Auf der gerade zu Ende gegangenen Worldwide Developers Conference kündigte Apple Apple Intelligence an, ein neues personalisiertes Intelligenzsystem, das tief in iOS 18, iPadOS 18 und macOS Sequoia integriert ist.

Apple+ Intelligence besteht aus einer Vielzahl hochintelligenter generativer Modelle, die für die täglichen Aufgaben der Benutzer entwickelt wurden. In Apples gerade aktualisiertem Blog werden zwei der Modelle detailliert beschrieben.
Diese beiden Basismodelle sind Teil der generativen Modellfamilie von Apple und Apple sagt, dass sie in naher Zukunft weitere Informationen über diese Modellfamilie veröffentlichen werden.
In diesem Blog verbringt Apple viel Zeit damit, vorzustellen, wie sie leistungsstarke, schnelle und energieeffiziente Modelle entwickeln; wie man diese Modelle an spezifische Benutzeranforderungen anpasst; um zu helfen und Performance im Hinblick auf Unfallverletzungen zu vermeiden.型 Modellierungsübersicht über Apple-Basismodelle Vorschulung
Basismodelle werden auf dem Axlearn-Framework trainiert. Dies ist ein Open-Source-Projekt von Apple, das 2023 veröffentlicht wurde. Das Framework basiert auf JAX und XLA und ermöglicht Benutzern das effiziente und skalierbare Training von Modellen auf einer Vielzahl von Hardware- und Cloud-Plattformen, einschließlich TPUs und GPUs in der Cloud und vor Ort. Darüber hinaus verwendet Apple Techniken wie Datenparallelität, Tensorparallelität, Sequenzparallelität und FSDP, um das Training entlang mehrerer Dimensionen wie Daten, Modell und Sequenzlänge zu skalieren.
Beim Training seines Basismodells verwendet Apple autorisierte Daten, darunter Daten, die speziell zur Verbesserung bestimmter Funktionen ausgewählt wurden, sowie Daten, die von Apples Webcrawler AppleBot aus dem öffentlichen Netzwerk gesammelt wurden. Herausgeber von Webinhalten können sich dafür entscheiden, dass ihre Webinhalte nicht zum Training von Apple Intelligence verwendet werden, indem sie Datennutzungskontrollen festlegen.
Apple verwendet beim Training seines Basismodells niemals die privaten Daten der Benutzer. Zum Schutz der Privatsphäre verwenden sie Filter, um persönlich identifizierbare Informationen wie Kreditkartennummern zu entfernen, die im Internet öffentlich verfügbar sind. Darüber hinaus filtern sie vulgäre Sprache und andere Inhalte von geringer Qualität heraus, bevor sie in den Trainingsdatensatz gelangen. Zusätzlich zu diesen Filtermaßnahmen führt Apple Datenextraktion und -deduplizierung durch und verwendet modellbasierte Klassifikatoren, um hochwertige Dokumente für das Training zu identifizieren und auszuwählen. Nach dem Training
Apple hat festgestellt, dass die Datenqualität für das Modell von entscheidender Bedeutung ist, und hat daher im Trainingsprozess eine hybride Datenstrategie eingeführt, d. h. manuell annotierte Daten und synthetische Daten. und führte umfassende Datenverwaltungs- und Filterverfahren durch. Apple hat in der Post-Training-Phase zwei neue Algorithmen entwickelt: (1) einen Feinabstimmungsalgorithmus für Ablehnungsstichproben mit einem „Lehrerausschuss“, (2) Verstärkung durch menschliches Feedback mithilfe einer Optimierung der Spiegelabstiegsstrategie und eines Auslassens Advantage Estimator Learning (RLHF)-Algorithmus. Diese beiden Algorithmen verbessern die Qualität der Anweisungsfolge des Modells erheblich. Optimierung
Apple stellt nicht nur die hohe Leistung des generierten Modells selbst sicher, sondern nutzt auch eine Vielzahl innovativer Technologien, um das Modell auf dem Gerät und in der privaten Cloud zu optimieren, um die Geschwindigkeit und Geschwindigkeit zu verbessern Effizienz . Insbesondere haben sie zahlreiche Optimierungen am Argumentationsprozess des Modells vorgenommen, indem sie das erste Token (die Grundeinheit eines einzelnen Zeichens oder Wortes) und nachfolgende Token generiert haben, um eine schnelle Reaktion und einen effizienten Betrieb des Modells sicherzustellen.
Apple verwendet einen Gruppenabfrage-Aufmerksamkeitsmechanismus sowohl im geräteseitigen Modell als auch im Servermodell, um die Effizienz zu verbessern. Um den Speicherbedarf und die Inferenzkosten zu reduzieren, verwenden sie gemeinsame Einbettungstabellen für Eingabe- und Ausgabevokabular, die während der Zuordnung nicht dupliziert werden. Das geräteseitige Modell verfügt über einen Wortschatz von 49.000, während das Servermodell über einen Wortschatz von 100.000 verfügt.
Für die geräteseitige Inferenz verwendet Apple die Low-Bit-Palettierung, eine wichtige Optimierungstechnologie, die die erforderlichen Speicher-, Stromverbrauchs- und Leistungsanforderungen erfüllen kann. Um die Modellqualität aufrechtzuerhalten, hat Apple mithilfe des LoRA-Adapters außerdem ein neues Framework entwickelt, das eine hybride 2-Bit- und 4-Bit-Konfigurationsstrategie – durchschnittlich 3,5 Bit pro Gewicht – kombiniert, um die gleiche Genauigkeit wie das unkomprimierte Modell zu erreichen.
Darüber hinaus verwendete Apple Talaria, ein interaktives Modelllatenz- und Leistungsanalysetool sowie Aktivierungsquantisierung und Einbettungsquantisierung, und entwickelte eine Methode zur Implementierung effizienter Schlüsselwert-Cache-Updates (KV) auf der Neural Engine.
Durch diese Reihe von Optimierungen beträgt die vom Empfang des Aufforderungsworts bis zur Generierung des ersten Tokens benötigte Zeit auf dem iPhone 15 Pro etwa 0,6 Millisekunden. Dies zeigt, dass die Verzögerungszeit sehr kurz ist Das Modell generiert sehr schnell Antworten mit einer Rate von 30 Token pro Sekunde. Modellanpassung
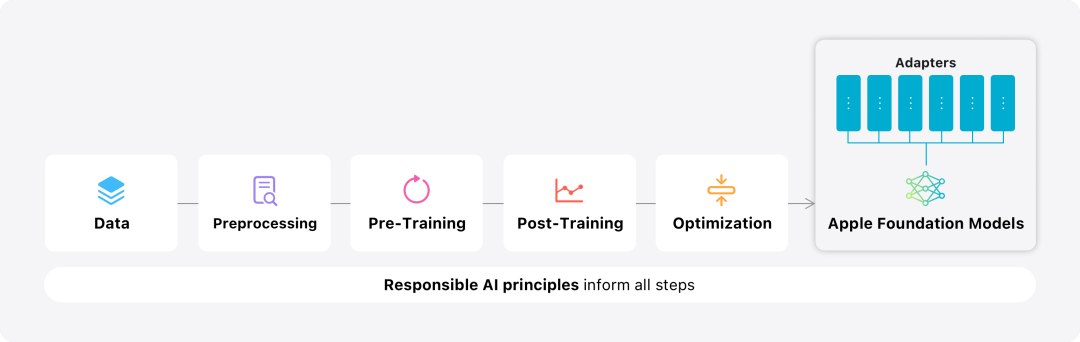
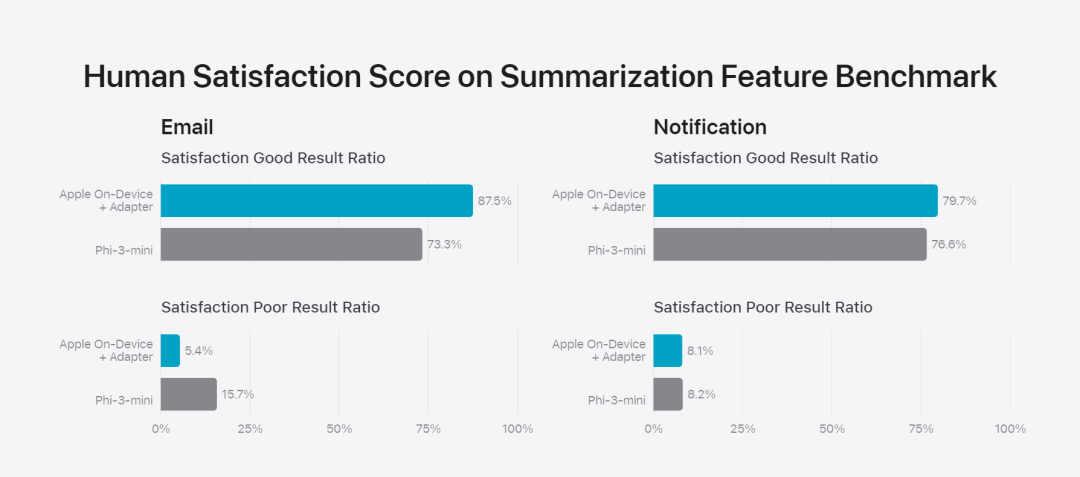
Apple passt das Basismodell genau an die täglichen Aktivitäten des Benutzers an und kann es dynamisch für die jeweilige Aufgabe spezialisieren.Das Forschungsteam verwendet Adapter, kleine neuronale Netzwerkmodule, die in verschiedene Schichten eines vorab trainierten Modells eingesteckt werden können, um das Modell für bestimmte Aufgaben zu optimieren. Insbesondere passte das Forschungsteam die Aufmerksamkeitsmatrix, die Aufmerksamkeitsprojektionsmatrix und die vollständig verbundene Schicht im punktuellen Feedforward-Netzwerk an. Durch die bloße Feinabstimmung der Adapterschicht bleiben die ursprünglichen Parameter des vorab trainierten Basismodells unverändert, das allgemeine Wissen des Modells bleibt erhalten, während die Adapterschicht an die Unterstützung spezifischer Aufgaben angepasst wird. Abbildung 2: Adapter sind kleine Sammlungen von Modellgewichten, die auf einem gemeinsamen Basismodell überlagert sind. Sie können dynamisch geladen und ausgetauscht werden, sodass sich das zugrunde liegende Modell dynamisch auf die jeweilige Aufgabe spezialisieren kann. Apple Intelligence umfasst einen umfangreichen Satz an Adaptern, die jeweils auf bestimmte Funktionen abgestimmt sind. Dies ist eine effiziente Möglichkeit, die Funktionalität des Basismodells zu erweitern. Das Forschungsteam verwendet 16 Bit, um die Werte von Adapterparametern zu charakterisieren. Für ein Gerätemodell mit etwa 3 Milliarden Parametern erfordern die Parameter von 16 Adaptern normalerweise 10 Megabyte. Adaptermodelle können dynamisch geladen, vorübergehend im Speicher zwischengespeichert und ausgetauscht werden. Dadurch kann sich das zugrunde liegende Modell dynamisch auf die aktuelle Aufgabe spezialisieren und gleichzeitig den Speicher effizient verwalten und die Reaktionsfähigkeit des Betriebssystems sicherstellen. Um das Training von Adaptern zu erleichtern, hat Apple eine effiziente Infrastruktur geschaffen, um Adapter schnell neu zu trainieren, zu testen und bereitzustellen, wenn das zugrunde liegende Modell oder die Trainingsdaten aktualisiert werden. Apple konzentriert sich beim Benchmarking des Modells auf die menschliche Bewertung, da die Ergebnisse der menschlichen Bewertung in hohem Maße mit der Benutzererfahrung des Produkts korrelieren. Um die produktspezifischen Zusammenfassungsfunktionen zu bewerten, verwendete das Forschungsteam einen Satz von 750 Antworten, die sorgfältig für jeden Anwendungsfall ausgewählt wurden. Der Bewertungsdatensatz betont die Vielfalt der Eingaben, denen ein Produktmerkmal in der Produktion ausgesetzt sein kann, und umfasst eine geschichtete Mischung aus einzelnen und gestapelten Dokumenten unterschiedlicher Inhaltstypen und Längen. Experimentelle Ergebnisse ergaben, dass Modelle mit Adaptern bessere Zusammenfassungen generieren konnten als ähnliche Modelle. Im Rahmen einer verantwortungsvollen Entwicklung identifiziert und bewertet Apple spezifische Risiken, die mit Abstracts verbunden sind. Zusammenfassungen entfernen beispielsweise manchmal wichtige Nuancen oder andere Details. Das Forschungsteam stellte jedoch fest, dass der Digest-Adapter sensible Inhalte in mehr als 99 % der gezielten gegnerischen Proben nicht verstärkte.用 Abbildung 3: Das Verhältnis von „gut“ und „Unterschied“ im abstrakten Anwendungsfall. Neben der Bewertung der spezifischen Funktionalität, die vom Basismodell und den Adaptern unterstützt wird, bewertete das Forschungsteam auch die allgemeine Funktionalität von On-Device-Modellen und serverbasierten Modellen. Konkret nutzte das Forschungsteam einen umfassenden Satz realer Eingabeaufforderungen, um die Modellfunktionalität zu testen und umfasste Brainstorming, Klassifizierung, geschlossene Fragen und Antworten, Codierung, Extraktion, mathematisches Denken, offene Fragen und Antworten, Umschreiben, Sicherheit, Zusammenfassung und Schreibaufgabe.
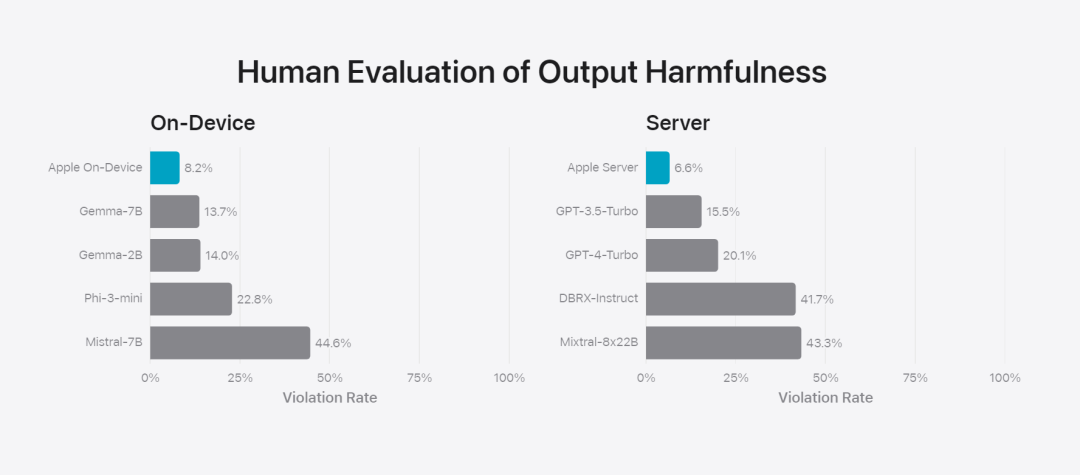
Das Forschungsteam verglich das Modell mit Open-Source-Modellen (Phi-3, Gemma, Mistral, DBRX) und kommerziellen Modellen vergleichbarer Größenordnung (GPT-3.5-Turbo, GPT-4-Turbo). Es wurde festgestellt, dass Apples Modell von menschlichen Bewertern im Vergleich zu den meisten Konkurrenzmodellen bevorzugt wurde. Beispielsweise übertrifft Apples On-Device-Modell mit ~3B-Parametern größere Modelle, darunter die Servermodelle Phi-3-mini, Mistral-7B und Gemma-7B; sie konkurrieren mit DBRX-Instruct, Mixtral-8x22B und GPT-3.5-Turbo im Vergleich nicht minderwertig und gleichzeitig sehr effizient.基 Abbildung 4: Der Anteil des Antwortverhältnisses bei der Bewertung des Apple-Basismodells und des Vergleichsmodells. Das Forschungsteam nutzte auch einen anderen Satz kontroverser Eingabeaufforderungen, um die Leistung des Modells bei schädlichen Inhalten, sensiblen Themen und Fakten zu testen, und maß die von menschlichen Bewertern ermittelte Modellverstoßrate, wobei niedrigere Zahlen besser waren Gut. Angesichts gegnerischer Eingabeaufforderungen sind sowohl geräteinterne als auch serverbasierte Modelle robust und weisen geringere Verstoßraten auf als Open-Source- und kommerzielle Modelle.、 Abbildung 5: Der Anteil schädlicher Inhalte, sensibler Themen und Sachlichkeit (je niedriger, desto besser). Das Modell von Apple ist sehr robust, wenn es mit gegnerischen Aufforderungen konfrontiert wird. Angesichts der breiten Möglichkeiten großer Sprachmodelle arbeitet Apple aktiv mit internen und externen Teams in manuellen und automatisierten Red Teams zusammen, um die Sicherheit der Modelle weiter zu bewerten.
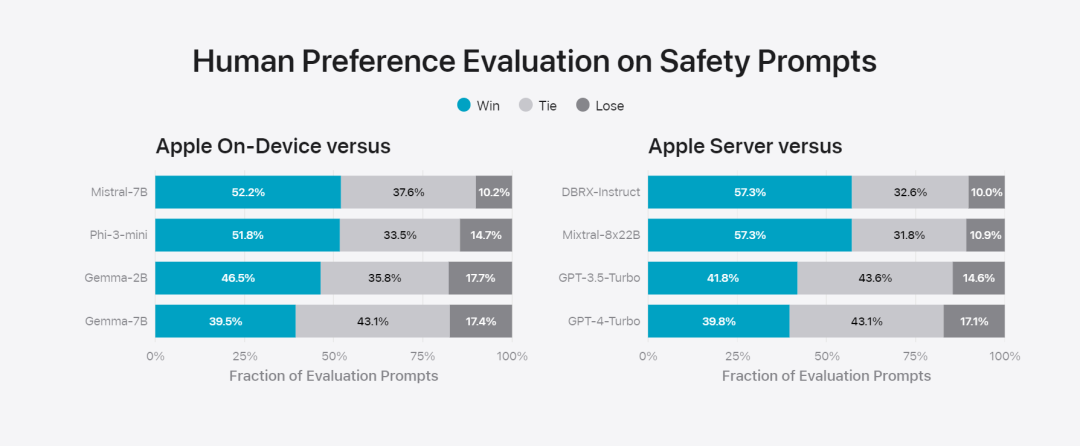
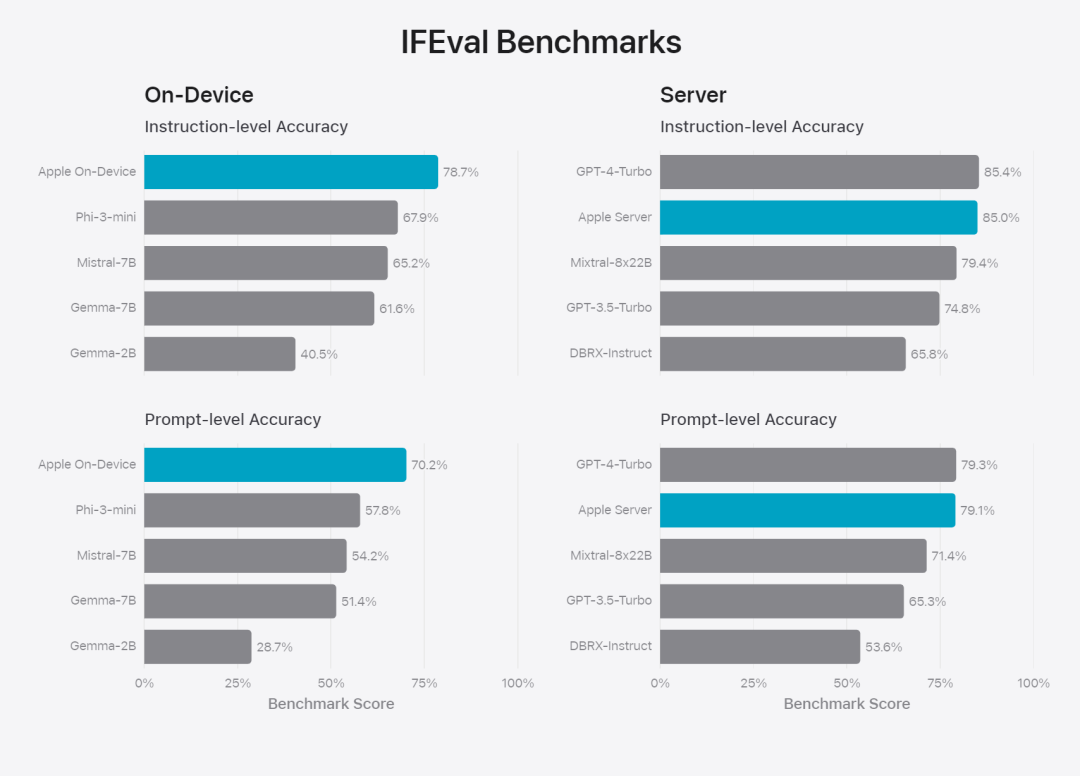
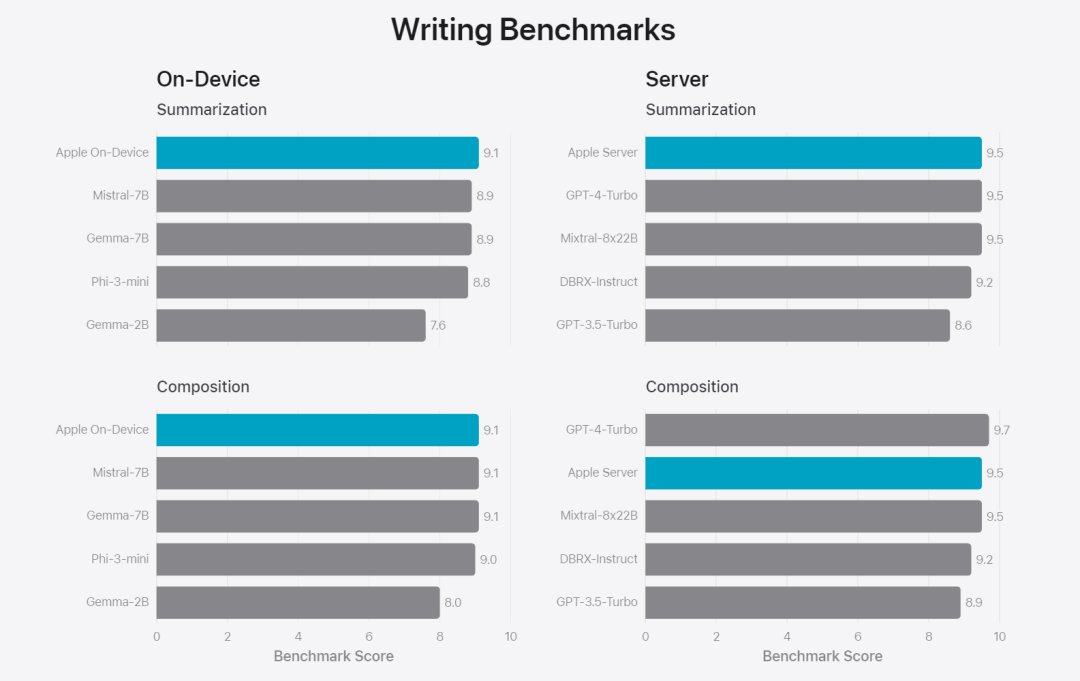
Abbildung 6: Anteil der bevorzugten Antworten bei paralleler Auswertung des Basismodells von Apple und ähnlicher Modelle im Hinblick auf Sicherheitsaufforderungen. Menschliche Prüfer fanden die Antworten des Apple-Basismodells sicherer und hilfreicher. Zur weiteren Evaluierung des Modells verwendete das Forschungsteam den IFEval-Benchmark (Instruction Tracing Evaluation), um seine Fähigkeiten zur Befehlsverfolgung mit Modellen ähnlicher Größe zu vergleichen. Die Ergebnisse zeigen, dass sowohl On-Device- als auch Server-Modelle detaillierteren Anweisungen besser folgen als Open-Source- und kommerzielle Modelle gleichen Umfangs.基 Abbildung 7: Apple-Basismodelle und Befehlsverfolgungsfunktionen ähnlicher Maßstabsmodelle (unter Verwendung des IFEVAL-Benchmarks). Apple bewertete auch die Schreibfähigkeit des Modells anhand verschiedener Schreibanweisungen. Abbildung 8: Schreibfähigkeit (je höher, desto besser. Schauen wir uns abschließend das Video von Apple an, in dem die Technologie hinter Apple Intelligence vorgestellt wird.
Referenzlink: https://machinelearning.apple.com/research/introducing-apple-foundation-modelsDas obige ist der detaillierte Inhalt vonDas Modell hinter Apples Intelligenz wird bekannt gegeben: Das 3B-Modell ist besser als Gemma-7B und das Servermodell ist mit GPT-3.5-Turbo vergleichbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn