
Heim >Technologie-Peripheriegeräte >KI >YOLOv10 ist da! Echte End-to-End-Zielerkennung in Echtzeit
YOLOv10 ist da! Echte End-to-End-Zielerkennung in Echtzeit

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-09 17:29:311179Durchsuche
In den letzten Jahren hat sich YOLOs aufgrund seines effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zu einem Mainstream-Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das strukturelle Design, die Optimierungsziele, Datenverbesserungsstrategien usw. von YOLOs eingehend untersucht und dabei erhebliche Fortschritte erzielt. Allerdings behindert die Nachbearbeitungsabhängigkeit von Non-Maximum Suppression (NMS) die durchgängige Bereitstellung von YOLOs und wirkt sich negativ auf die Inferenzlatenz aus. Darüber hinaus mangelt es dem Design verschiedener Komponenten in YOLOs an einer umfassenden und gründlichen Überprüfung, was zu erheblicher Rechenredundanz führt und die Modellleistung einschränkt. Dies führt zu einer suboptimalen Effizienz und einem enormen Potenzial für Leistungsverbesserungen. In dieser Arbeit wollen wir die Leistungs-Effizienz-Grenze von YOLOs sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter vorantreiben. Zu diesem Zweck schlagen wir zunächst eine dauerhafte doppelte Zuweisung für das NMS-freie Training von YOLOs vor, die gleichzeitig wettbewerbsfähige Leistung und eine geringere Inferenzlatenz bringt. Darüber hinaus stellen wir eine umfassende, auf Effizienz und Genauigkeit basierende Modellentwurfsstrategie für YOLOs vor. Wir haben jede Komponente von YOLOs umfassend im Hinblick auf Effizienz und Genauigkeit optimiert, was den Rechenaufwand erheblich reduziert und die Modellfähigkeiten verbessert. Das Ergebnis unserer Bemühungen ist eine neue Generation der YOLO-Serie namens YOLOv10, die für die End-to-End-Objekterkennung in Echtzeit entwickelt wurde. Umfangreiche Experimente zeigen, dass YOLOv10 in verschiedenen Modellmaßstäben modernste Leistung und Effizienz erreicht. Beispielsweise ist unser YOLOv10-S im COCO-Datensatz unter einem ähnlichen AP 1,8-mal schneller als RT-DETR-R18 und reduziert gleichzeitig Parameter und Gleitkommaoperationen (FLOPs) um das 2,8-fache. Im Vergleich zu YOLOv9-C reduziert YOLOv10-B die Latenz um 46 % und reduziert die Parameter um 25 % bei gleicher Leistung. Code-Link: https://github.com/THU-MIG/yolov10.
Welche Verbesserungen gibt es in YOLOv10?
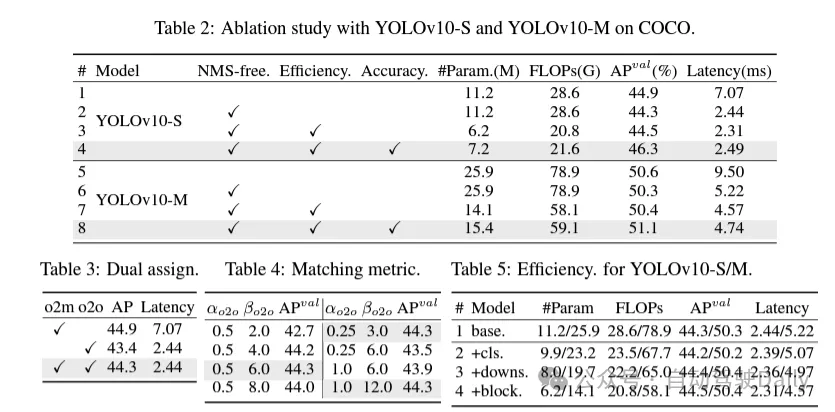
Beheben Sie zunächst das Problem der redundanten Vorhersage in der Nachbearbeitung, indem Sie eine dauerhafte Dual-Allokationsstrategie für NMS-freie YOLOs vorschlagen. Diese Strategie umfasst die Zuweisung zweier Labels und konsistente Matching-Metriken. Dadurch kann das Modell während des Trainings eine umfassende und harmonische Überwachung erhalten und gleichzeitig die Notwendigkeit von NMS während der Inferenz eliminieren, wodurch eine wettbewerbsfähige Leistung bei gleichzeitig hoher Effizienz erzielt wird.
Dieses Mal wird eine umfassende, auf Effizienz und Genauigkeit basierende Modellentwurfsstrategie für die Modellarchitektur vorgeschlagen und jede Komponente in YOLOs umfassend untersucht. Im Hinblick auf die Effizienz werden leichte Klassifizierungsköpfe, raumkanalentkoppeltes Downsampling und ranggesteuerte Blockdesigns vorgeschlagen, um offensichtliche Rechenredundanz zu reduzieren und eine effizientere Architektur zu erreichen.
Im Hinblick auf die Genauigkeit werden große Kernelfaltungen untersucht und wirksame Module zur partiellen Selbstaufmerksamkeit vorgeschlagen, um die Modellfähigkeiten zu verbessern und Leistungsverbesserungspotenziale bei geringen Kosten auszuschöpfen.
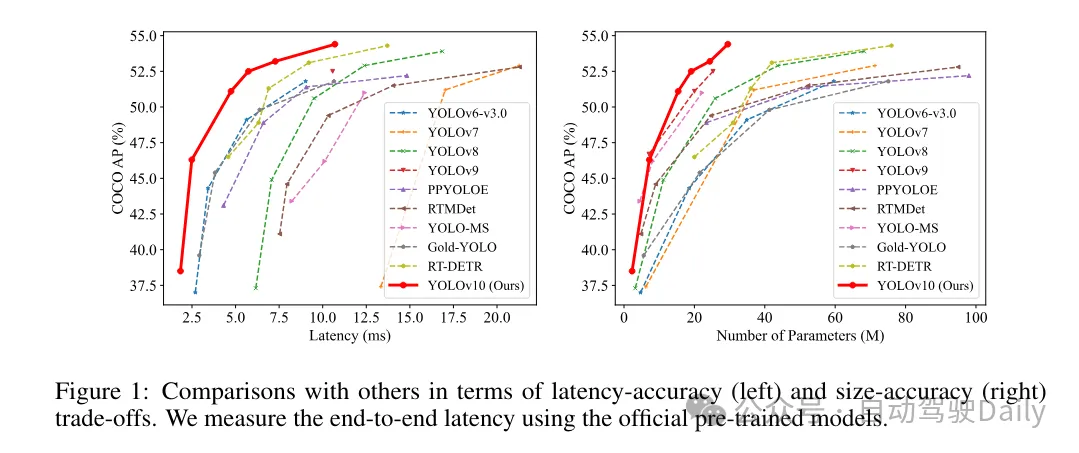
Basierend auf diesen Methoden implementierte der Autor erfolgreich eine Reihe von Echtzeit-End-to-End-Detektoren mit unterschiedlichen Modellgrößen, nämlich YOLOv10-N/S/M/B/L/X. Umfangreiche Experimente mit Standard-Benchmarks zur Objekterkennung zeigen, dass YOLOv10 in der Lage ist, frühere hochmoderne Modelle hinsichtlich der Kompromisse bei der Berechnungsgenauigkeit bei verschiedenen Modellgrößen zu übertreffen. Wie in Abbildung 1 dargestellt, ist YOLOv10-S/X bei ähnlicher Leistung jeweils 1,8-mal bzw. 1,3-mal schneller als RT-DETR R18/R101. Im Vergleich zu YOLOv9-C erreicht YOLOv10-B bei gleicher Leistung eine Latenzreduzierung von 46 %. Darüber hinaus weist YOLOv10 eine extrem hohe Parameternutzungseffizienz auf. YOLOv10-L/X ist 0,3 AP bzw. 0,5 AP höher als YOLOv8-L/X, wobei die Anzahl der Parameter um das 1,8-fache bzw. 2,3-fache reduziert wurde. YOLOv10-M erreicht einen ähnlichen AP wie YOLOv9-M/YOLO-MS und reduziert gleichzeitig die Anzahl der Parameter um 23 % bzw. 31 %.
