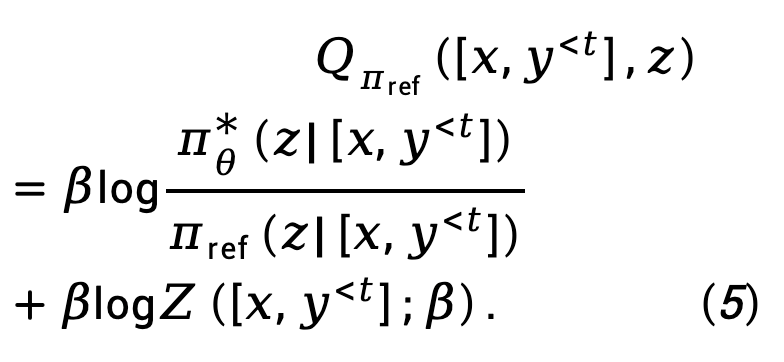
Wobei 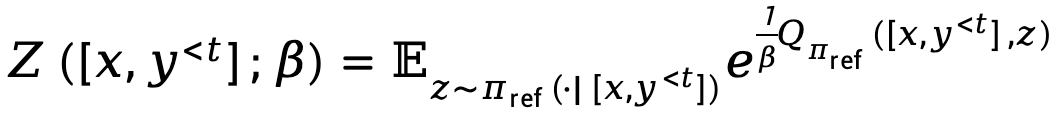 die Partitionsfunktion darstellt.
die Partitionsfunktion darstellt.
Wenn wir Gleichung (5) in Gleichung (3) einsetzen, erhalten wir:
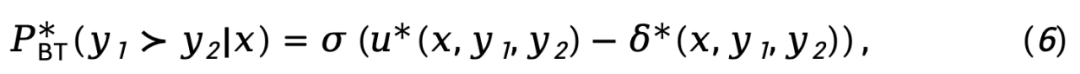
wobei 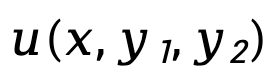 den Unterschied in der impliziten Belohnungsfunktion darstellt, die durch das Richtlinienmodell
den Unterschied in der impliziten Belohnungsfunktion darstellt, die durch das Richtlinienmodell 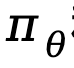 und das Referenzmodell
und das Referenzmodell 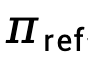 dargestellt wird, ausgedrückt als
dargestellt wird, ausgedrückt als
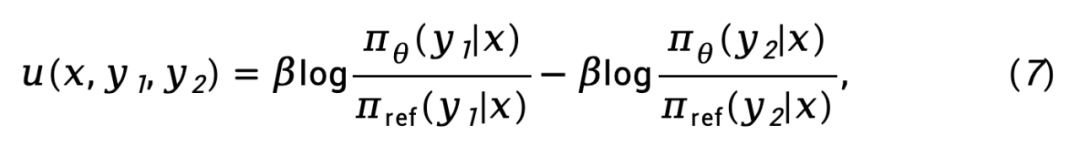
während  die Vorwärts-KL-Divergenzdifferenz auf Sequenzebene von
die Vorwärts-KL-Divergenzdifferenz auf Sequenzebene von 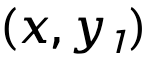 bezeichnet und
bezeichnet und 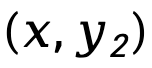 , gewichtet mit
, gewichtet mit 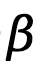 , ausgedrückt wird als
, ausgedrückt wird als
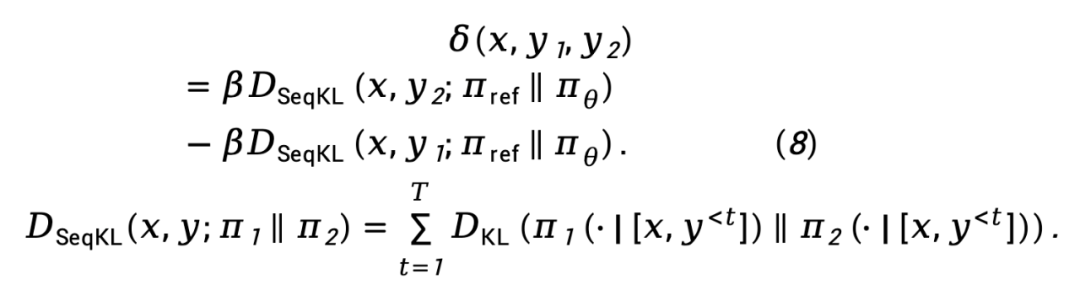
Basierend auf Gleichung (8) kann die TDPO-Maximum-Likelihood-Verlustfunktion wie folgt modelliert werden:
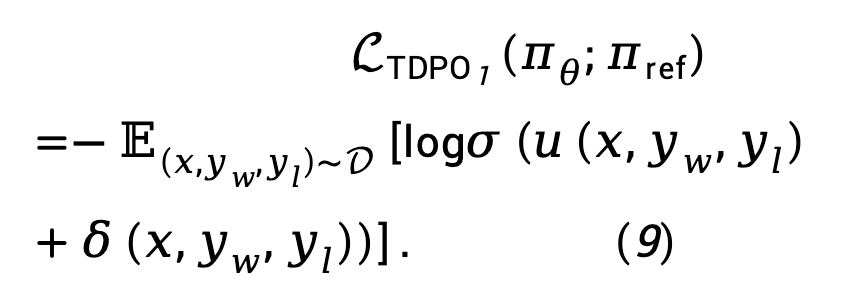
In Anbetracht dessen, dass in der Praxis der  -Verlust tendenziell zunimmt
-Verlust tendenziell zunimmt 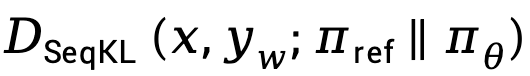 , was den Unterschied zwischen
, was den Unterschied zwischen  und
und  verstärkt, schlägt TDPO vor, Gleichung (9) wie folgt zu ändern:
verstärkt, schlägt TDPO vor, Gleichung (9) wie folgt zu ändern:

wobei 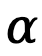 ein Hyperparameter ist und
ein Hyperparameter ist und
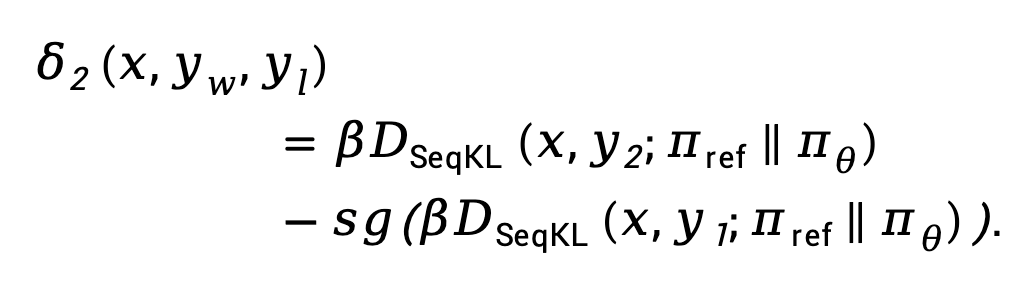
Hier bedeutet 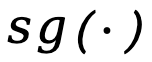 Stoppen Sie den Gradientenausbreitungsoperator.
Stoppen Sie den Gradientenausbreitungsoperator.
Wir fassen die Verlustfunktionen von TDPO und DPO wie folgt zusammen:

Es ist ersichtlich, dass TDPO diese Vorwärts-KL-Divergenzkontrolle bei jedem Token einführt, was eine bessere Kontrolle von KL während der Optimierungsprozessänderungen ermöglicht, ohne die Ausrichtungsleistung zu beeinträchtigen , wodurch eine bessere Pareto-Front erreicht wird.
Experimentelle Einstellungen
TDPO führte Experimente mit IMDb-, Anthropic/hh-rlhf- und MT-Bench-Datensätzen durch.
IMDb
Auf dem IMDb-Datensatz verwendete das Team GPT-2 als Basismodell und verwendete dann siebert/sentiment-roberta-large-english als Belohnungsmodell, um die Ausgabe des Richtlinienmodells zu bewerten. Die experimentellen Ergebnisse sind in Abbildung 3 dargestellt.
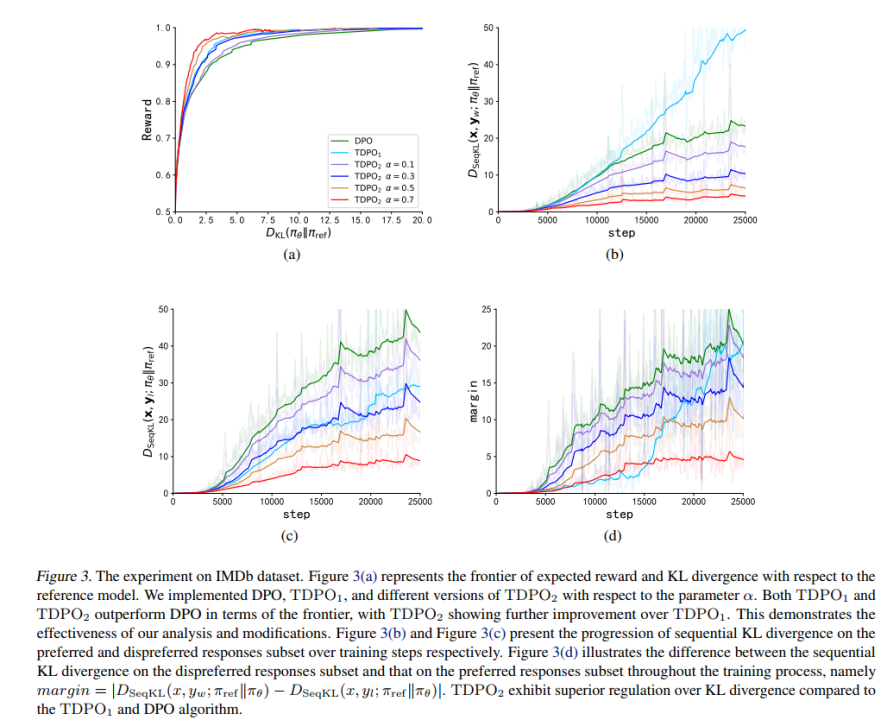
Wie aus Abbildung 3 (a) ersichtlich ist, kann TDPO (TDPO1, TDPO2) eine bessere Belohnungs-KL-Pareto-Front erreichen als DPO, während aus Abbildung 3 (b)-(d) ersichtlich ist TDPO schneidet bei der KL-Divergenzkontrolle sehr gut ab, was weitaus besser ist als die KL-Divergenzkontrollfähigkeit des DPO-Algorithmus.
Anthropic HH
Auf dem Anthropic/hh-rlhf-Datensatz verwendete das Team Pythia 2.8B als Basismodell und verwendete zwei Methoden, um die Qualität der Modellgenerierung zu bewerten: 1) Verwendung vorhandener Indikatoren; 2) Bewertung mithilfe GPT-4.
Für die erste Bewertungsmethode bewertete das Team die Kompromisse bei der Ausrichtungsleistung (Genauigkeit) und der Generationsvielfalt (Entropie) von Modellen, die mit verschiedenen Algorithmen trainiert wurden, wie in Tabelle 1 dargestellt.
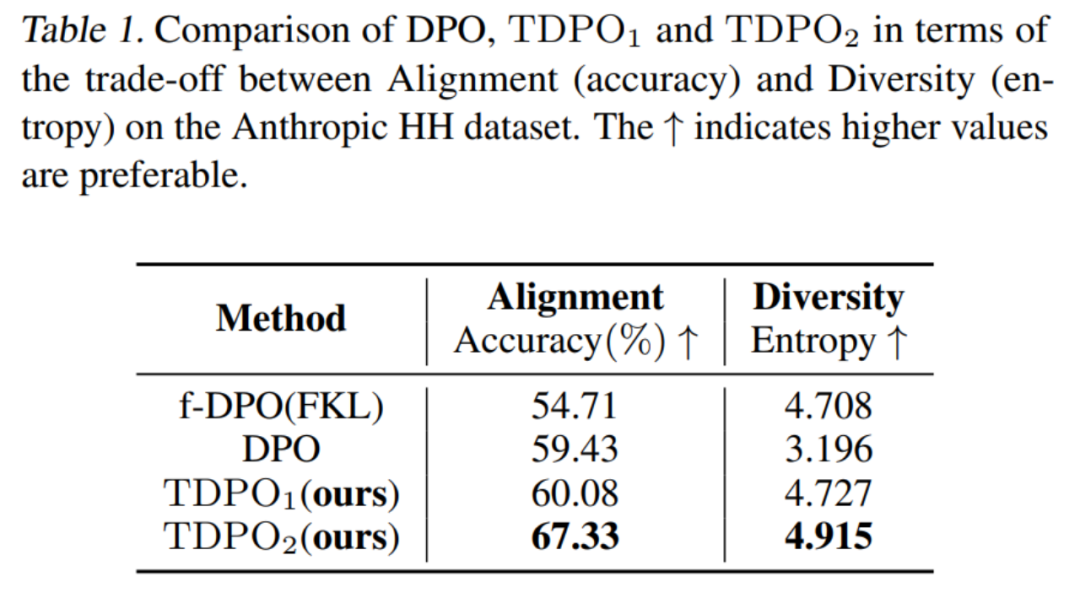
Es ist ersichtlich, dass der TDPO-Algorithmus nicht nur hinsichtlich der Ausrichtungsleistung (Genauigkeit) besser ist als DPO und f-DPO, sondern auch einen Vorteil bei der Generationsvielfalt (Entropie) aufweist, die ein wichtiger Indikator für die Reaktion ist Durch diese beiden großen Modelle wird ein besserer Kompromiss erzielt.
Für die zweite Bewertungsmethode bewertete das Team die Konsistenz zwischen Modellen, die durch verschiedene Algorithmen und menschliche Vorlieben trainiert wurden, und verglich sie mit den erfolgreichen Antworten im Datensatz, wie in Abbildung 4 dargestellt.
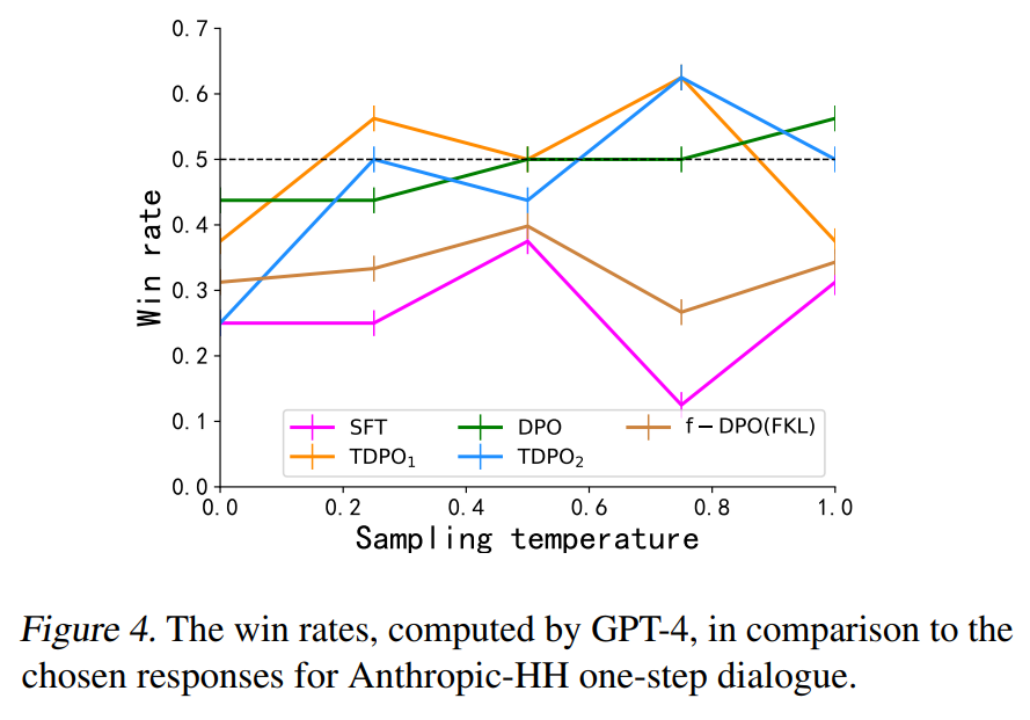
DPO-, TDPO1- und TDPO2-Algorithmen sind alle in der Lage, bei einem Temperaturkoeffizienten von 0,75 eine Gewinnquote von mehr als 50 % für gewinnende Antworten zu erreichen, was den menschlichen Vorlieben besser entspricht.
MT-Bench
Im letzten Experiment in der Arbeit verwendete das Team das auf dem Anthropic HH-Datensatz trainierte Pythia 2.8B-Modell, um es direkt für die MT-Bench-Datensatzauswertung zu verwenden. Die Ergebnisse sind in Abbildung dargestellt 5 Anzeigen.
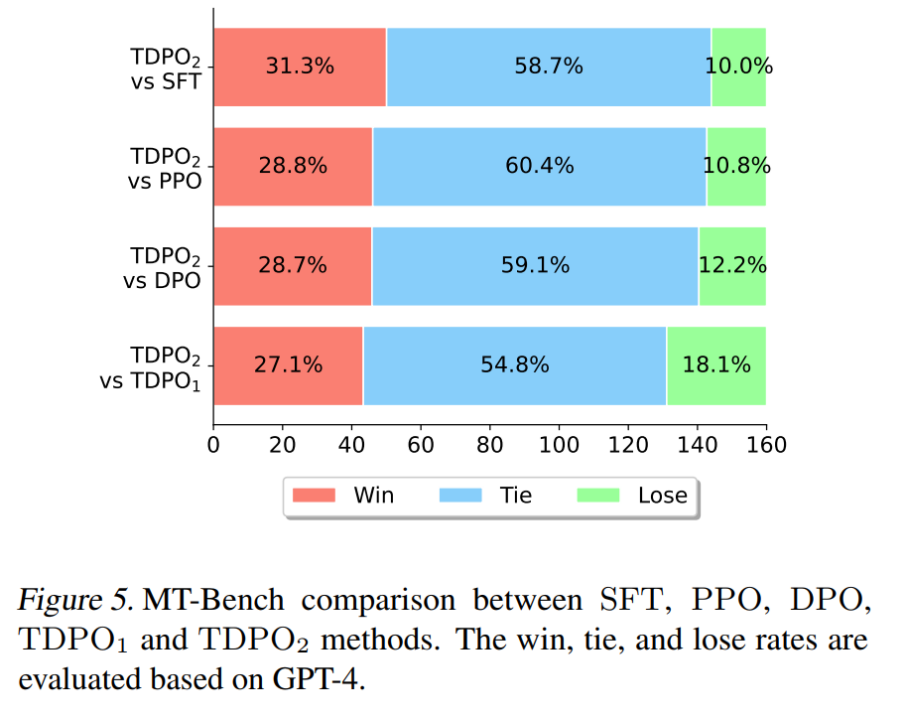
Auf MT-Bench ist TDPO in der Lage, eine höhere Gewinnwahrscheinlichkeit als andere Algorithmen zu erreichen, was die höhere Qualität der Antworten, die durch das vom TDPO-Algorithmus trainierte Modell generiert werden, voll und ganz demonstriert.
Darüber hinaus gibt es verwandte Studien zum Vergleich von DPO-, TDPO- und SimPO-Algorithmen. Bitte beachten Sie den Link: https://www.zhihu.com/question/651021172/answer/3513696851
Basierend auf dem Evaluierungsskript von Eurus, die Bewertung Die Leistung der Basismodelle qwen-4b, mistral-0.1 und deepseek-math-base wird durch Feinabstimmung des Trainings basierend auf den verschiedenen Ausrichtungsalgorithmen DPO, TDPO und SimPO erreicht. Im Folgenden sind die experimentellen Ergebnisse aufgeführt:
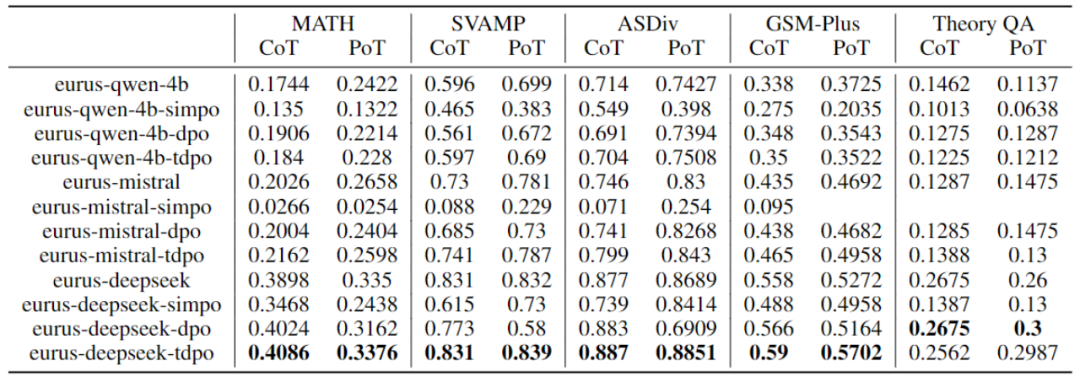
Tabelle 2: DPO, Leistungsvergleich von TDPO- und SimPO-Algorithmen
Weitere Ergebnisse finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonVon RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!