
Heim >Technologie-Peripheriegeräte >KI >Einfach und universell: Dreifache verlustfreie Trainingsbeschleunigung des Visual Basic Network, Tsinghua EfficientTrain++ für TPAMI 2024 ausgewählt
Einfach und universell: Dreifache verlustfreie Trainingsbeschleunigung des Visual Basic Network, Tsinghua EfficientTrain++ für TPAMI 2024 ausgewählt

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-10 14:54:281151Durchsuche
Der Autor dieses Diskussionspapiers, Wang Yulin, ist 2019 Direktdoktorand in der Abteilung für Automatisierung der Tsinghua-Universität. Er studierte bei Akademiker Wu Cheng und außerordentlichem Professor Huang Gao. Computer Vision usw. Er hat als Erstautor Diskussionspapiere in Fachzeitschriften und Konferenzen wie TPAMI, NeurIPS, ICLR, ICCV, CVPR, ECCV usw. veröffentlicht. Er erhielt das Baidu-Stipendium, den Microsoft Scholar, den CCF-CV Academic Emerging Award, das ByteDance-Stipendium und andere Auszeichnungen . Persönliche Homepage: wyl.cool.
Dieser Artikel stellt hauptsächlich einen Artikel vor, der gerade von IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) angenommen wurde: EfficientTrain++: Generalized Curriculum Learning for Efficient Visual Backbone Training.

- Link zum Papier: https://arxiv.org/pdf/2405.08768
- Der Code und das vorab trainierte Modell sind Open Source: https://github.com/LeapLabTHU /EfficientTrain
- Konferenzversionspapier (ICCV 2023): https://arxiv.org/pdf/2211.09703
In den letzten Jahren war „Skalierung“ einer der Protagonisten der Computer-Vision-Forschung . Mit der Zunahme der Modellgröße und des Trainingsdatenumfangs, der Weiterentwicklung von Lernalgorithmen und der weit verbreiteten Anwendung von Regularisierungs- und Datenverbesserungstechnologien werden visuelle Basisnetzwerke, die durch groß angelegtes Training erhalten werden (wie Vision Transformer und MAE, trainiert auf ImageNet1K/22K), DINOv2 usw.) hat bei vielen wichtigen visuellen Aufgaben wie der visuellen Erkennung, der Zielerkennung und der semantischen Segmentierung eine beeindruckende Leistung erzielt.
Allerdings bringt „Skalierung“ oft einen unerschwinglichen hohen Modellschulungsaufwand mit sich, der die Weiterentwicklung und industrielle Anwendung grundlegender Visionsmodelle erheblich behindert.
Um dieses Problem zu lösen, schlug das Forschungsteam der Tsinghua-Universität einen verallgemeinerten Lehrplan-Lernalgorithmus vor: EfficientTrain++. Die Kernidee besteht darin, das traditionelle Paradigma des Kurslernens zu fördern, bei dem es darum geht, „Daten von einfach bis schwierig zu überprüfen und zu verwenden und das Modell schrittweise zu trainieren“ und „Datendimensionen nicht zu filtern, immer alle Trainingsdaten zu verwenden, sondern jedes Merkmal während des Trainingsprozesses schrittweise aufzudecken“. „Merkmale oder Muster (Muster) von leicht bis schwer jeder Datenprobe.“
EfficientTrain++ hat mehrere wichtige Highlights:
- Plug-and-Play-Implementierung des Visual Basic Network 1,5−3,0× verlustfreie Trainingsbeschleunigung. Weder die Leistung des Upstream- noch des Downstream-Modells geht verloren. Die gemessene Geschwindigkeit stimmt mit den theoretischen Ergebnissen überein.
- Universell anwendbar auf verschiedene Trainingsdatengrößen (z. B. ImageNet-1K/22K, der 22K-Effekt ist noch deutlicher). Wird häufig für überwachtes Lernen und selbstüberwachtes Lernen (z. B. MAE) verwendet. Gemeinsam für verschiedene Trainingskosten (z. B. entsprechend 0–300 oder mehr Epochen).
- Wird häufig in ViT, ConvNet und anderen Netzwerkstrukturen verwendet (in diesem Artikel wurden mehr als 20 Modelle unterschiedlicher Größe und Art getestet und sie sind konsistent und effektiv).
- Für kleinere Modelle kann es neben der Trainingsbeschleunigung auch die Leistung erheblich verbessern (z. B. ohne die Hilfe zusätzlicher Informationen und ohne zusätzlichen Trainingsaufwand, 81,3 % DeiT-S wurden auf ImageNet-1K erhalten , vergleichbar mit dem Original Swin-Tiny).
- Entwickelte spezielle Technologie zur Optimierung der tatsächlichen Effizienz für häufige praktische Situationen: 1) CPU/Festplatte ist nicht leistungsstark genug und die Effizienz der Datenvorverarbeitung kann nicht mit der GPU mithalten; 2) Massiv parallel Training, wie zum Beispiel das Training großer Modelle auf ImageNet-22K mit 64 oder mehr GPUs.
Als nächstes werfen wir einen Blick auf die Details der Studie.
Eins. Forschungsmotivation
In den letzten Jahren hat die energische Entwicklung groß angelegter Grundlagenmodelle den Fortschritt der künstlichen Intelligenz und des tiefen Lernens vorangetrieben. Im Bereich Computer Vision haben repräsentative Arbeiten wie Vision Transformer (ViT), CLIP, SAM und DINOv2 bewiesen, dass eine Vergrößerung der Größe neuronaler Netze und Trainingsdaten wichtige visuelle Aufgaben wie Kognition, Erkennung und Segmentierung erheblich erweitern kann . Leistungsgrenzen.
Allerdings haben große Basismodelle oft einen hohen Trainingsaufwand. Abbildung 1 zeigt zwei typische Beispiele. Am Beispiel von acht NVIDIA V100- oder leistungsstärkeren GPUs würde es Jahre oder sogar Jahrzehnte dauern, um nur eine Trainingssitzung für GPT-3 und ViT-G abzuschließen. Solch hohe Schulungskosten stellen einen enormen Aufwand dar, der sich sowohl für die Wissenschaft als auch für die Industrie nur schwer leisten lässt. Oftmals verbrauchen nur wenige hochrangige Institutionen große Mengen an Ressourcen, um den Fortschritt des Deep Learning voranzutreiben. Ein dringend zu lösendes Problem lautet daher: Wie kann die Trainingseffizienz groß angelegter Deep-Learning-Modelle effektiv verbessert werden?
 Abbildung 1 Beispiel: Hoher Trainingsaufwand für große Deep-Learning-Grundmodelle
Abbildung 1 Beispiel: Hoher Trainingsaufwand für große Deep-Learning-Grundmodelle
Für Computer-Vision-Modelle ist eine klassische Idee das Lehrplanlernen, wie in Abbildung 2 dargestellt, d Während des Modelltrainingsprozesses beginnen wir mit den „einfachsten“ Trainingsdaten und führen schrittweise Daten von einfach bis schwierig ein.
 Abbildung 2: Klassisches Curriculum-Lernparadigma (Bildquelle: „A Survey on Curriculum Learning“, TPAMI'22)
Abbildung 2: Klassisches Curriculum-Lernparadigma (Bildquelle: „A Survey on Curriculum Learning“, TPAMI'22)
Trotz der natürlichen Motivation wurde das Curriculum-Lernen jedoch nicht in großem Umfang zum Trainieren eingesetzt Visuelle Grundlagen Der Hauptgrund für die allgemeine Methode des Modells besteht darin, dass es zwei wesentliche Engpässe gibt, wie in Abbildung 3 dargestellt. Erstens ist es nicht einfach, einen effektiven Lehrplan (Curriculum) zu entwerfen. Die Unterscheidung zwischen „einfachen“ und „schwierigen“ Stichproben erfordert oft die Hilfe zusätzlicher Modelle vor dem Training, den Entwurf komplexerer AutoML-Algorithmen, die Einführung von Reinforcement Learning usw. und weist eine geringe Vielseitigkeit auf. Zweitens ist die Modellierung des Kurslernens selbst etwas unangemessen. Visuelle Daten in der natürlichen Verbreitung weisen häufig ein hohes Maß an Vielfalt auf (siehe Abbildung 3). Die Modelltrainingsdaten enthalten eine große Anzahl von Papageien mit unterschiedlichen Bewegungen Kamera, Papageien aus verschiedenen Perspektiven und Hintergründen sowie die vielfältigen Interaktionen zwischen Papageien und Menschen oder Objekten usw. ist es tatsächlich eine relativ grobe Methode, solche unterschiedlichen Daten nur durch eindimensionale Indikatoren von „einfach“ und „schwierig“ zu unterscheiden " und weit hergeholte Modellierungsmethoden.
 Abbildung 3 Zwei wesentliche Engpässe, die eine groß angelegte Anwendung des Kurslernens beim Training visueller Grundmodelle behindern
Abbildung 3 Zwei wesentliche Engpässe, die eine groß angelegte Anwendung des Kurslernens beim Training visueller Grundmodelle behindern
2. Einführung in die Methode
Inspiriert von den oben genannten Herausforderungen schlägt dieser Artikel ein verallgemeinertes Lehrplan-Lernparadigma vor. Die Kernidee besteht darin, „Daten von einfach bis schwierig zu überprüfen und schrittweise zu trainieren.“ Das traditionelle Kurs-Lernparadigma wird erweitert zu „Keine Filterung der Datendimensionen, es werden immer alle Trainingsdaten verwendet, aber die Merkmale oder Muster von einfach bis schwierig jeder Datenprobe werden während des Trainingsprozesses nach und nach aufgedeckt“, wodurch die durch die verursachten Einschränkungen und suboptimalen Designs effektiv vermieden werden Datenscreening-Paradigmen werden eliminiert, wie in Abbildung 4 dargestellt.
Abbildung 4 Traditionelles Lehrplanlernen (Beispieldimension) vs. allgemeines Lehrplanlernen (Merkmalsdimension) 
Im Trainingsprozess eines natürlichen visuellen Modells Obwohl das Modell jederzeit alle in den Daten enthaltenen Informationen abrufen kann, lernt das Modell auf natürliche Weise immer, einige in den Daten enthaltene einfachere Diskriminanzmerkmale (Muster) zu erkennen, und lernt dann nach und nach, schwierigere Diskriminanten darauf zu erkennen Basis. Funktionen . Darüber hinaus ist diese Regel relativ universell und „relativ einfache“ Unterscheidungsmerkmale können sowohl im Frequenzbereich als auch im räumlichen Bereich leicht gefunden werden. In diesem Artikel wurde eine Reihe interessanter Experimente entworfen, um die oben genannten Ergebnisse zu demonstrieren, wie unten beschrieben. Aus Sicht des Frequenzbereichs sind „Niederfrequenzmerkmale“ für das Modell „relativ einfach“. In Abbildung 5 trainierte der Autor dieses Artikels ein DeiT-S-Modell mithilfe von Standard-ImageNet-1K-Trainingsdaten und verwendete Tiefpassfilter mit unterschiedlichen Bandbreiten, um den Verifizierungssatz zu filtern, wobei nur die niederfrequenten Komponenten des Verifizierungsbildes beibehalten wurden. und berichtet auf dieser Grundlage über die Genauigkeit von DeiT-S anhand der tiefpassgefilterten Verifizierungsdaten während des Trainingsprozesses. Die Kurve der erhaltenen Genauigkeit im Verhältnis zum Trainingsprozess ist auf der rechten Seite von Abbildung 5 dargestellt. Wir können ein interessantes Phänomen beobachten: In den frühen Phasen des Trainings verringert die Verwendung nur tiefpassgefilterter Validierungsdaten die Genauigkeit nicht wesentlich, und der Trennpunkt zwischen der Kurve und der Genauigkeit des normalen Validierungssatzes nimmt mit dem Filter zu Die Bandbreite nimmt zu und bewegt sich allmählich nach rechts. Dieses Phänomen zeigt, dass das Modell zwar immer Zugriff auf die niederfrequenten und hochfrequenten Teile der Trainingsdaten hat, sein Lernprozess jedoch auf natürliche Weise damit beginnt, sich nur auf niederfrequente Informationen zu konzentrieren, und die Fähigkeit, höherfrequente Merkmale zu identifizieren, allmählich erworben wird später im Training (dieses Phänomen Weitere Beweise finden Sie im Originaltext). Dieser Befund wirft eine interessante Frage auf: Können wir einen Schulungslehrplan (Curriculum) entwerfen, der nur für beginnt? Das Modell? Zunächst eine visuelle Eingabe niederfrequenter Informationen bereitstellen und dann nach und nach hochfrequente Informationen einführen? Abbildung 6 untersucht die Idee, eine Tiefpassfilterung der Trainingsdaten nur während einer frühen Trainingsphase einer bestimmten Länge durchzuführen und den Rest des Trainingsprozesses unverändert zu lassen. Aus den Ergebnissen lässt sich erkennen, dass die endgültige Leistungsverbesserung zwar begrenzt ist, es jedoch interessant ist, dass die endgültige Genauigkeit des Modells weitgehend erhalten bleiben kann, selbst wenn dem Modell über einen beträchtlichen Zeitraum nur Niederfrequenzkomponenten zur Verfügung gestellt werden Frühe Trainingsphase, die auch mit der Beobachtung in Abbildung 5 übereinstimmt, dass „das Modell sich hauptsächlich auf das Lernen konzentriert, niederfrequente Merkmale in den frühen Phasen des Trainings zu identifizieren“. Diese Entdeckung hat den Autor dieses Artikels dazu inspiriert, über die Trainingseffizienz nachzudenken: Da das Modell in den frühen Phasen des Trainings nur niederfrequente Komponenten in den Daten benötigt und die niederfrequenten Komponenten weniger Informationen enthalten als die Originaldaten Kann das Modell die ursprüngliche Eingabe schneller verarbeiten als nur aus niederfrequenten Komponenten und mit geringerem Rechenaufwand effizient lernen? Tatsächlich ist diese Idee völlig realisierbar. Wie auf der linken Seite von Abbildung 7 dargestellt, führt der Autor dieses Artikels einen Zuschneidevorgang im Fourier-Spektrum des Bildes ein, um den niederfrequenten Teil auszuschneiden und ihn wieder dem Pixelraum zuzuordnen. Dieser Niederfrequenz-Zuschneidevorgang bewahrt alle Niederfrequenzinformationen genau und reduziert gleichzeitig die Größe der Bildeingabe, sodass der Rechenaufwand für das Lernen des Modells aus der Eingabe exponentiell reduziert werden kann. Wenn Sie diesen niederfrequenten Zuschneidevorgang verwenden, um die Modelleingabe in den frühen Phasen des Trainings zu verarbeiten, können Sie die gesamten Trainingskosten erheblich einsparen, erleiden aber dennoch nahezu keinen Leistungsverlust, da die für das Modelllernen erforderlichen Informationen vorhanden sind Das endgültige Modell und die experimentellen Ergebnisse sind in der unteren rechten Ecke von Abbildung 7 dargestellt. Neben Frequenzbereichsoperationen ist das Modell aus Sicht der räumlichen Domänentransformation auch in zu finden Begriffe von „relativ einfachen“ Funktionen. Beispielsweise sind natürliche Bildinformationen, die in rohen visuellen Eingaben enthalten sind und keiner starken Datenverbesserung oder Verzerrungsverarbeitung unterzogen wurden, für das Modell oft „einfacher“ und leichter zu erlernen, da sie aus realen Verteilungen abgeleitet sind Informationen, Invarianz usw., die durch Vorverarbeitungstechniken wie Datenverbesserung eingeführt werden, sind für das Modell oft schwer zu erlernen (ein typisches Beispiel ist auf der linken Seite von Abbildung 8 dargestellt). Tatsächlich wurde in bestehenden Forschungsarbeiten auch beobachtet, dass die Datenerweiterung vor allem in den späteren Phasen des Trainings eine Rolle spielt (z. B. „Improving Auto-Augment via Augmentation-Wise Weight Sharing“, NeurIPS’20). Um in dieser Dimension das Paradigma des allgemeinen Kurslernens zu verwirklichen, kann dies leicht erreicht werden, indem einfach die Intensität der Datenerweiterung geändert wird, um dem Modell nur natürliche Bildinformationen bereitzustellen, die in den Trainingsdaten leichter zu erlernen sind frühen Phasen der Ausbildung. Auf der rechten Seite von Abbildung 8 wird RandAugment als repräsentatives Beispiel verwendet, um diese Idee zu verifizieren. RandAugment enthält eine Reihe gängiger Transformationen zur Verbesserung räumlicher Daten (z. B. zufällige Rotation, sich ändernde Schärfe, affine Transformation, sich ändernde Belichtung usw.). Es ist zu beobachten, dass das Training des Modells ausgehend von einer schwächeren Datenerweiterung die endgültige Leistung des Modells effektiv verbessern kann, und diese Technik ist mit dem Zuschneiden bei niedriger Frequenz kompatibel. Bis zu diesem Punkt wurden in diesem Artikel der Kernrahmen und die Annahmen des allgemeinen Kurslernens vorgeschlagen und indem sie zwei Schlüsselphänomene im Frequenzbereich und im räumlichen Bereich aufdecken, beweisen sie die Rationalität und Wirksamkeit des allgemeinen Kurslernens. Auf dieser Grundlage vervollständigt dieses Papier eine Reihe systematischer Arbeiten, die im Folgenden aufgeführt sind. Aus Platzgründen lesen Sie bitte für weitere Forschungsdetails das Originalpapier. Der in diesem Artikel schließlich erhaltene allgemeine Lernplan für den EfficientTrain++-Kurs ist in Abbildung 9 dargestellt. EfficientTrain++ passt die Bandbreite der Niederfrequenzbeschneidung im Frequenzbereich und die Intensität der Datenverbesserung im räumlichen Bereich dynamisch an, basierend auf dem Verbrauchsprozentsatz des gesamten Rechenaufwands des Modelltrainings. Es ist erwähnenswert, dass EfficientTrain++ als Plug-and-Play-Methode ohne weitere Hyperparameteranpassung oder -suche direkt auf eine Vielzahl visueller Basisnetzwerke und verschiedene Modelltrainingsszenarien angewendet werden kann und der Effekt relativ stabil ist . Als Plug-and-Play-Methode reduziert EfficientTrain++ den tatsächlichen Trainingsaufwand verschiedener Visual-Basic-Netzwerke auf ImageNet-1K um etwa das 1,5-fache, ohne grundsätzlich die Leistung zu verlieren oder zu verbessern. Der Gewinn von EfficientTrain++ ist universell für verschiedene Trainings-Overhead-Budgets. Bei absolut gleicher Leistung schneidet DeiT/Swin besser ab auf ImageNet Das Trainingsbeschleunigungsverhältnis bei -1K beträgt etwa das 2-3-fache. EfficientTrain++ kann auf ImageNet-22k eine 2-3-fache leistungsverlustfreie Beschleunigung vor dem Training erreichen. Bei kleineren Modellen kann EfficientTrain++ erhebliche Leistungsverbesserungen an der Obergrenze erzielen. EfficientTrain++ ist auch für selbstüberwachte Lernalgorithmen (wie MAE) effektiv. EfficientTrain++ Das trainierte Modell verliert auch nicht an Leistung bei nachgelagerten Aufgaben wie Zielerkennung, Instanzsegmentierung und semantischer Segmentierung.  Abbildung 5 Aus Sicht des Frequenzbereichs neigt das Modell natürlich dazu, zuerst zu lernen, niederfrequente Merkmale zu identifizieren.
Abbildung 5 Aus Sicht des Frequenzbereichs neigt das Modell natürlich dazu, zuerst zu lernen, niederfrequente Merkmale zu identifizieren.  Abbildung 6: Die Bereitstellung nur niederfrequenter Komponenten für das Modell über einen langen Zeitraum des frühen Trainings hat keinen wesentlichen Einfluss auf die endgültige Leistung
Abbildung 6: Die Bereitstellung nur niederfrequenter Komponenten für das Modell über einen langen Zeitraum des frühen Trainings hat keinen wesentlichen Einfluss auf die endgültige Leistung Abbildung 7 Niederfrequenzzuschneiden: Lassen Sie das Modell effizient nur aus Niederfrequenzinformationen lernen
Abbildung 7 Niederfrequenzzuschneiden: Lassen Sie das Modell effizient nur aus Niederfrequenzinformationen lernen Abbildung 8 Finden der „leichter zu erlernenden“ Merkmale des Modells aus der Perspektive des Luftraums: eine Datenverbesserungsperspektive
Abbildung 8 Finden der „leichter zu erlernenden“ Merkmale des Modells aus der Perspektive des Luftraums: eine Datenverbesserungsperspektive
 Abbildung 9 Einheitlicher und integrierter allgemeiner Kurs-Lernplan: EfficientTrain++
Abbildung 9 Einheitlicher und integrierter allgemeiner Kurs-Lernplan: EfficientTrain++ III. Experimentelle Ergebnisse
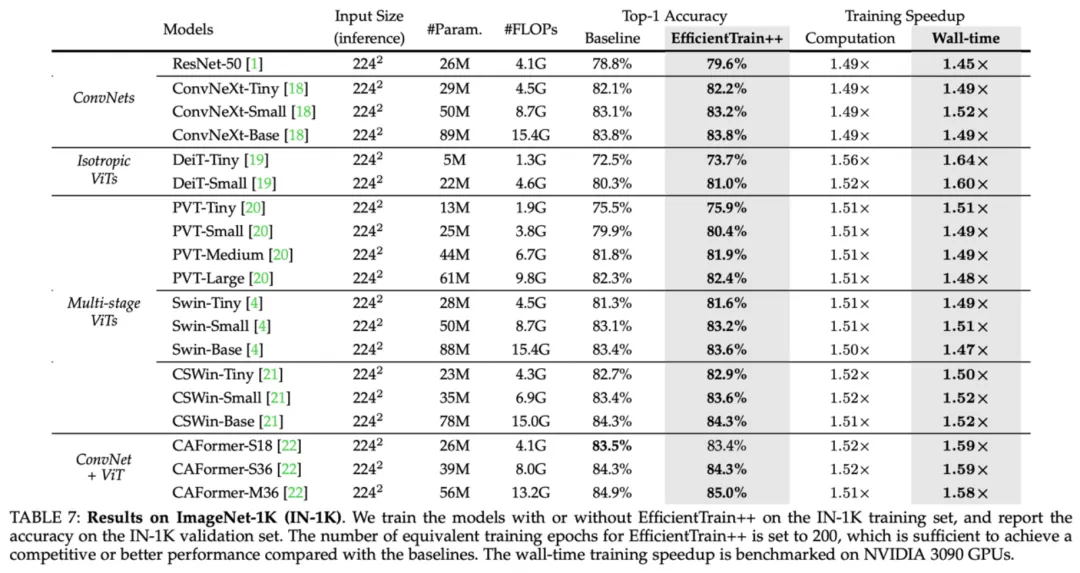 Abbildung 10 ImageNet-1K-Versuchsergebnisse: Leistung von EfficientTrain++ auf einer Vielzahl von Visual-Basic-Netzwerken
Abbildung 10 ImageNet-1K-Versuchsergebnisse: Leistung von EfficientTrain++ auf einer Vielzahl von Visual-Basic-Netzwerken  Abbildung 11 ImageNet-1K-Versuchsergebnisse: Leistung von EfficientTrain++ bei unterschiedlichen Trainings-Overhead-Budgets
Abbildung 11 ImageNet-1K-Versuchsergebnisse: Leistung von EfficientTrain++ bei unterschiedlichen Trainings-Overhead-Budgets  Abbildung 12 ImageNet-22K-Versuchsergebnisse: Leistung von EfficientTrain++ bei größeren Trainingsdaten
Abbildung 12 ImageNet-22K-Versuchsergebnisse: Leistung von EfficientTrain++ bei größeren Trainingsdaten Abbildung 13 ImageNet-1K-Versuchsergebnisse: EfficientTrain++ kann die Leistungsobergrenze kleinerer Modelle erheblich verbessern
Abbildung 13 ImageNet-1K-Versuchsergebnisse: EfficientTrain++ kann die Leistungsobergrenze kleinerer Modelle erheblich verbessern  Abbildung 14 EfficientTrain++ kann auf selbstüberwachtes Lernen (wie MAE) angewendet werden.
Abbildung 14 EfficientTrain++ kann auf selbstüberwachtes Lernen (wie MAE) angewendet werden.  Abbildung 15 COCO-Zielerkennung, COCO-Instanzsegmentierung und experimentelle Ergebnisse der semantischen ADE20K-Segmentierung
Abbildung 15 COCO-Zielerkennung, COCO-Instanzsegmentierung und experimentelle Ergebnisse der semantischen ADE20K-Segmentierung
Das obige ist der detaillierte Inhalt vonEinfach und universell: Dreifache verlustfreie Trainingsbeschleunigung des Visual Basic Network, Tsinghua EfficientTrain++ für TPAMI 2024 ausgewählt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!