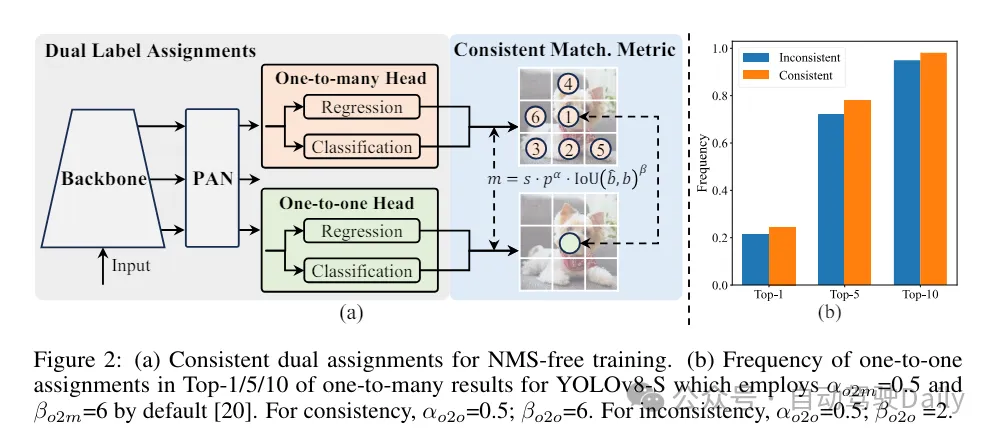
Während des Trainingsprozesses verwenden YOLOs normalerweise TAL (Task Assignment Learning), um jeder Instanz mehrere Proben zuzuweisen. Durch die Verwendung einer Eins-zu-viele-Zuteilungsmethode werden umfangreiche Überwachungssignale generiert, die zur Optimierung und Erzielung einer stärkeren Leistung beitragen. Dies führt jedoch auch dazu, dass YOLOs auf die NMS-Nachbearbeitung (nicht maximale Unterdrückung) angewiesen sind, was zu einer suboptimalen Inferenzeffizienz zum Zeitpunkt der Bereitstellung führt. Während frühere Arbeiten Eins-zu-eins-Matching-Ansätze zur Unterdrückung redundanter Vorhersagen untersucht haben, verursachen diese häufig zusätzlichen Inferenzaufwand oder führen zu einer suboptimalen Leistung. In dieser Arbeit schlagen wir eine NMS-freie Trainingsstrategie vor, die eine doppelte Etikettenzuweisung und konsistente Matching-Metriken verwendet und so eine hohe Effizienz und Wettbewerbsleistung erzielt. Durch diese Strategie benötigen unsere YOLOs kein NMS mehr im Training und erreichen so eine hohe Effizienz und Wettbewerbsleistung.
Effizienzorientiertes Modelldesign. Zu den Komponenten in YOLO gehören der Stamm, Downsampling-Ebenen, Stufen mit Grundbausteinen und der Kopf. Der Rechenaufwand für den Backbone-Teil ist sehr gering, daher führen wir für die anderen drei Teile einen effizienzorientierten Modellentwurf durch.
(1) Leichter Klassifizierungsheader. In YOLO haben der Klassifizierungskopf und der Regressionskopf normalerweise dieselbe Architektur. Sie weisen jedoch erhebliche Unterschiede im Rechenaufwand auf. In YOLOv8-S beträgt beispielsweise die Anzahl der FLOPs und Parameter des Klassifizierungskopfes (5,95 G/1,51 Mio. FLOPs und Parameter) und des Regressionskopfes (2,34 G/0,64 Mio.) das 2,5-fache und das 2,4-fache der Regression Kopf bzw. Durch die Analyse der Auswirkungen von Klassifizierungsfehlern und Regressionsfehlern (siehe Tabelle 6) haben wir jedoch festgestellt, dass der Regressionskopf für die Leistung von YOLO wichtiger ist. Daher können wir den Overhead von Klassifizierungsheadern reduzieren, ohne uns Gedanken über Leistungseinbußen machen zu müssen. Daher übernehmen wir einfach eine leichte Klassifizierungskopfarchitektur, die aus zwei in der Tiefe trennbaren Windungen mit einer Kernelgröße von 3 × 3 besteht, gefolgt von einem 1 × 1-Kernel. Durch die oben genannten Verbesserungen können wir die Architektur des leichten Klassifizierungskopfes vereinfachen, der aus zwei tiefentrennbaren Faltungen mit einer Faltungskerngröße von 3×3 besteht, gefolgt von einem 1×1-Faltungskern. Diese vereinfachte Architektur kann Klassifizierungsfunktionen mit geringerem Rechenaufwand und geringerer Anzahl von Parametern erreichen.
(2) Raumkanal-entkoppeltes Downsampling. YOLO verwendet normalerweise eine reguläre 3×3-Standardfaltung mit einer Schrittweite von 2 und implementiert gleichzeitig räumliches Downsampling (von H × W auf H/2 × W/2) und Kanaltransformation (von C auf 2C). Dies führt zu einem nicht zu vernachlässigenden Rechenaufwand und einer nicht vernachlässigbaren Parameteranzahl. Stattdessen schlagen wir vor, die Vorgänge zur Platzreduzierung und Kanalerweiterung zu entkoppeln, um ein effizienteres Downsampling zu erreichen. Insbesondere wird die punktweise Faltung zunächst zur Modulation der Kanalabmessungen verwendet, und dann wird die Tiefenfaltung zum räumlichen Downsampling verwendet. Dies reduziert den Rechenaufwand auf und die Parameteranzahl auf . Gleichzeitig maximiert es die Informationserhaltung während des Downsamplings und reduziert so die Latenz bei gleichzeitiger Beibehaltung der wettbewerbsfähigen Leistung.
(3) Moduldesign basierend auf Rangführung. YOLOs verwenden normalerweise für alle Phasen dieselben Grundbausteine, wie zum Beispiel den Engpassblock in YOLOv8. Um dieses isomorphe Design von YOLOs gründlich zu untersuchen, verwenden wir den intrinsischen Rang, um die Redundanz jeder Stufe zu analysieren. Konkret wird der numerische Rang der letzten Faltung im letzten Basisblock in jeder Stufe berechnet, wobei die Anzahl der Singulärwerte gezählt wird, die größer als ein Schwellenwert sind. Abbildung 3(a) zeigt die Ergebnisse von YOLOv8 und zeigt, dass tiefe Stufen und große Modelle eher eine höhere Redundanz aufweisen. Diese Beobachtung legt nahe, dass die einfache Anwendung des gleichen Blockdesigns auf alle Stufen nicht optimal ist, um den besten Kompromiss zwischen Kapazität und Effizienz zu erzielen. Um dieses Problem zu lösen, wird ein rangbasiertes Modulentwurfsschema vorgeschlagen, das darauf abzielt, die Komplexität von Stufen, die sich als redundant erweisen, durch kompaktes Architekturdesign zu reduzieren.
Wir stellen zunächst eine kompakte Inverted-Block-Struktur (CIB) vor, die eine kostengünstige Tiefenfaltung für die räumliche Mischung und eine kostengünstige punktweise Faltung für die Kanalmischung verwendet, wie in Abbildung 3(b) dargestellt. Es kann als effektiver Grundbaustein dienen, beispielsweise eingebettet in ELAN-Strukturen (Abbildung 3(b)). Anschließend wird eine rangbasierte Modulzuteilungsstrategie empfohlen, um eine optimale Effizienz zu erreichen und gleichzeitig die Wettbewerbsfähigkeit aufrechtzuerhalten. Ordnen Sie bei einem gegebenen Modell insbesondere alle Stufen entsprechend der aufsteigenden Reihenfolge ihres intrinsischen Rangs. Untersuchen Sie die Leistungsänderungen weiter, nachdem Sie die Grundblöcke der führenden Stufe durch CIB ersetzt haben. Wenn es im Vergleich zum gegebenen Modell keine Leistungseinbußen gibt, ersetzen wir die nächste Stufe weiter, andernfalls stoppen wir den Prozess. Dadurch können wir adaptive Kompaktblockdesigns in verschiedenen Phasen und Modellgrößen implementieren und so eine höhere Effizienz ohne Leistungseinbußen erzielen.
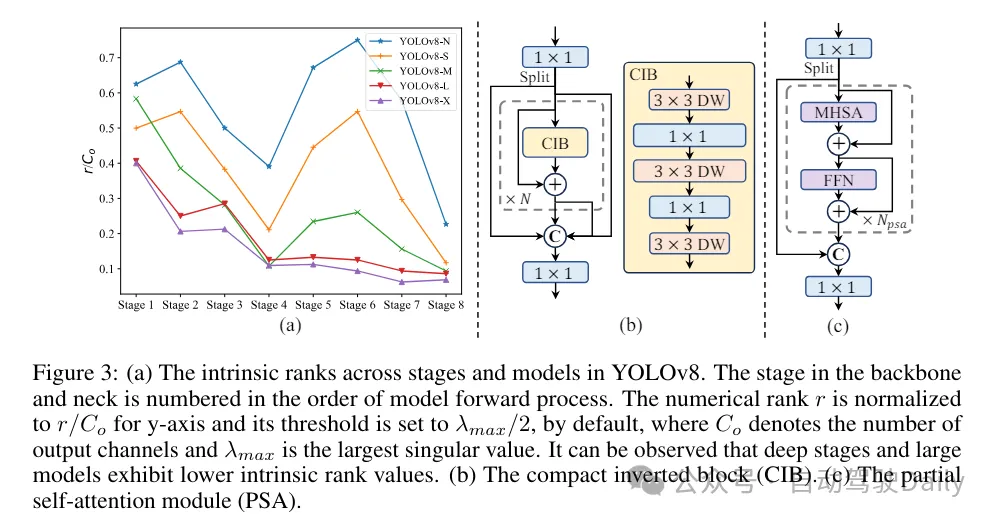
Basierend auf präzisionsorientiertem Modelldesign. In dem Artikel werden Faltungs- und Selbstaufmerksamkeitsmechanismen großer Kernel weiter untersucht, um ein präzisionsbasiertes Design zu erreichen, mit dem Ziel, die Leistung bei minimalen Kosten zu verbessern.
(1) Große Kernelfaltung. Die Verwendung tiefer Faltungen mit großem Kernel ist eine effektive Möglichkeit, das Empfangsfeld zu erweitern und die Fähigkeiten des Modells zu verbessern. Wenn man sie jedoch einfach in allen Phasen ausnutzt, kann dies zu einer Verunreinigung der flachen Merkmale führen, die zur Erkennung kleiner Objekte verwendet werden, und gleichzeitig zu einem erheblichen I/O-Overhead und einer erheblichen Latenz in der hochauflösenden Phase führen. Daher schlagen die Autoren vor, tiefe Faltungen mit großem Kernel im Inter-Stage-Informationsblock (CIB) der tiefen Stufe zu verwenden. Hier wird die Kernelgröße der zweiten 3×3-Tiefenfaltung in CIB auf 7×7 erhöht. Darüber hinaus wird die Technologie der strukturellen Neuparametrisierung eingesetzt, um einen weiteren 3×3-Tiefenfaltungszweig einzuführen, um das Optimierungsproblem zu lindern, ohne den Inferenzaufwand zu erhöhen. Darüber hinaus erweitert sich mit zunehmender Modellgröße das Empfangsfeld auf natürliche Weise, und die Vorteile der Verwendung großer Kernelfaltungen nehmen allmählich ab. Daher werden Faltungen mit großem Kern nur in kleinen Modellmaßstäben eingesetzt.
(2) Partielle Selbstaufmerksamkeit (PSA). Der Selbstaufmerksamkeitsmechanismus wird aufgrund seiner hervorragenden globalen Modellierungsfähigkeiten häufig bei verschiedenen visuellen Aufgaben eingesetzt. Es weist jedoch eine hohe Rechenkomplexität und einen hohen Speicherbedarf auf. Um dieses Problem zu lösen, schlägt der Autor angesichts der allgegenwärtigen Aufmerksamkeitskopfredundanz ein effizientes PSA-Moduldesign (Partial Self Attention) vor, wie in Abbildung 3 (c) dargestellt. Insbesondere werden die Merkmale nach der 1×1-Faltung durch Kanäle gleichmäßig in zwei Teile aufgeteilt. Nur ein Teil der Funktionen wird in den NPSA-Block eingegeben, der aus dem Multi-Head-Self-Attention-Modul (MHSA) und dem Feed-Forward-Netzwerk (FFN) besteht. Anschließend werden die beiden Teile der Merkmale durch 1×1-Faltung gespleißt und verschmolzen. Legen Sie außerdem die Dimensionen von Abfragen und Schlüsseln in MHSA auf die Hälfte der Werte fest und ersetzen Sie LayerNorm durch BatchNorm für eine schnelle Schlussfolgerung. PSA wird erst nach Stufe 4 mit der niedrigsten Auflösung platziert, um übermäßigen Overhead zu vermeiden, der durch die quadratische Rechenkomplexität der Selbstaufmerksamkeit verursacht wird. Auf diese Weise können globale Repräsentationslernfähigkeiten mit geringem Rechenaufwand in YOLOs integriert werden, wodurch die Fähigkeiten des Modells deutlich verbessert und die Leistung verbessert werden.
Experimenteller Vergleich
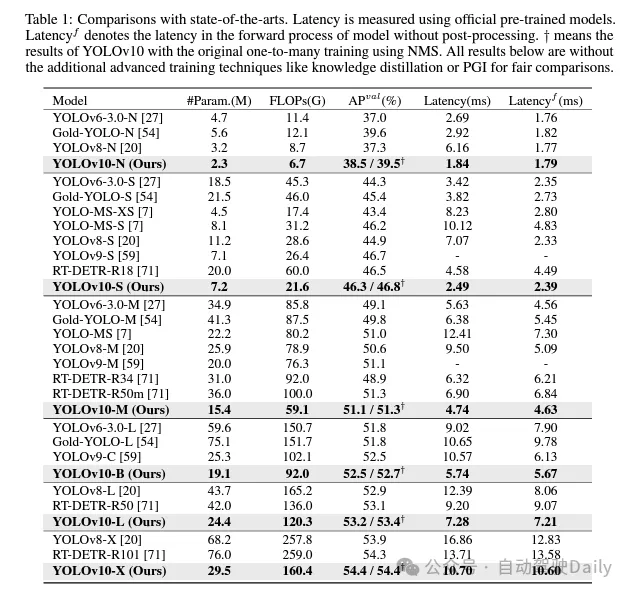
Ich werde hier nicht zu sehr auf die Einführung eingehen, sondern nur auf die Ergebnisse! ! ! Die Latenz wird reduziert und die Leistung steigt weiter.
Das obige ist der detaillierte Inhalt vonYOLOv10 ist da! Echte End-to-End-Zielerkennung in Echtzeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie verwende ich C++ für eine leistungsstarke Bildverfolgung und Zielerkennung?
- Tesla-Roboter voll entwickelt! Wahrnehmung, Gehirn und motorische Steuerungsfähigkeiten werden verbessert und die End-to-End-Lösung zeigt erste Ergebnisse.
- Präzise Merkmalsausrichtung zur Verbesserung der multimodalen 3D-Objekterkennung: Anwendung von GraphAlign
- Verwendung von Dimensionsreduktionsalgorithmen zur Zielerkennung: Tipps und Schritte
- Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung