
Heim >Technologie-Peripheriegeräte >KI >Auf dem Weg zum „Closed Loop' |. PlanAgent: Neues SOTA für die Closed-Loop-Planung des autonomen Fahrens auf Basis von MLLM!
Auf dem Weg zum „Closed Loop' |. PlanAgent: Neues SOTA für die Closed-Loop-Planung des autonomen Fahrens auf Basis von MLLM!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-08 21:30:27583Durchsuche
Das Deep-Reinforcement-Learning-Team des Instituts für Automatisierung der Chinesischen Akademie der Wissenschaften hat zusammen mit Li Auto und anderen ein neues Closed-Loop-Planungsrahmenwerk für autonomes Fahren vorgeschlagen, das auf einem multimodalen großen Sprachmodell basiertMLLM – PlanAgent. Bei dieser Methode werden die Szene aus der Vogelperspektive und diagrammbasierte Textaufforderungen als Eingabe betrachtet. Dabei werden die Fähigkeiten des multimodalen Verständnisses und des gesunden Menschenverstandes des multimodalen großen Sprachmodells genutzt, um hierarchische Überlegungen vom Szenenverständnis bis zur Generierung durchzuführen von horizontalen und vertikalen Bewegungsanweisungen und generieren Sie außerdem die vom Planer benötigten Anweisungen. Die Methode wird im groß angelegten und anspruchsvollen nuPlan-Benchmark getestet und Experimente zeigen, dass PlanAgent sowohl in regulären als auch in Long-Tail-Szenarien eine State-of-the-Art-Leistung (SOTA) erreicht. Im Vergleich zu herkömmlichen LLM-Methoden (Large Language Model) beträgt die Menge der von PlanAgent benötigten Szenenbeschreibungs-Tokens nur etwa 1/3.
Papierinformationen
- Papiertitel: PlanAgent: A Multi-modal Large Language Agent for Closed-loop Vehicle Motion Planning
- Veröffentlichungseinheiten des Papiers: Institute of Automation, Chinesische Akademie der Wissenschaften, Li Auto, Tsinghua Universität, Beijing Aerospace University
- Papieradresse:https://arxiv.org/abs/2406.01587


1 Einführung
Als eines der Kernmodule des autonomen Fahrens ist das Ziel Die Aufgabe der Bewegungsplanung besteht darin, eine optimale Flugbahn für Sicherheit und Komfort zu erstellen. Regelbasierte Algorithmen wie der PDM-Algorithmus [1] eignen sich gut für die Bewältigung allgemeiner Szenarien, sind jedoch bei Long-Tail-Szenarien, die komplexere Fahrvorgänge erfordern, oft schwierig zu bewältigen [2]. Lernbasierte Algorithmen [2,3] sind in Long-Tail-Situationen oft übergeeignet, was zu einer Leistung in nuPlan führt, die nicht so gut ist wie die der regelbasierten Methode PDM.
Die Entwicklung großer Sprachmodelle hat in jüngster Zeit neue Möglichkeiten für die autonome Fahrplanung eröffnet. Einige neuere Forschungsarbeiten versuchen, die leistungsstarken Argumentationsfähigkeiten großer Sprachmodelle zu nutzen, um die Planungs- und Steuerungsfähigkeiten autonomer Fahralgorithmen zu verbessern. Allerdings stießen sie auf einige Probleme: (1) Die experimentelle Umgebung basierte nicht auf einem realen Szenario einer geschlossenen Umgebung. (2) Zur Darstellung von Kartendetails oder Bewegungsstatus wurden mehrere Koordinatennummern verwendet, was die Anzahl der erforderlichen Token erheblich erhöhte. (3) ) Es ist schwierig, die Sicherheit zu gewährleisten, wenn Flugbahnpunkte direkt von einem großen Sprachmodell generiert werden. Um die oben genannten Herausforderungen anzugehen, schlägt dieses Papier die PlanAgent-Methode vor.
2 Methode
Das PlanAgent-Framework eines auf MLLM basierenden Closed-Loop-Planungsagenten ist in Abbildung 1 dargestellt. In diesem Dokument werden drei Module zur Lösung komplexer Probleme beim autonomen Fahren entworfen:
- Modul zur Extraktion von Szeneninformationen (Umgebungstransformationsmodul): Um eine effiziente Darstellung von Szeneninformationen zu erreichen, wurde ein Umgebungsinformationsextraktionsmodul entwickelt, das multimodale Eingaben mit Spurinformationen extrahieren kann.
- Begründungsmodul: Um Szenenverständnis und vernünftiges Denken zu erreichen, wurde ein Begründungsmodul entwickelt, das das multimodale große Sprachmodell MLLM verwendet, um vernünftigen und sicheren Planercode zu generieren.
- Reflexionsmodul: Um eine sichere Planung zu gewährleisten, wird ein Reflexionsmechanismus entworfen, der den Planer durch Simulation überprüfen und unzumutbare MLLM-Vorschläge herausfiltern kann.
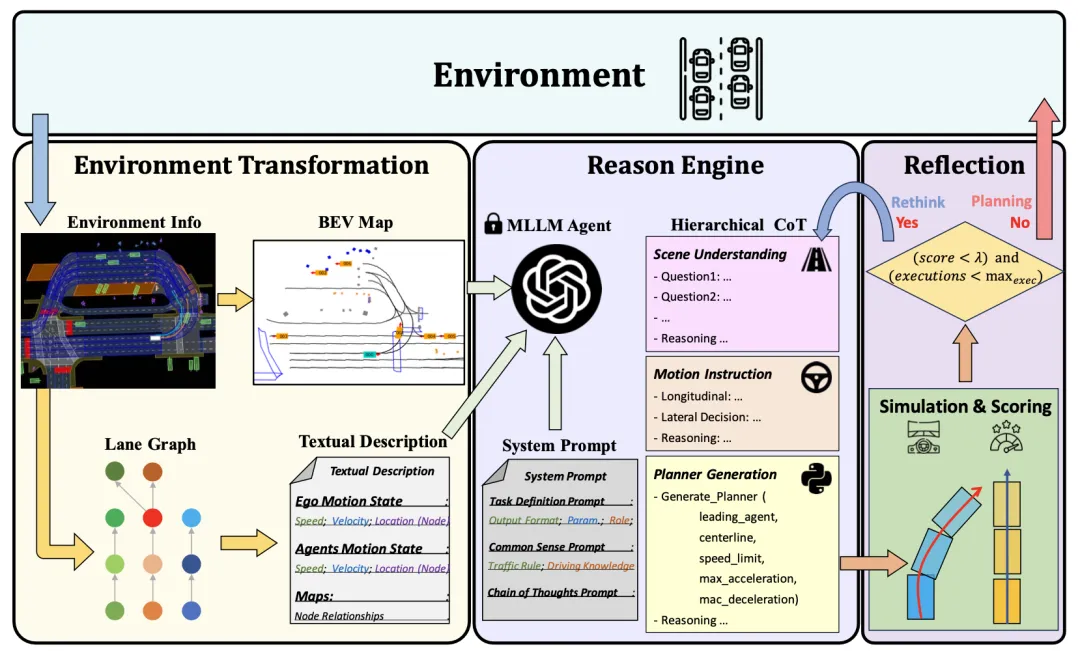
Abbildung 1 Das Gesamtgerüst von PlanAgent, einschließlich des Moduls zur Extraktion/Begründung/Reflexion von Szeneninformationen
2.1 Modul zur Extraktion von Umgebungsinformationen
Die Eingabeaufforderungswörter (Eingabeaufforderung) im großen Sprachmodell generieren eine Ausgabe Dafür hat Qualität einen wichtigen Einfluss. Um die Generierungsqualität von MLLM zu verbessern, ist das Szeneninformationsextraktionsmodul in der Lage, Szenenkontextinformationen zu extrahieren und sie in eine Bild- und Textdarstellung aus der Vogelperspektive (BEV) umzuwandeln, sodass sie mit der Eingabe von MLLM konsistent ist. Zunächst werden in diesem Artikel Szeneninformationen in BEV-Bilder (Bird Escape) umgewandelt, um die Fähigkeit von MLLM zu verbessern, die globale Szene zu verstehen. Gleichzeitig müssen die Straßeninformationen grafisch dargestellt werden, wie in Abbildung 2 dargestellt. Auf dieser Grundlage werden wichtige Fahrzeugbewegungsinformationen extrahiert, sodass sich MLLM auf den Bereich konzentrieren kann, der für die eigene Position am relevantesten ist.
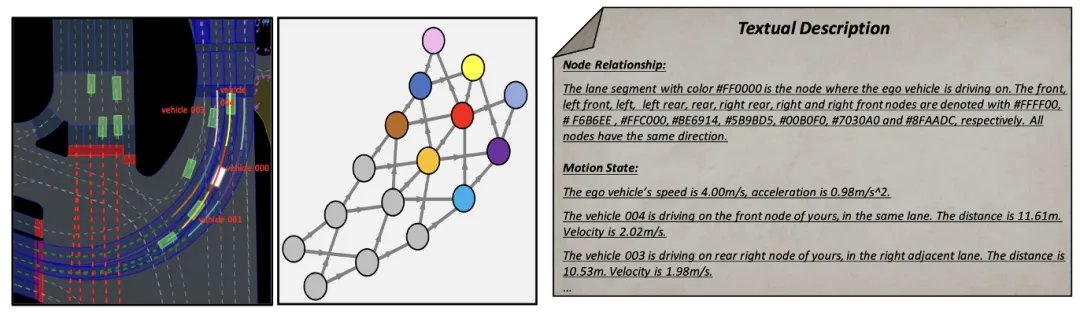
Abbildung 2 Beschreibung der Textaufforderung basierend auf der Diagrammdarstellung
2.2 Reasoning-Modul
Wie man die Argumentationsfähigkeit großer Sprachmodelle in den autonomen Fahrplanungsprozess einführt und ein Planungssystem mit gesunden Menschenverstandsfähigkeiten realisiert, ist eine Schlüsselfrage. Die in diesem Artikel entwickelte Methode kann Benutzernachrichten und vordefinierte Systemnachrichten mit aktuellen Szeneninformationen als Eingabe verwenden und durch mehrere Argumentationsrunden in der hierarchischen Denkkette den Planercode des intelligenten Fahrermodells (IDM) generieren. Dadurch kann PlanAgent die leistungsstarken Argumentationsfunktionen von MLLM durch kontextbezogenes Lernen in Planungsaufgaben für autonomes Fahren einbetten.
Unter anderem umfasst die Benutzernachricht die BEV-Kodierung und die Bewegungsinformationen des umgebenden Fahrzeugs, die auf der Grundlage einer Diagrammdarstellung extrahiert werden. Systemmeldungen umfassen Aufgabendefinition, gesundes Menschenverstandswissen und Schritte der Denkkette, wie in Abbildung 3 dargestellt. Abbildung 3 Vorlage für Systemaufforderungen . In PlanAgent werden Parametercodes für Fahrzeugverfolgung, Mittellinie, Geschwindigkeitsbegrenzung, maximale Beschleunigung und maximale Verzögerung generiert. Anschließend wird die momentane Beschleunigung in einer bestimmten Szene von IDM generiert und schließlich wird eine Flugbahn generiert.

2.3 Reflexionsmodul
Durch die beiden oben genannten Module werden die Verständnis- und Argumentationsfähigkeiten von MLLM für die Szene gestärkt. Allerdings stellt die Illusion von MLLM immer noch eine Herausforderung für die Sicherheit des autonomen Fahrens dar. Inspiriert durch den Entscheidungsprozess des Menschen, „zweimal nachzudenken, bevor man springt“, fügt dieser Artikel dem Algorithmusdesign einen Reflexionsmechanismus hinzu. Simulieren Sie den von MLLM generierten Planer und bewerten Sie die Fahrbewertung des Planers anhand von Indikatoren wie Kollisionswahrscheinlichkeit, Fahrstrecke und Komfort. Wenn die Punktzahl unter einem bestimmten Schwellenwert τ liegt, weist dies darauf hin, dass der von MLLM generierte Planer unzureichend ist, und MLLM wird aufgefordert, den Planer neu zu generieren.
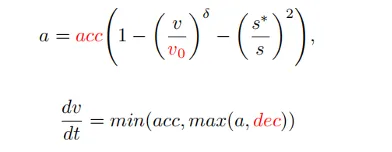
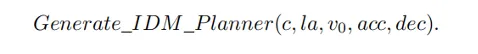
In diesem Artikel werden Closed-Loop-Planungsexperimente mit nuPlan [4] durchgeführt, einer Closed-Loop-Planungsplattform für große reale Szenen, um die Leistung von PlanAgent zu bewerten wie folgt.
3.1 Hauptexperiment
Tabelle 1 Vergleich zwischen PlanAgent und anderen Algorithmen auf nuPlans val14 und testharten Benchmarks
Wie in Tabelle 1 gezeigt, wird in diesem Artikel der Vergleich mit PlanAgent vorgeschlagen Drei Kategorien hochmoderner Algorithmen und Tests auf den beiden Benchmarks von nuPlan, val14 und test-hard. PlanAgent zeigt im Vergleich zu anderen Methoden wettbewerbsfähige und verallgemeinerbare Ergebnisse.
Wettbewerbsfähige Ergebnisse: Beim Common-Szenario-Val14-Benchmark übertrifft PlanAgent andere regelbasierte, lernbasierte und auf großen Sprachmodellen basierende Methoden und erzielt sowohl beim NR-CLS- als auch beim R-CLS-Score die besten Ergebnisse.
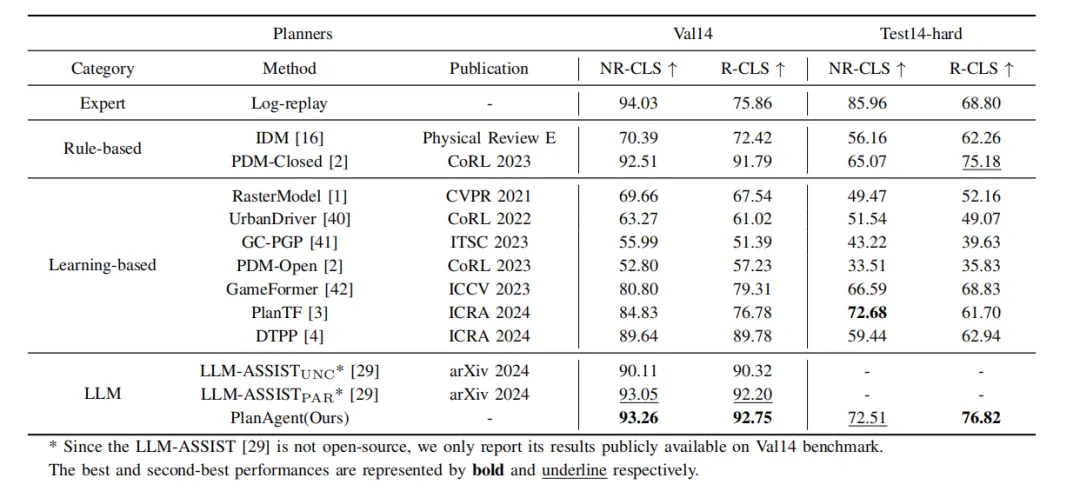 Verallgemeinerbare Ergebnisse: Weder die regelbasierten Methoden, die durch PDM-Closed[1] dargestellt werden, noch die lernbasierten Methoden, die durch planTF[2] dargestellt werden, können auf val14 eine gute Leistung erbringen und gleichzeitig eine hohe Testintensität aufweisen. Im Vergleich zu diesen beiden Arten von Methoden kann PlanAgent Long-Tail-Szenarien bewältigen und gleichzeitig die Leistung in gängigen Szenarien sicherstellen.
Verallgemeinerbare Ergebnisse: Weder die regelbasierten Methoden, die durch PDM-Closed[1] dargestellt werden, noch die lernbasierten Methoden, die durch planTF[2] dargestellt werden, können auf val14 eine gute Leistung erbringen und gleichzeitig eine hohe Testintensität aufweisen. Im Vergleich zu diesen beiden Arten von Methoden kann PlanAgent Long-Tail-Szenarien bewältigen und gleichzeitig die Leistung in gängigen Szenarien sicherstellen.
Tabelle 2 Vergleich der Token, die von verschiedenen Methoden zur Beschreibung von Szenarien verwendet werden
- Gleichzeitig verwendet PlanAgent weniger Token als andere große modellbasierte Methoden, wie in Tabelle 2 gezeigt, und erfordert wahrscheinlich nur GPT 1/3 von -Driver[5] oder LLM-ASSIST[6]. Dies zeigt, dass PlanAgent die Szene mit weniger Token effektiver beschreiben kann. Dies ist besonders wichtig für die Verwendung großer Closed-Source-Sprachmodelle.
3.2 Ablationsexperiment
Tabelle 3 Ablationsexperiment verschiedener Teile im Szenenextraktionsmodul 
Tabelle 4 Ablationsexperimente verschiedener Teile in der hierarchischen Denkkette
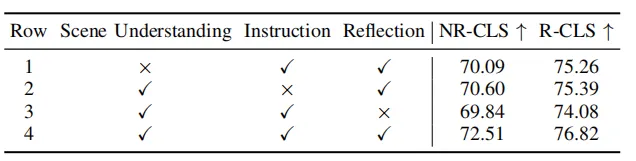
Wie in Tabelle 3 und Tabelle 4 gezeigt, wurden in diesem Artikel Ablationsexperimente an verschiedenen Teilen des Szeneninformationsextraktionsmoduls und des Argumentationsmoduls durchgeführt. und das Experiment bewies die Wirksamkeit und Notwendigkeit einzelner Module. Das Verständnis von MLLM für die Szene kann durch BEV-Bild- und Diagrammdarstellung verbessert werden, und die Argumentationsfähigkeit von MLLM für die Szene kann durch hierarchische Denkketten verbessert werden.
Tabelle 5 Experimente von PlanAgent mit verschiedenen Sprachmodellen
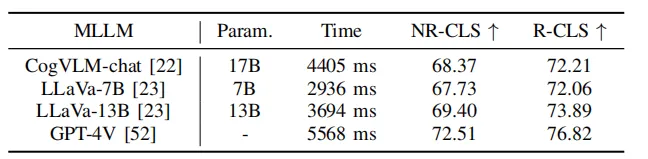
Gleichzeitig werden in diesem Artikel, wie in Tabelle 5 gezeigt, einige große Open-Source-Sprachmodelle zum Testen verwendet. Experimentelle Ergebnisse zeigen, dass PlanAgent beim Test-Hard-NR-CLS-Benchmark mit verschiedenen großen Sprachmodellen um 4,1 %, 5,1 % bzw. 6,7 % höhere Fahrwerte erzielen kann als PDM-Closed. Dies zeigt die Kompatibilität von PlanAgent mit verschiedenen multimodalen großen Sprachmodellen.
3.3 Visuelle Analyse
Kreisverkehrszene
PDM wählt die Außenspur als Mittellinie, und das Fahrzeug fährt auf der Außenspur und bleibt beim Zusammenfahren des Fahrzeugs stecken. PlanAgent stellt fest, dass ein Fahrzeug zusammenfährt, gibt einen angemessenen Befehl zum Wechseln der linken Spur aus und generiert eine Querbewegung, um die innere Spur des Kreisverkehrs als Mittellinie auszuwählen, und das Fahrzeug fährt auf der inneren Spur.

Kreuzungsstopp-Parkszene
PDM hat die Ampelkategorie als Autofolgekategorie ausgewählt. PlanAgent gibt sinnvolle Anweisungen aus und wählt die Haltelinie als Fahrzeugverfolgungskategorie aus.
4 Fazit
In diesem Artikel wird ein neues MLLM-basiertes Closed-Loop-Planungsrahmenwerk für autonomes Fahren namens PlanAgent vorgeschlagen. Diese Methode führt ein Szeneninformationsextraktionsmodul ein, um BEV-Bilder zu extrahieren und die Bewegungsinformationen umliegender Fahrzeuge basierend auf der grafischen Darstellung der Straße zu extrahieren. Gleichzeitig wird ein Argumentationsmodul mit hierarchischer Struktur vorgeschlagen, um MLLM dabei zu unterstützen, Szeneninformationen zu verstehen, Bewegungsanweisungen zu generieren und schließlich Planercode zu generieren. Darüber hinaus imitiert PlanAgent auch die menschliche Entscheidungsfindung zur Reflexion und plant neu, wenn der Trajektorienwert unter dem Schwellenwert liegt, um die Sicherheit der Entscheidungsfindung zu erhöhen. Der PlanAgent für autonomes Fahren mit geschlossenem Regelkreis, der auf dem multimodalen Großmodell basiert, hat beim nuPlan-Benchmark die SOTA-Leistung bei der Planung mit geschlossenem Regelkreis erreicht.
Das obige ist der detaillierte Inhalt vonAuf dem Weg zum „Closed Loop' |. PlanAgent: Neues SOTA für die Closed-Loop-Planung des autonomen Fahrens auf Basis von MLLM!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was ist ein geschlossenes Regelsystem?
- Tesla nutzt künstliche Intelligenz, um das autonome Fahren zu verbessern
- Ein Überblick über die drei gängigen Chiparchitekturen für autonomes Fahren in einem Artikel
- Wie entwickelt man autonomes Fahren und das Internet der Fahrzeuge in PHP?
- Waymo und Uber gestalten ihre Partnerschaft neu, um gemeinsam die Anwendung autonomer Fahrtechnologie im Bereich Online-Ride-Hailing zu erforschen