
Heim >Technologie-Peripheriegeräte >KI >Verwenden Sie NVIDIA Riva, um schnell chinesische Sprach-KI-Dienste auf Unternehmensebene bereitzustellen und diese zu optimieren und zu beschleunigen
Verwenden Sie NVIDIA Riva, um schnell chinesische Sprach-KI-Dienste auf Unternehmensebene bereitzustellen und diese zu optimieren und zu beschleunigen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-10 21:57:481189Durchsuche
1. Riva-Übersicht
1. Übersicht

Riva ist ein von NVIDIA eingeführtes SDK für Echtzeit-Sprach-KI-Dienste. Es ist ein hochgradig anpassbares Tool und nutzt GPU-Beschleunigung. Viele vorab trainierte Modelle werden auf NGC bereitgestellt. Diese Modelle sind sofort einsatzbereit und können direkt mit den von Riva bereitgestellten ASR- und TTS-Lösungen bereitgestellt werden.
Um den Anforderungen bestimmter Bereiche gerecht zu werden oder benutzerdefinierte Funktionen zu entwickeln, können Benutzer NeMo auch verwenden, um diese Modelle neu zu trainieren oder zu verfeinern. Dadurch wird die Leistung des Modells weiter verbessert und es besser an die Benutzerbedürfnisse anpassbar.
Riva+Skills ist ein hochgradig anpassbares Tool, das die GPU nutzt, um die Streaming-Spracherkennung und Sprachsynthese in Echtzeit zu beschleunigen und Tausende gleichzeitiger Anfragen gleichzeitig bearbeiten kann. Es unterstützt mehrere Bereitstellungsplattformen, einschließlich lokaler, Cloud- und endseitiger Bereitstellungsplattformen.
2. Riva ASR

In Bezug auf die Spracherkennung verwendet Riva hochpräzise SOTA-Modelle wie Citrinet, Conformer und NeMos selbst entwickelten FastConformer. Derzeit unterstützt Riva mehr als 10 einsprachige Modelle sowie die mehrsprachige Spracherkennung, einschließlich der Spracherkennung Englisch-Spanisch, Englisch-Chinesisch und Englisch-Japanisch.
Durch angepasste Funktionen kann die Genauigkeit des Modells weiter verbessert werden. Beispielsweise kann die Unterstützung spezifischer Branchenterminologie, Akzente oder Dialekte sowie die Anpassung an laute Umgebungen dazu beitragen, die Leistung der Spracherkennung zu verbessern.
Rivas Gesamtrahmen kann auf eine Vielzahl von Szenarien angewendet werden, beispielsweise auf Kundendienst- und Konferenzsysteme. Neben allgemeinen Szenarien können die Dienste von Riva auch an die Bedürfnisse verschiedener Branchen angepasst werden, beispielsweise CSP, Bildung, Finanzen und andere Branchen.
3. ASR-Pipeline und Anpassung
Im gesamten Prozess von Riva ASR gibt es einige anpassbare Module, die je nach Schwierigkeitsgrad in drei Kategorien unterteilt werden können.

Das orangefarbene Kästchen ist zunächst die Anpassung, die während des Inferenzprozesses auf dem Client vorgenommen werden kann. Beispielsweise unterstützt es die Hot-Word-Funktion, indem es während des Inferenzprozesses Produktnamen oder Eigennamen hinzufügt, sodass das Sprachmodell diese spezifischen Wörter genauer identifizieren kann. Diese Funktion wird von Riva nativ unterstützt und kann angepasst werden, ohne das Modell neu zu trainieren oder den Riva-Server neu zu starten.
In der violetten Box finden Sie einige Anpassungen, die bei der Bereitstellung vorgenommen werden können. Die Streaming-Erkennung von Riva bietet beispielsweise zwei Modi: Latenzoptimierung oder Durchsatzoptimierung, die je nach Geschäftsanforderungen ausgewählt werden können, um eine bessere Leistung zu erzielen. Darüber hinaus kann das Aussprachewörterbuch während des Bereitstellungsprozesses auch angepasst werden. Mit einem individuellen Aussprachewörterbuch können Sie die korrekte Aussprache eines bestimmten Begriffs, Namens oder Branchenjargons sicherstellen und die Genauigkeit der Spracherkennung verbessern.
Das grüne Kästchen ist die Anpassung, die während des Trainingsprozesses vorgenommen werden kann, also das Training und die Anpassungen, die auf der Serverseite durchgeführt werden. Beispielsweise kann in der Textregulierungsphase zu Beginn des Trainings eine gewisse Verarbeitung spezifischer Texte hinzugefügt werden. Darüber hinaus kann das Akustikmodell fein abgestimmt oder neu trainiert werden, um Probleme wie Akzente und Lärm in bestimmten Geschäftsszenarien zu lösen und das Modell robuster zu machen. Sie können auch Sprachmodelle neu trainieren, Interpunktionsmodelle verfeinern, Text invers regulieren usw.
Die oben genannten sind die anpassbaren Teile von Riva.
4. Riva TTS

Der Riva TTS-Prozess ist auf der rechten Seite des Bildes dargestellt. Er enthält die folgenden Module:
- Der erste Schritt ist die Textregularisierung.
- Der zweite Schritt ist G2P, das die Grundeinheiten des Textes in die Grundeinheiten der Aussprache oder gesprochenen Sprache umwandelt. Wandeln Sie beispielsweise Wörter in Phoneme um.
- Der dritte Schritt ist die Spektrumsynthese, bei der Text in akustisches Spektrum umgewandelt wird.
- Der vierte Schritt ist die Audiosynthese, auch Vocoder genannt. In diesem Schritt wird das im vorherigen Schritt erhaltene Spektrum in Audio umgewandelt.
Geben Sie im Bild oben am Beispiel des Satzes „Hello World“ zunächst das Textregularisierungsmodul ein, um den Text zu standardisieren, z. B. die Normalisierung von Groß- und Kleinschreibung. Geben Sie dann das G2P-Modul ein, um den Text in eine Phonemfolge umzuwandeln. Rufen Sie dann das Spektrumsynthesemodul auf und erhalten Sie das Spektrum durch neuronales Netzwerktraining. Geben Sie abschließend den Vocoder ein, um das Spektrum in den endgültigen Klang umzuwandeln.
Riva bietet Streaming-TTS-Unterstützung unter Verwendung einer Kombination der derzeit beliebten FastPitch- und HiFi-GAN-Modelle. Unterstützt derzeit mehrere Sprachen, darunter Englisch, Mandarin-Chinesisch, Spanisch, Italienisch und Deutsch.
5. TTS-Pipeline und Anpassung
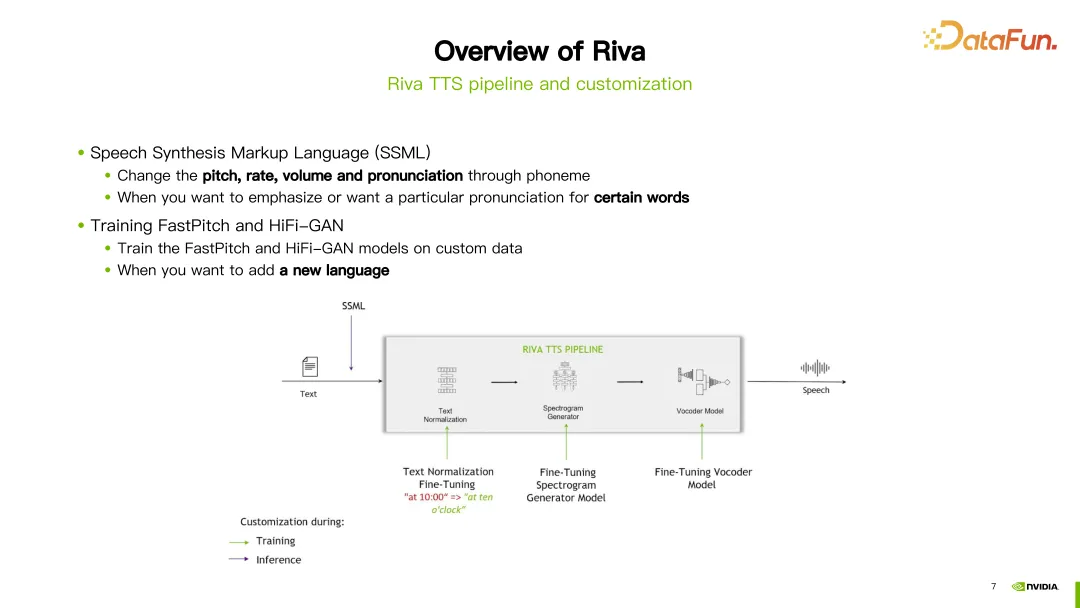
Im TTS-Prozess von Riva stehen zwei Methoden zur Anpassung zur Verfügung. Die erste Möglichkeit ist die Verwendung der Speech Synthesis Markup Language (SSML), die eine einfachere Möglichkeit zur Anpassung bietet. Durch einige Konfigurationen können Tonhöhe, Sprechgeschwindigkeit, Lautstärke usw. der Aussprache angepasst werden. Normalerweise würden Sie diese Methode wählen, wenn Sie die Aussprache eines bestimmten Wortes ändern möchten.
Eine andere Möglichkeit besteht darin, das FastPitch- oder HiFi-GAN-Modell zu verfeinern oder neu zu trainieren. Beide Modelle können anhand Ihrer eigenen spezifischen Daten verfeinert oder neu trainiert werden.
2. Das neueste Update des chinesischen Spracherkennungsmodells
1. Übersicht

Im vergangenen Jahr hat Riva einige Aktualisierungen und Verbesserungen am chinesischen Modell vorgenommen. Hier sind einige der wichtigen Updates.
Zunächst optimieren Sie weiterhin das chinesische Spracherkennungsmodell (ASR). Die neuesten ASR-Modelle finden Sie unter den entsprechenden Links.
Zweitens wird die Unterstützung für das Unified Model eingeführt. Dies bedeutet, dass die Satzzeichenvorhersage der Spracherkennung gleichzeitig in einer Schlussfolgerung erfolgen kann.
Drittens wurde die Unterstützung für gemischte Modelle in Chinesisch und Englisch hinzugefügt. Das bedeutet, dass das Modell sowohl chinesische als auch englische Spracheingaben verarbeiten kann.
Darüber hinaus wurden einige neue Module und Funktionsunterstützung eingeführt. Enthält Module zur Erkennung neuronaler Netzwerke (Voice Activity Detection, VAD) und zur Sprecherdiagnose. Die Funktion der Regularisierung chinesischer inverser Texte wird ebenfalls vorgestellt. Details zu diesen Modellen finden Sie in den entsprechenden Links.
2. Word Boosting
Darüber hinaus bieten wir auch ausführliche Tutorials für Chinesisch an. Der erste Teil ist ein Tutorial zu heißen Wörtern (Word Boosting).

Hot Words passen die Gewichtung eines bestimmten Wortes während der Erkennung an, um die Worterkennung genauer zu machen. Im Tutorial wird ein Beispiel eines chinesischen Modells gezeigt, das heiße Wörter wie „Wangyue“, den Namen eines alten Gedichts, verwendet, und wir geben diesem Wort eine Gewichtung von 20. Als nächstes verwenden Sie die von Riva bereitgestellte Methode add_word_boosting_to_config, um die Wörter, die wir hinzufügen möchten, und ihre Bewertungen im Client zu konfigurieren. Senden Sie dann die konfigurierte Anfrage an den ASR-Server, um die Erkennungsergebnisse nach dem Hinzufügen von Hotwords zu erhalten.
Beim Konfigurieren von Hotwords müssen Sie zwei Parameter festlegen: boosted_lm_words und boosted_lm_score. boosted_lm_words ist eine Liste von Wörtern, deren Erkennungsgenauigkeit wir verbessern möchten. Boosted_lm_score ist die für diese Wörter festgelegte Punktzahl, normalerweise zwischen 20 und 100.

Neben der bisherigen Grundkonfiguration unterstützt die Hot-Word-Funktion von Riva auch einige erweiterte Nutzungsmöglichkeiten. Beispielsweise kann die Gewichtung mehrerer Wörter gleichzeitig erhöht werden. Im Beispiel legen wir beispielsweise Gewichtungen von 20 und 30 für die Wörter „fünf G“ bzw. „vier G“ fest.
Darüber hinaus können wir durch Word-Boosting auch die Genauigkeit bestimmter Wörter verringern, ihnen also negative Gewichte zuweisen und so ihre Auftrittswahrscheinlichkeit verringern. Im Beispiel erhalten wir beispielsweise das chinesische Schriftzeichen „she“ und dessen Bewertung ist auf -100 festgelegt. Auf diese Weise wird das Modell dazu neigen, das chinesische Schriftzeichen nicht zu erkennen. Theoretisch können wir beliebig viele Hotwords einstellen, ohne die Latenz zu beeinflussen. Es ist auch erwähnenswert, dass der Boosting-Prozess auf der Clientseite implementiert wird und keine Auswirkungen auf die Serverseite hat.
3. Feinabstimmung des Conformer AM
Das zweite Tutorial befasst sich mit der Feinabstimmung des Conformer-Akustikmodells.

Die Feinabstimmung von ASR erfolgt mit NeMo-Tools. Nachdem Sie das NGC-Konto konfiguriert haben, können Sie mit dem Befehl „NGC download“ das von Riva bereitgestellte vorab trainierte chinesische Modell direkt herunterladen. In diesem Beispiel wurde die fünfte Version des chinesischen ASR-Modells heruntergeladen. Nachdem der Download abgeschlossen ist, müssen Sie das vorab trainierte Modell laden.
Zuerst müssen Sie einige Pakete importieren. Der Parameter Modellpfad wird auf den Pfad des gerade heruntergeladenen Modells gesetzt. Verwenden Sie als Nächstes die von NeMo bereitgestellte Funktion ASRModel.restore_from, um die Modellkonfigurationsdatei abzurufen, und verwenden Sie den Zielparameter, um die Kategorie des ursprünglichen ASR-Modells abzurufen. Verwenden Sie als Nächstes die Funktion import_class_by_path, um die tatsächliche Modellklasse abzurufen. Verwenden Sie abschließend die Methode „restore_from“ des Modells in dieser Kategorie, um die ASR-Modellparameter unter dem angegebenen Pfad zu laden.

Nach dem Laden des Modells können Sie das von NeMo bereitgestellte Trainingsskript zur Feinabstimmung verwenden. In diesem Beispiel nehmen wir das Training des CTC-Modells als Beispiel und das verwendete Skript ist Speech_to_text_ctc.py. Zu den Parametern, die konfiguriert werden müssen, gehören train_ds.manifest_filepath, der JSON-Dateipfad der Trainingsdaten, sowie die Angabe, ob die GPU, der Optimierer und die maximale Anzahl von Iterationsrunden verwendet werden sollen.
Nach dem Training des Modells kann es ausgewertet werden. Bei der Auswertung müssen Sie darauf achten, den Parameter use_cer auf true zu setzen, da wir für Chinesisch die Zeichenfehlerrate (Character Error Rate) als Indikator verwenden. Nachdem Sie das Training und die Evaluierung des Modells abgeschlossen haben, können Sie den Befehl nemo2riva verwenden, um das NeMo-Modell in ein Riva-Modell zu konvertieren. Verwenden Sie dann das Quickstart-Tool von Riva, um das Modell bereitzustellen.
3. Riva TTS-Dienst (Text-to-Speech)
Als nächstes stellen wir den Riva TTS-Dienst vor.
1. Demo
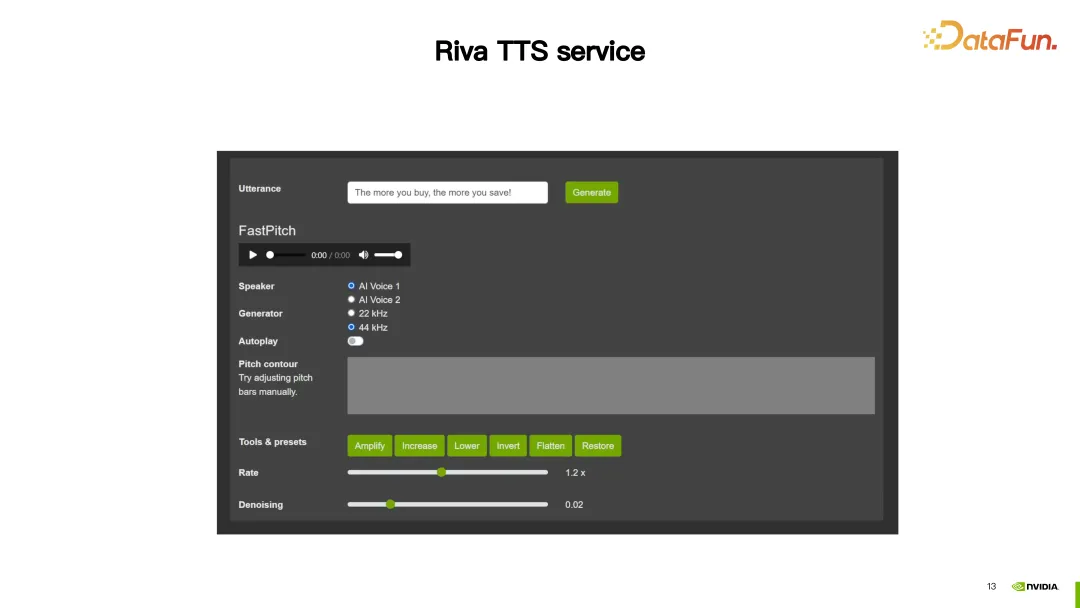
In dieser Demo bietet Riva TTS Anpassungsfunktionen, um die synthetisierte Sprache natürlicher zu gestalten.
Als nächstes stellen wir die beiden von Riva TTS bereitgestellten Anpassungsmethoden vor.
2. SSML

Die erste ist die oben genannte SSML (Speech Synthesis Markup Language), die über ein Skript konfiguriert wird. Über SSML kann die Prosodie in TTS angepasst werden, einschließlich Tonhöhe und Geschwindigkeit, und auch die Lautstärke kann angepasst werden.
Wie im Bild oben gezeigt, ändern Sie für den ersten Satz „Heute ist ein sonniger Tag“ die Tonhöhe des Reims auf 2,5. Für den zweiten Satz wurden zwei Konfigurationen vorgenommen: Die eine bestand darin, die Rate auf hoch einzustellen, und die andere darin, die Lautstärke um 1 dB zu erhöhen. So erhalten Sie ein individuelles Ergebnis.
3. TTS-Feinabstimmung mit NeMo
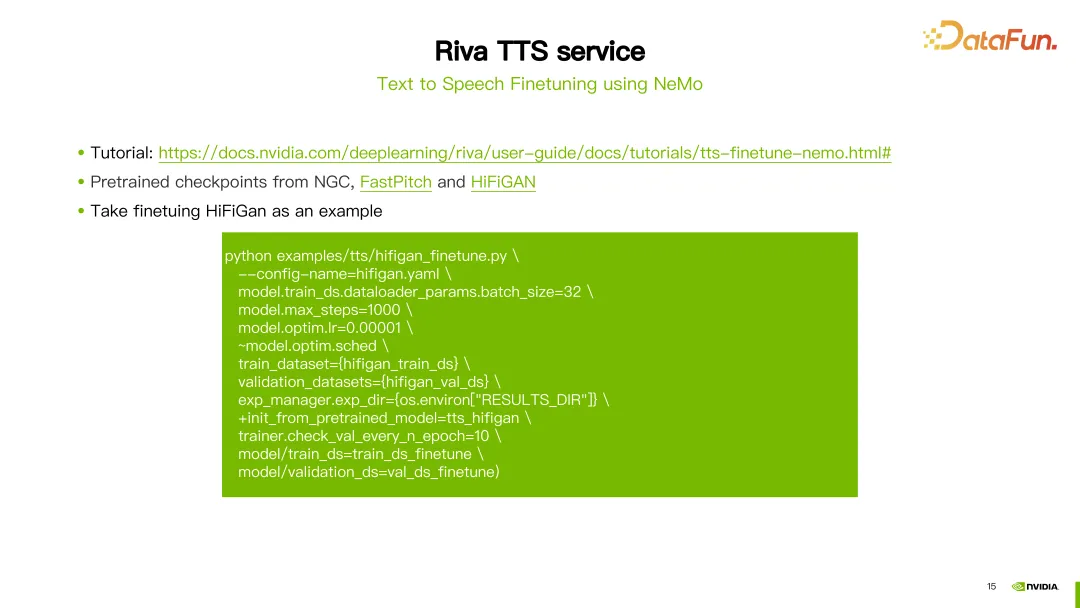
Zusätzlich zu SSML können Sie auch NeMo-Tools verwenden, um die FastPitch- oder HiFi-GAN-Modelle von Riva TTS zu optimieren oder neu zu trainieren.
Riva bietet Tutorials und einige vorab trainierte Modelle zu NGC (siehe Link im Bild oben).
Das Bild zeigt ein Beispiel für die Feinabstimmung des HiFi-GAN-Modells. Verwenden Sie den Befehl hifigan_finetune.py und konfigurieren Sie Parameter wie den Namen der Modellkonfiguration, die Stapelgröße, die maximale Anzahl von Iterationsschritten und die Lernrate. Legen Sie den zur Feinabstimmung von HiFi-GAN erforderlichen Datensatzpfad fest, indem Sie den Parameter train_dataset festlegen. Wenn Sie ein vorab trainiertes Modell von NGC heruntergeladen haben, können Sie auch den Parameter init_from_pretrained_model verwenden, um das vorab trainierte Modell zu laden. Auf diese Weise kann das HiFi-GAN-Modell neu trainiert werden.
4. Riva Quickstart Tool
Das angepasste Modell kann mit dem Quickstart Tool bereitgestellt werden.
1. Vorbereitung

Bevor Sie beginnen, müssen Sie ein NGC-Konto registrieren, sicherstellen, dass die GPU Riva unterstützt und die Docker-Umgebung installiert ist.
Sobald die Vorbereitungen abgeschlossen sind, laden Sie Riva Quickstart über den bereitgestellten Link herunter. Wenn die NGC-CLI konfiguriert wurde, können Sie die NGC-CLI auch verwenden, um Riva Quickstart direkt herunterzuladen.
2. Starten und Herunterfahren des Servers
Nachdem Sie Riva Quick Start heruntergeladen haben, können Sie die bereitgestellten Skripte verwenden, um den Server zu initialisieren, zu starten und herunterzufahren.

Am Beispiel der neuesten Version von Riva (2.13.1) müssen Sie nach Abschluss des Downloads nur noch riva_init.sh, riva_start.sh oder riva_stop.sh ausführen, um die Initialisierung und den Start abzuschließen und Herunterfahren des Servers.
Wenn Sie ein chinesisches Modell verwenden möchten, stellen Sie einfach den Sprachcode auf zh-CN ein und das Tool lädt automatisch das entsprechende vorab trainierte Modell herunter. Sie können den Dienst starten, um die chinesischen Funktionen ASR (automatische Spracherkennung) und TTS (Text-to-Speech) zu nutzen.
3. Riva Client

Sobald der Server erfolgreich gestartet ist, können Sie den Dienst mit dem von Riva bereitgestellten Skript riva_start_client.sh aufrufen. Wenn Sie eine Offline-Spracherkennung wünschen, führen Sie einfach den Befehl riva_asr_client aus und geben Sie den Pfad zu der Audiodatei an, die Sie erkennen möchten. Wenn Sie eine Streaming-Spracherkennung durchführen möchten, können Sie den Befehl riva_streaming_asr_client verwenden. Wenn Sie eine Sprachsynthese durchführen möchten, können Sie den Befehl riva_tts_client verwenden, um das zu verarbeitende oder zu synthetisierende Audio an den gerade gestarteten Server zu senden. 5. Referenz-Ressourcen Hier finden Sie die offizielle Dokumentation von Riva, um mehr über Riva zu erfahren und alle Aspekte kennenzulernen.
Riva Quick Start-Benutzerhandbuch: Dieses Handbuch bietet Benutzern detaillierte Anweisungen für Riva Quick Start, einschließlich Installations- und Konfigurationsschritten sowie Antworten auf häufig gestellte Fragen. Sollten bei der Verwendung von Riva Quick Start Probleme auftreten, finden Sie die Antworten in diesem Benutzerhandbuch.Riva-Versionshinweise: Dieses Dokument enthält aktualisierte Informationen zu den neuesten Modellen von Riva. Was in den einzelnen Versionen neu und verbessert ist, erfahren Sie hier.

Die oben genannten Ressourcen helfen Benutzern, Riva besser zu verstehen und zu nutzen.
Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Vielen Dank an alle.
6. Frage- und AntwortsitzungF1: Welche Beziehung besteht zwischen Riva und Triton? Gibt es funktionale Überschneidungen?
A1: Ja, Riva verwendet das Inferenz-Framework von Nvidia Triton, das auf einer Entwicklung von Nvidia Triton basiert.
F2: Wurde Riva tatsächlich im RAG-Bereich implementiert? Oder ein Open-Source-Projekt?
A2: Riva sollte sich derzeit hauptsächlich auf den Bereich Sprach-KI konzentrieren.
F3: Gibt es eine Beziehung zwischen Riva und Nemo?
A3: Riva konzentriert sich mehr auf Bereitstellungslösungen. Mit Riva können wir auch einige Feinabstimmungs- und Schulungsarbeiten durchführen und dann ein gutes Modell bereitstellen in Riva.
F4: Können von anderen Frameworks trainierte Modelle angewendet werden?
A4: Das Training mit anderen Frameworks wird vorübergehend nicht unterstützt oder erfordert zusätzliche Entwicklungsarbeit.
F5: Kann Riva Modelle aus dem PyTorch- oder TensorFlow-Trainingsframework bereitstellen?
A5: Riva unterstützt jetzt hauptsächlich von Nemo trainierte Modelle. Nemo wurde tatsächlich auf Basis von PyTorch entwickelt.
F6: Wenn ich ein neues Modell in Nemo anpasse, muss ich dann Bereitstellungscode in Riva schreiben?
A6: Wenn Sie selbst entwickelte Modelle in Riva unterstützen möchten, müssen Sie einige zusätzliche Entwicklungen durchführen.
F7: Kann Riva mit einer GPU mit kleinem Speicher verwendet werden?
A7: Sie können sich auf die von Riva bereitgestellten Dokumente zur Anpassungsplattform beziehen, die die Anpassung verschiedener GPU-Typen umfassen.
F8: Wie kann ich Riva schnell ausprobieren?
A8: Sie können Riva ausprobieren, indem Sie das Riva Quickstart-Toolkit direkt auf NGC herunterladen.
F9: Wenn Riva chinesische Dialekte unterstützen möchte, benötigt Riva dann eine maßgeschneiderte Schulung?
A9: Richtig. Sie können Daten in einigen Ihrer eigenen Dialekte verwenden. Passen Sie es einfach anhand des von Riva bereitgestellten vorab trainierten Modells an und stellen Sie es dann in Riva bereit.
F10: Gibt es Überschneidungen oder Unterschiede in der Positionierung von Riva und Tensor LM?
A10: Die Beschleunigung von Riva nutzt tatsächlich Tensor RT. Riva ist ein Produkt, das auf Tensor RT und Triton basiert.
Das obige ist der detaillierte Inhalt vonVerwenden Sie NVIDIA Riva, um schnell chinesische Sprach-KI-Dienste auf Unternehmensebene bereitzustellen und diese zu optimieren und zu beschleunigen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Verwendung von öffentlichen, privaten, geschützten, abstrakten und anderen Schlüsselwörtern in PHP
- Einfacher Vergleich der Unterschiede und Einführung in die Verwendung zwischen Public&Private&Protect in PHP
- So lösen Sie das Problem, dass der Nvidia-Treiber erfolgreich installiert wurde, der Anzeigetreiber jedoch nicht
- Unterschied zwischen const, static, public, privat und protected in PHP
- Wie wäre es mit einer NVIDIA GeForce 940MX-Grafikkarte?