Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail-Adresse der Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Diese Studie bewertet das Multi-Sample-Kontextlernen eines erweiterten multimodalen Basismodells anhand von 10 Datensätzen und zeigt nachhaltige Leistungsverbesserungen auf. Batch-Abfragen reduzieren die Latenz pro Beispiel und die Inferenzkosten erheblich, ohne die Leistung zu beeinträchtigen. Diese Ergebnisse zeigen, dass: Die Nutzung einer großen Anzahl von Demobeispielen eine schnelle Anpassung an neue Aufgaben und Domänen ohne herkömmliche Feinabstimmung ermöglicht. 
- Papieradresse: https://arxiv.org/abs/2405.09798
- Codeadresse: https://github.com/stanfordmlgroup/ManyICL
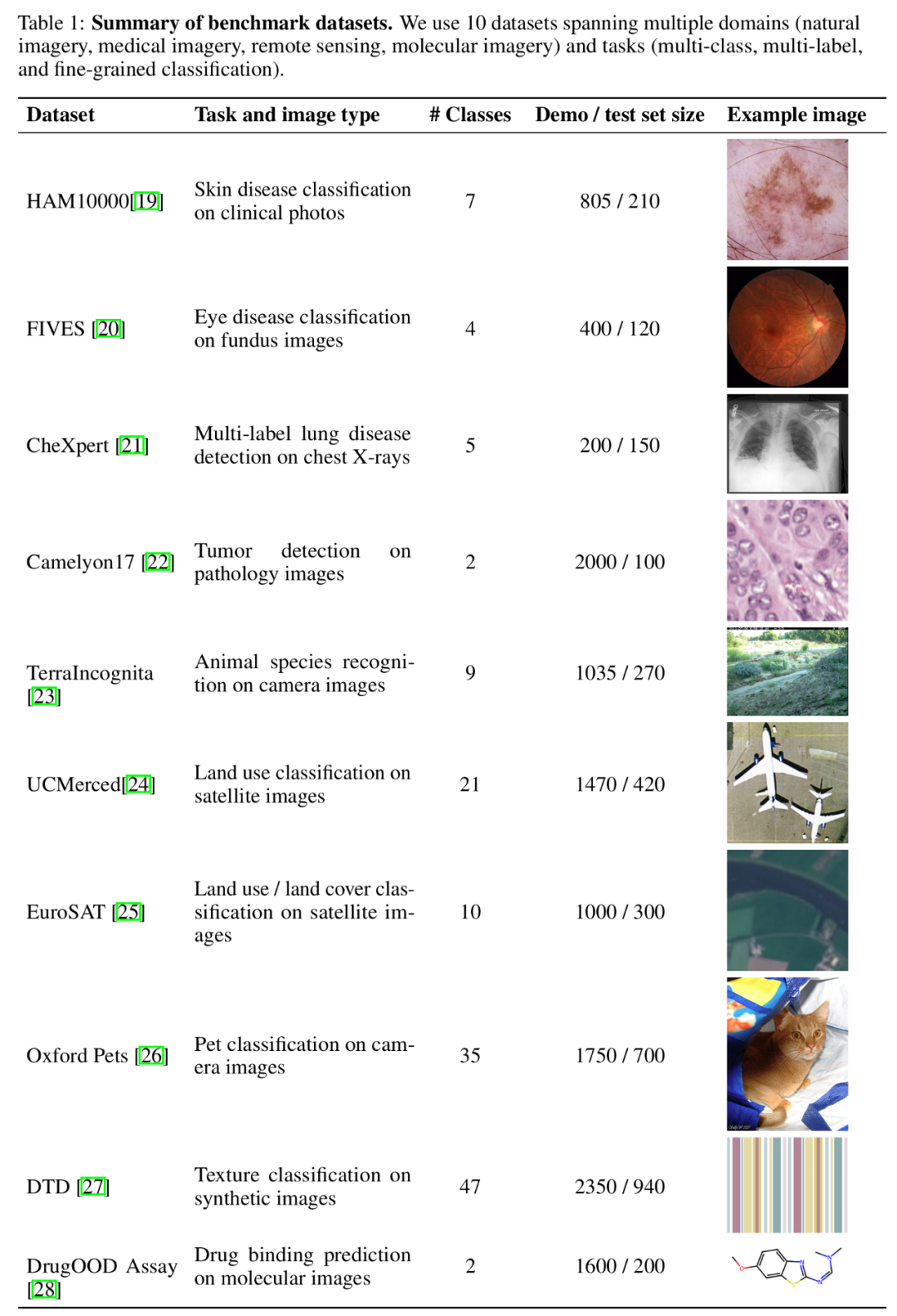
In aktuellen Untersuchungen zum Multimodal Foundation Model hat sich In-Context Learning (ICL) als eine der effektivsten Methoden zur Verbesserung der Modellleistung erwiesen. Begrenzt durch die Kontextlänge des Basismodells, insbesondere bei multimodalen Basismodellen, die eine große Anzahl visueller Token zur Darstellung von Bildern erfordern, ist die vorhandene verwandte Forschung jedoch nur auf die Bereitstellung einer kleinen Anzahl von Beispielen beschränkt der Kontext. Aufregenderweise haben die jüngsten technologischen Fortschritte die Kontextlänge von Modellen erheblich erhöht, was die Möglichkeit eröffnet, Kontextlernen anhand weiterer Beispiele zu untersuchen. Auf dieser Grundlage bewertet die neueste Forschung des Stanford Ng-Teams – ManyICL – hauptsächlich das aktuelle hochmoderne multimodale Grundmodell im Kontextlernen aus wenigen Stichproben (weniger als 100) bis hin zu mehreren Proben (bis 2000) Leistung in . Durch das Testen von Datensätzen aus mehreren Domänen und Aufgaben verifizierte das Team die signifikante Wirkung des Multi-Sample-Kontextlernens auf die Verbesserung der Modellleistung und untersuchte die Auswirkungen von Batch-Abfragen auf Leistung, Kosten und Latenz. Vergleich von Many-Shot-ICL und Zero-Sample-Wenige-Sample-ICL. Für diese Studie wurden drei fortschrittliche multimodale Basismodelle ausgewählt: GPT-4o, GPT4 (V)-Turbo und Gemini 1.5 Pro. Aufgrund der überlegenen Leistung von GPT-4o konzentriert sich das Forschungsteam im Haupttext auf GPT-4o und Gemini 1.5 Pro. Bitte sehen Sie sich den relevanten Inhalt von GPT4 (V)-Turbo im Anhang an. In Bezug auf Datensätze führte das Forschungsteam Experimente mit 10 Datensätzen durch, die sich über verschiedene Bereiche (einschließlich natürlicher Bildgebung, medizinischer Bildgebung, Fernerkundungsbildgebung und molekularer Bildgebung usw.) und Aufgaben (einschließlich Mehrfachklassifizierung, Mehrfachmarkierungsklassifizierung) erstreckten und feinkörnige Klassifizierung) Umfangreiche Experimente.
Zusammenfassung des Benchmark-Datensatzes.
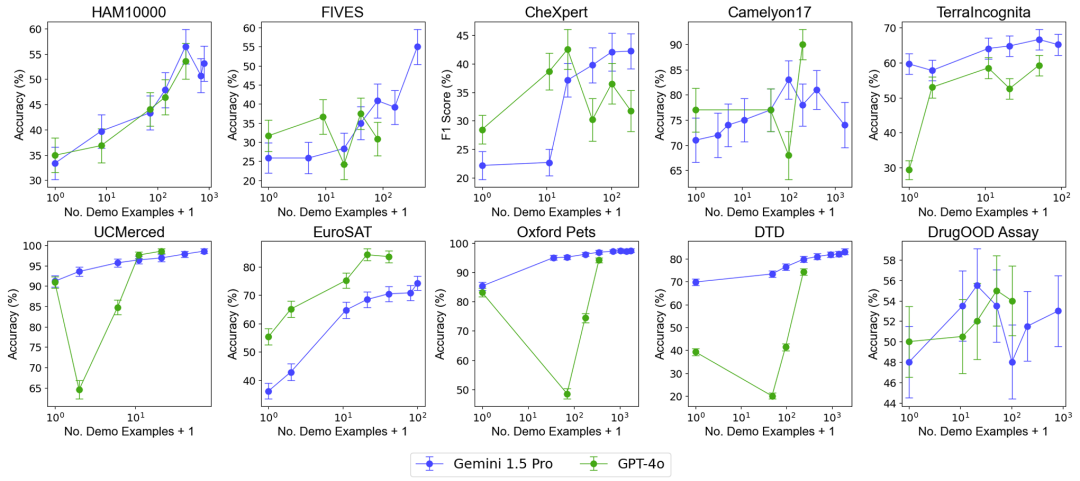
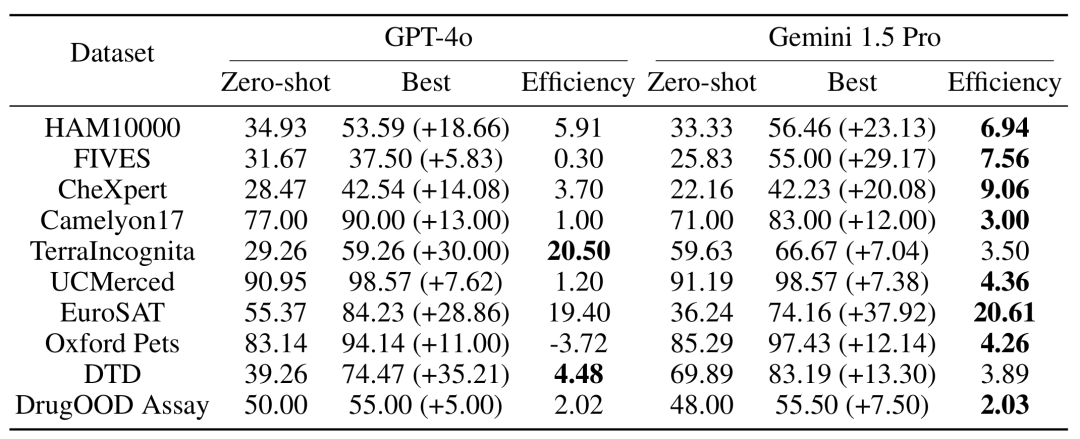
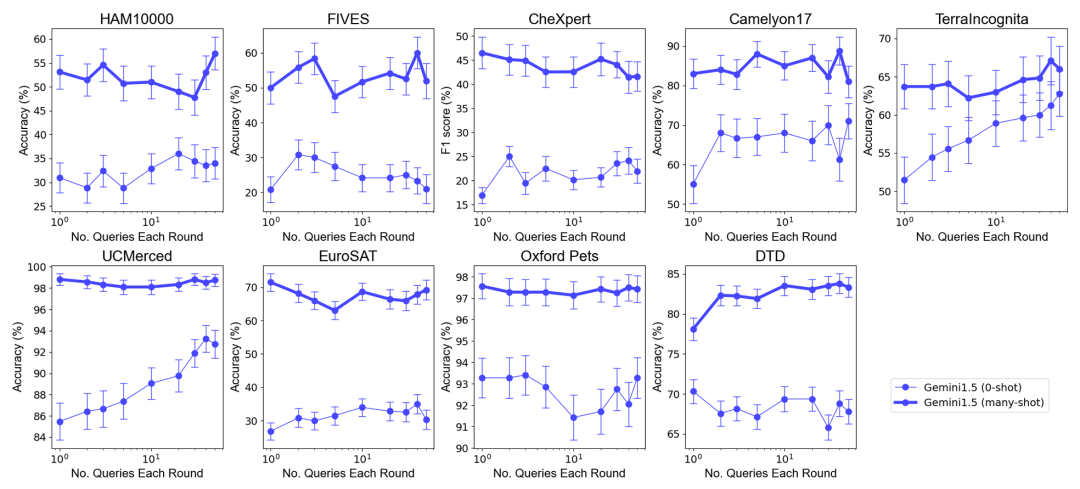
Um die Auswirkungen einer Erhöhung der Anzahl von Beispielen auf die Modellleistung zu testen, erhöhte das Forschungsteam schrittweise die Anzahl der im Kontext bereitgestellten Beispiele auf fast 2.000 Beispiele. Gleichzeitig untersuchte das Forschungsteam angesichts der hohen Kosten und der hohen Latenz des Lernens mit mehreren Stichproben auch die Auswirkungen der Stapelverarbeitung von Abfragen. Hier bezieht sich die Batch-Abfrage auf die Verarbeitung mehrerer Abfragen in einem einzigen API-Aufruf. Experimentelle Ergebnisse Lernen mit wenigen Schüssen . Die Leistung des Gemini 1.5 Pro-Modells zeigt eine konsistente logarithmisch lineare Verbesserung mit zunehmender Anzahl von Beispielen, während die Leistung von GPT-4o weniger stabil ist. Dateneffizienz: Die Studie hat die kontextbezogene Lerndateneffizienz des Modells gemessen, also wie schnell das Modell aus Beispielen lernt. Die Ergebnisse zeigen, dass Gemini 1.5 Pro bei den meisten Datensätzen eine höhere Effizienz beim Kontextlernen von Daten aufweist als GPT-4o, was bedeutet, dass es effektiver aus Beispielen lernen kann. Auswirkung von Batch-Abfragen Es ist erwähnenswert, dass im Zero-Shot-Szenario eine einzelne Abfrage bei vielen Datensätzen eine schlechte Leistung erbringt. Im Gegensatz dazu können Batch-Abfragen sogar die Leistung verbessern. Leistungsverbesserung im Null-Stichproben-Szenario: Bei einigen Datensätzen (z. B. UCMerced) verbessert die Batch-Abfrage die Leistung im Null-Stichproben-Szenario erheblich. Das Forschungsteam analysierte, dass dies hauptsächlich auf Domänenkalibrierung, Klassenkalibrierung und Selbstlernen (Selbst-ICL) zurückzuführen ist. Kosten- und Latenzanalyse
Multi-Sample-Kontextlernen Obwohl während der Inferenz ein längerer Eingabekontext verarbeitet werden muss, können die Latenz- und Inferenzkosten jedes Beispiels durch Batch-Abfragen erheblich reduziert werden. Beispielsweise sank beim HAM10000-Datensatz bei Verwendung des Gemini 1.5 Pro-Modells für eine Batch-Abfrage mit 350 Beispielen die Latenz von 17,3 Sekunden auf 0,54 Sekunden und die Kosten sanken von 0,842 $ auf 0,0877 $ pro Beispiel.
Fazit
Die Forschungsergebnisse zeigen, dass Multi-Sample-Kontextlernen die Leistung multimodaler Basismodelle erheblich verbessern kann, insbesondere das Gemini 1.5 Pro-Modell zeigt eine kontinuierliche Leistungsverbesserung bei mehreren Datensätzen. Dies ermöglicht eine effektivere Anpassung an neue Aufgaben und Bereiche, ohne dass eine herkömmliche Feinabstimmung erforderlich ist. Zweitens kann die Stapelverarbeitung von Abfragen die Inferenzkosten und die Latenz reduzieren und gleichzeitig eine ähnliche oder sogar bessere Modellleistung erzielen, was großes Potenzial für praktische Anwendungen zeigt.
Generell eröffnet diese Forschung des Teams um Andrew Ng einen neuen Weg für die Anwendung multimodaler Grundmodelle, insbesondere im Hinblick auf eine schnelle Anpassung an neue Aufgaben und Bereiche. Das obige ist der detaillierte Inhalt vonNeue Arbeit von Andrew Ngs Team: multimodales Kontextlernen mit mehreren Stichproben, schnelle Anpassung an neue Aufgaben ohne Feinabstimmung.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn