
Heim >Technologie-Peripheriegeräte >KI >LeCuns neue Arbeit: geschichtetes Weltmodell, datengesteuerte Steuerung humanoider Roboter
LeCuns neue Arbeit: geschichtetes Weltmodell, datengesteuerte Steuerung humanoider Roboter

- PHPzOriginal
- 2024-06-13 11:37:171086Durchsuche
Mit großen Modellen als intelligentem Segen sind humanoide Roboter zu einem neuen Trend geworden.
Der Roboter im Science-Fiction-Film „Kann sagen, dass ich kein Mensch bin“ scheint näher zu kommen.
Allerdings ist es für Roboter, insbesondere humanoide Roboter, immer noch ein schwieriges technisches Problem, wie Menschen zu denken und zu handeln.
Nehmen Sie als Beispiel ein einfaches Laufenlernen: Die Verwendung von Verstärkungslernen zum Trainieren kann sich zu Folgendem entwickeln:

Es gibt kein Problem in der Theorie (dem Belohnungsmechanismus folgend) und dem Ziel des Gehens Die Treppe hinauf ist erreicht, außer dass der Prozess relativ abstrakt ist, er ist möglicherweise nicht derselbe wie die meisten menschlichen Verhaltensmuster.
Der Grund, warum es für Roboter schwierig ist, sich „natürlich“ wie Menschen zu verhalten, liegt in der hochdimensionalen Natur des Beobachtungs- und Aktionsraums und der inhärenten Instabilität der zweibeinigen Form.
In diesem Zusammenhang lieferte eine Arbeit, an der LeCun beteiligt war, eine neue Lösung, die auf datengesteuerten Daten basiert.

Paper -Adresse: https://arxiv.org/pdf/2405.18418
project EINLEITUNG: https://nicklashansen.com/rlpuppeteer
look bei der Wirksamkeit zuerst:

Wenn man die Wirkung auf der rechten Seite vergleicht, hat die neue Methode Verhaltensweisen trainiert, die denen des Menschen ähnlicher sind. Obwohl sie eine gewisse „Zombie“-Bedeutung hat, wurde die Abstraktionsebene stark reduziert, zumindest im Rahmen der Möglichkeiten die meisten Menschen.
Natürlich sagten einige Internetnutzer, die kamen, um Ärger zu machen: „Das vorherige sah interessanter aus.“

In dieser Arbeit erforschen Forscher einen stark datengesteuerten, visuellen Ganzkörper-Humanoid-Kontrollansatz, der auf verstärkendem Lernen ohne vereinfachende Annahmen, Belohnungsdesigns oder Fertigkeitsprimitive basiert.
Der Autor schlug ein hierarchisches Weltmodell vor, um zwei Agenten, einen High-Level- und einen Low-Level-Agenten, zu trainieren. Der High-Level-Agent generiert Befehle basierend auf visuellen Beobachtungen, die der Low-Level-Agent ausführen soll.
Offener Quellcode: https://github.com/nicklashansen/puppeteer
Dieses Modell mit dem Namen Puppeteer nutzt einen simulierten humanoiden 56-DoF-Roboter, um in 8 Aufgaben Leistungskontrollstrategien zu erzeugen Gleichzeitig synthetisieren sie natürliche, menschenähnliche Bewegungen und die Fähigkeit, anspruchsvolles Gelände zu durchqueren.

Hochdimensionales kontrolliertes hierarchisches Weltmodell
Das Erlernen und Trainieren von Allzweckagenten in der physischen Welt war schon immer eines der Ziele der Forschung auf dem Gebiet der KI.
Humanoide Roboter können durch die Integration von Ganzkörperkontrolle und -wahrnehmung verschiedene Aufgaben ausführen und zeichnen sich daher als multifunktionale Plattformen aus.
Aber die Kosten für die Nachahmung fortgeschrittener Tiere wie uns sind immer noch sehr hoch.
Um beispielsweise nicht in Gruben zu treten, muss der humanoide Roboter im Bild unten die Position und Länge der entgegenkommenden Bodenlücke genau erfassen und gleichzeitig seine gesamten Körperbewegungen sorgfältig koordinieren, um dies zu gewährleisten Es hat genug Schwung und Reichweite, um jede Lücke zu überwinden.

Puppeteer ist eine datengesteuerte RL-Methode, die auf dem hierarchischen JEPA-Weltmodell basiert, das 2022 von LeCun vorgeschlagen wurde.
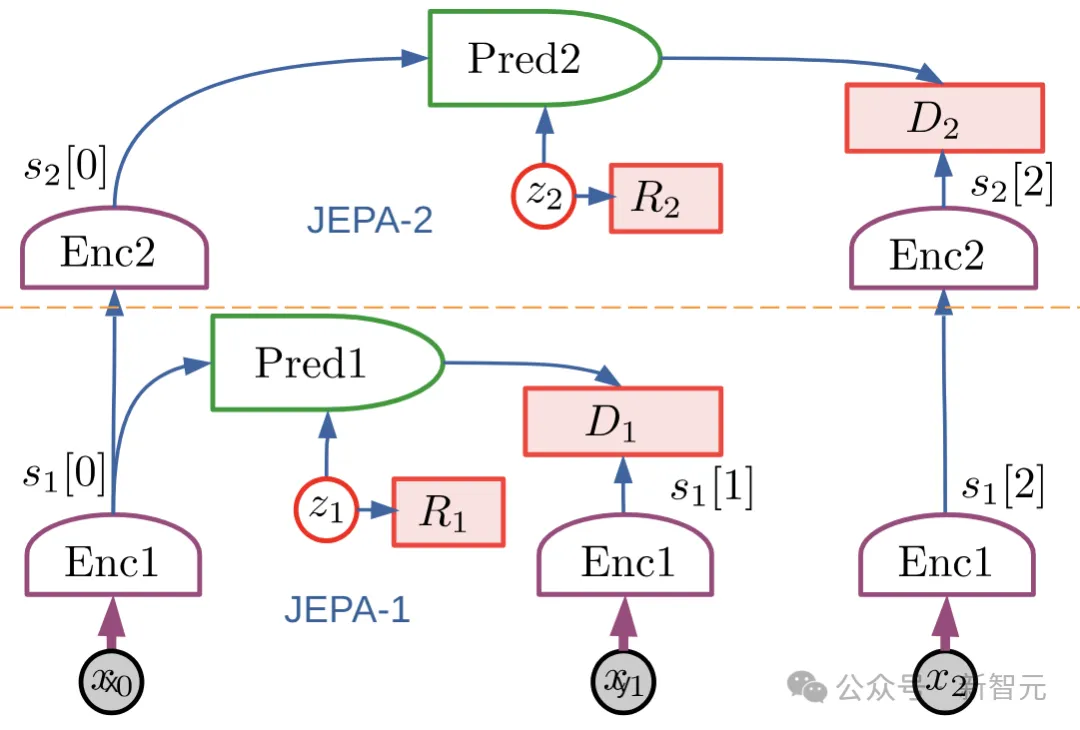
Es besteht aus zwei verschiedenen Agenten: Einer ist für die Wahrnehmung und Verfolgung verantwortlich und verfolgt die Referenzbewegung durch Steuerung auf Gelenkebene. Der andere „visuelle Marionette“ (Puppenspieler) lernt, nachgelagerte Aufgaben auszuführen, indem er niedrigdimensionale Referenzbewegungen synthetisiert die ehemalige Tracking-Unterstützung.
Puppeteer verwendet den modellbasierten RL-Algorithmus TD-MPC2, um zwei Agenten unabhängig voneinander in zwei verschiedenen Phasen zu trainieren.
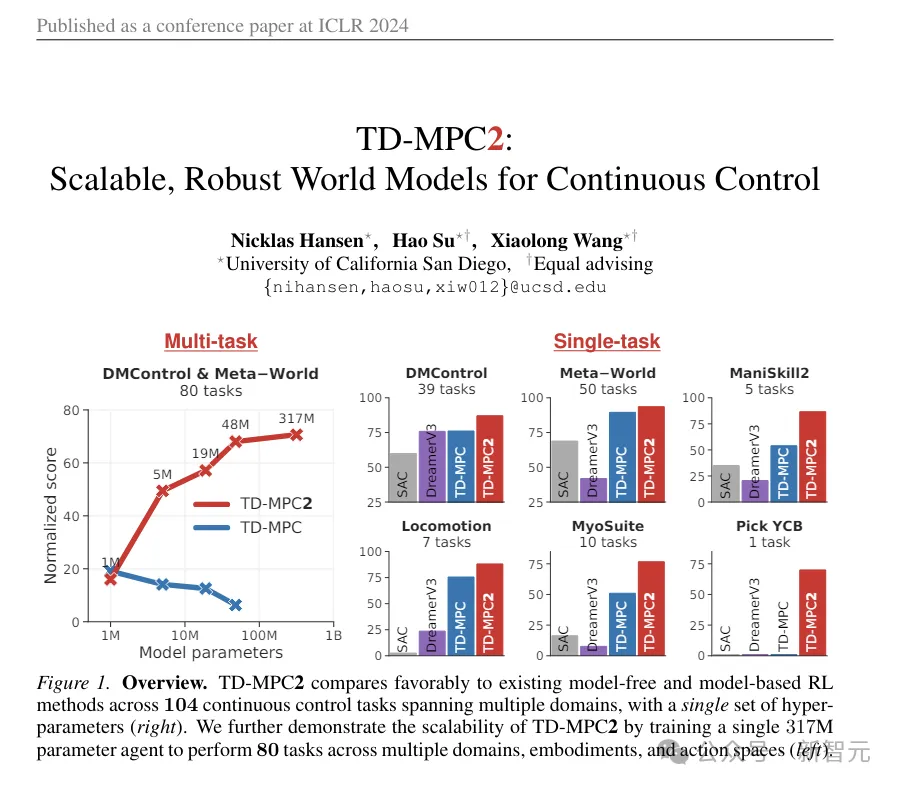
(ps: Dieses TD-MPC2 ist das animierte Bild, das am Anfang des Artikels zum Vergleich verwendet wurde. Obwohl es etwas abstrakt erscheint, handelt es sich tatsächlich um das vorherige SOTA, das in der diesjährigen ICLR veröffentlicht wurde, und das erste Werk (auch die erste Arbeit dieses Artikels.)
In der ersten Phase wird das Weltmodell für die Verfolgung zunächst vorab trainiert, wobei bereits vorhandene menschliche Bewegungserfassungsdaten als Referenz verwendet werden, um Bewegungen in physisch ausführbare Aktionen umzuwandeln . Dieser Agent kann gespeichert und in allen nachgelagerten Aufgaben wiederverwendet werden.
In der zweiten Stufe wird ein Marionetten-Weltmodell trainiert, das visuelle Beobachtungen als Eingabe verwendet und Referenzbewegungen, die von einem anderen Agenten bereitgestellt werden, als Ausgabe gemäß der angegebenen nachgelagerten Aufgabe integriert.
Dieses Framework scheint sehr einfach zu sein: Die beiden Weltmodelle sind algorithmisch gleich, unterscheiden sich nur in der Eingabe/Ausgabe und werden mit RL ohne weiteren Schnickschnack trainiert.
Im Gegensatz zu herkömmlichen hierarchischen RL-Einstellungen gibt „Puppet“ die geometrischen Positionen der Endeffektorgelenke aus und nicht die Einbettung des Ziels.
Dadurch lässt sich der für die Nachverfolgung zuständige Agent problemlos zwischen Aufgaben teilen und verallgemeinern, wodurch insgesamt Rechenplatz gespart wird.
Forschungsmethode
Die Forscher modellierten die visuelle Ganzkörper-Humanoid-Kontrolle als ein verstärkendes Lernproblem, das durch einen Markov-Entscheidungsprozess (MDP) gesteuert wird, der auf dem Tupel (S, A, T, R, γ) basiert , Δ) sind Merkmale,
wobei S der Zustand, A die Aktion, T die Umgebungsübergangsfunktion, R die skalare Belohnungsfunktion, γ der Abzinsungsfaktor und Δ die Beendigungsbedingung ist.
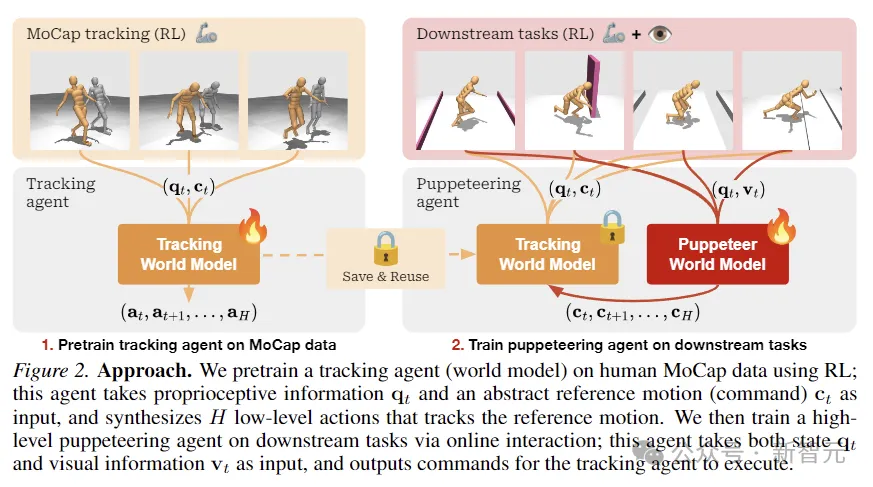
Wie in der Abbildung oben gezeigt, verwendeten die Forscher RL, um den Tracking-Agenten anhand menschlicher MoCap-Daten vorab zu trainieren, die verwendet wurden, um propriozeptive Informationen und abstrakte Referenzbewegungseingaben zu erhalten und Aktionen auf niedriger Ebene zu synthetisieren Verfolgung der Referenzbewegung.
Anschließend wird durch Online-Interaktion der für nachgelagerte Aufgaben zuständige erweiterte Puppet-Agent trainiert. Der Puppet akzeptiert Status- und visuelle Informationseingaben und gibt Befehle zur Ausführung durch den Tracking-Agenten aus.
TD-MPC2
TD-MPC2 lernt ein latentes decoderfreies Weltmodell aus Umgebungsinteraktionen und nutzt das gelernte Modell für die Planung.
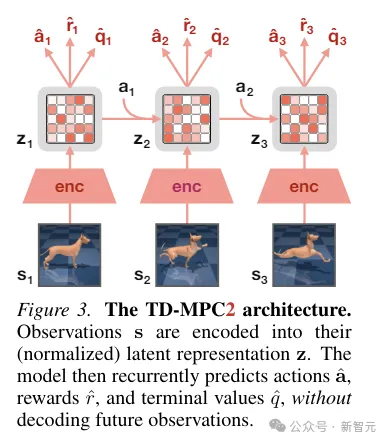
Alle Komponenten des Weltmodells werden durchgängig mithilfe einer Kombination aus gemeinsamer Einbettungsvorhersage, Belohnungsvorhersage und zeitlichem Differenzverlust erlernt, ohne die ursprünglichen Beobachtungen zu dekodieren.
Während der Inferenz folgt TD-MPC2 dem Model Predictive Control (MPC)-Framework und verwendet Model Predictive Path Integral (MPPI) als ableitungsfreien (abtastbasierten) Optimierer für die lokale Trajektorienoptimierung.
Um die Planung zu beschleunigen, lernt TD-MPC2 im Vorfeld auch eine modellfreie Strategie, um das Probenahmeprogramm vorab zu starten.
Beide Agenten sind algorithmisch identisch und bestehen beide aus den folgenden 6 Komponenten:

Experiment
Um die Wirksamkeit der Methode zu bewerten, schlugen die Forscher eine neue Task-Suite vor, die eine simulierte 56 verwendet Humanoider Roboter mit einem Freiheitsgrad zur visuellen Ganzkörperkontrolle. Er umfasst insgesamt 8 anspruchsvolle Aufgaben. Zu den zum Vergleich verwendeten Methoden gehören SAC, DreamerV3 und TD-MPC2.
Die 8 Aufgaben sind in der folgenden Abbildung dargestellt, darunter 5 Aufgaben zur Ganzkörperbewegung bei Sehstörungen und weitere 3 Aufgaben ohne visuelle Eingabe.
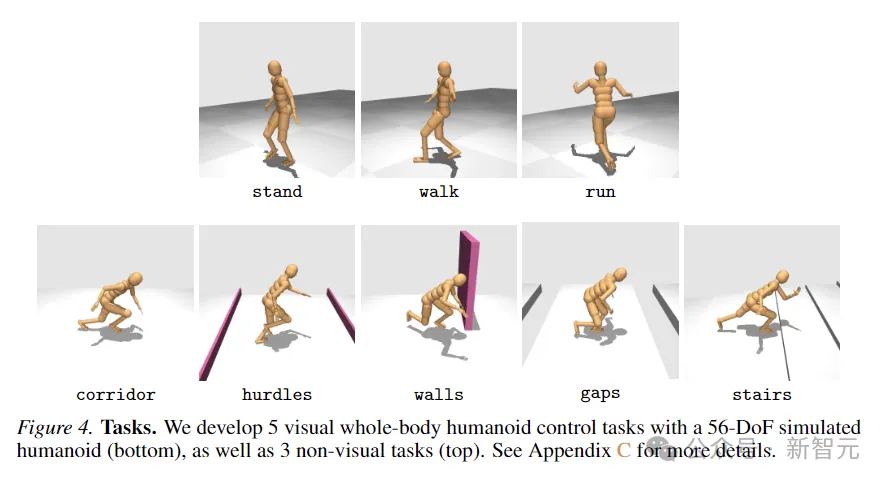
Quests sind mit einem hohen Grad an Zufälligkeit konzipiert und umfassen das Hinunterlaufen von Korridoren, das Springen über Hindernisse und Lücken, das Hochlaufen von Treppen und das Umgehen von Wänden.
Die fünf visuellen Kontrollaufgaben verwenden alle eine Belohnungsfunktion proportional zur linearen Vorwärtsgeschwindigkeit, während die nichtvisuellen Aufgaben eine Verschiebung in jede Richtung belohnen.
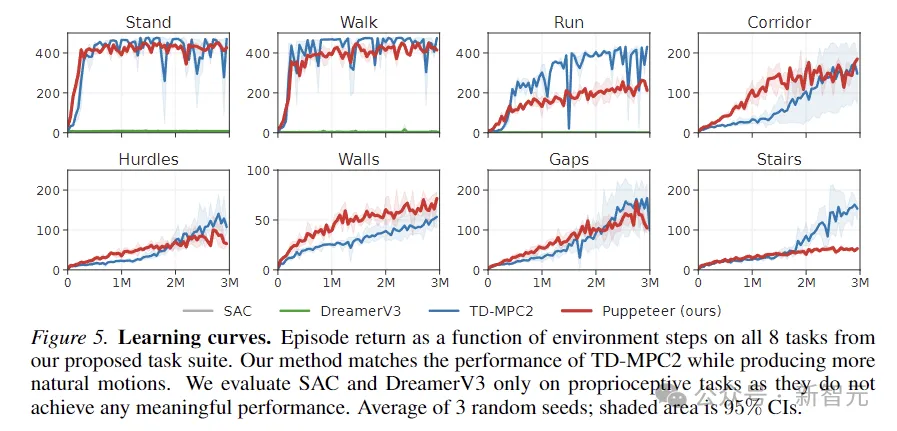
Das obige Bild zeigt die Lernkurve. Die Ergebnisse zeigen, dass SAC und DreamerV3 bei diesen Aufgaben keine sinnvolle Leistung erzielen können.
TD-MPC2 ist hinsichtlich der Belohnungen mit unserer Methode vergleichbar, erzeugt jedoch unnatürliches Verhalten (siehe abstrakte Aktionen im Bild unten).

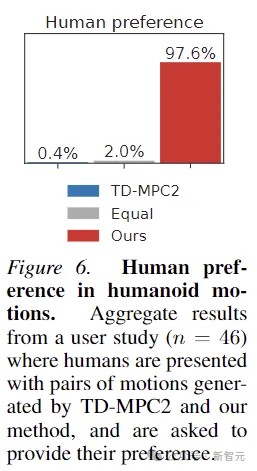
Um zu beweisen, dass die von Puppeteer erzeugten Bewegungen tatsächlich „natürlicher“ sind, wurde in diesem Artikel auch ein menschliches Präferenzexperiment durchgeführt. Der Test mit 46 Teilnehmern zeigte, dass Menschen die Bewegungen im Allgemeinen mögen Bewegungen, die durch diese Methode erzeugt werden.
Das obige ist der detaillierte Inhalt vonLeCuns neue Arbeit: geschichtetes Weltmodell, datengesteuerte Steuerung humanoider Roboter. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Python implementiert den auf itchat basierenden Roboter zur Synchronisierung von WeChat-Gruppennachrichten
- Verwendung von Python zur Implementierung der automatischen Antwort kleiner Roboter und zur skalierbaren Entwicklung kleiner Roboter für öffentliche WeChat-Konten
- Was bedeutet, dass der Start des Windows-Bootmanagers fehlgeschlagen ist?
- Was ist KI?