Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der Erstautor dieser Arbeit, Zhu Qinfeng, ist ein Doktorand im ersten Jahr, der gemeinsam von der Xi'an Jiaotong-Liverpool University ausgebildet wurde Er ist Professor an der University of Liverpool und sein Betreuer ist Fan Lei Associate Professor. Seine Forschungsschwerpunkte sind semantische Segmentierung, multimodale Informationsfusion, 3D-Vision, hyperspektrale Bilder und Datenverbesserung. Diese Forschungsgruppe rekrutiert rund um die Uhr Doktoranden. E-Mail-Anfragen sind willkommen. E-Mail: qinfeng.zhu21@student.xjtlu.edu.cnHomepage: https://zhuqinfeng1999.github.io/Dieser Artikel ist eine Rezension von Pattern, dem Top-Journal im Bereich der Mustererkennung. Das neueste Übersichtspapier von Recognition 2024: Interpretation von „Advancements in Point Cloud Data Augmentation for Deep Learning: A Survey“. Dieser Artikel wurde von Zhu Qinfeng, Fan Lei und Weng Ningxin von der Xi'an Jiaotong-Liverpool University verfasst. Diese Rezension fasst erstmals umfassende Forschungsarbeiten im Zusammenhang mit der Verbesserung von Punktwolkendaten zusammen.
Deep Learning ist zu einer der gängigen und effektiven Methoden für Punktwolkenanalyseaufgaben wie Erkennung, Segmentierung und Klassifizierung geworden. Um eine Überanpassung beim Training von Deep-Learning-Modellen zu reduzieren und insbesondere die Modellleistung zu verbessern, wenn die Menge oder Vielfalt der Trainingsdaten begrenzt ist, ist die Datenerweiterung oft von entscheidender Bedeutung. Obwohl verschiedene Methoden zur Erweiterung von Punktwolkendaten in verschiedenen Punktwolkenverarbeitungsaufgaben weit verbreitet sind, wurde noch keine systematische Übersicht oder Diskussion dieser Methoden veröffentlicht.
Daher untersucht dieser Artikel diese Methoden und kategorisiert sie in einen Klassifizierungsrahmen
, der grundlegende und spezifische Methoden zur Punktwolkendatenerweiterung umfasst. Durch eine umfassende Bewertung dieser Verbesserungsmethoden identifiziert dieses Papier deren Potenzial und Grenzen und bietet eine nützliche Referenz für die Auswahl geeigneter Verbesserungsmethoden.
Darüber hinaus untersucht dieser Artikel mögliche Richtungen für zukünftige Forschung
. Diese Umfrage trägt dazu bei, einen umfassenden Überblick über die aktuelle Forschung zur Punktwolkendatenerweiterung zu geben und deren breitere Anwendung und Entwicklung zu fördern.  Freier Zugang: https://authors.elsevier.com/c/1j3TW77nKoLGMarXiv: https://arxiv.org/pdf/2308.12113Autoren-Homepage: https://zhuqinfeng1999.github.io Abbildung 1. Klassifizierung von Methoden zur Verbesserung von Punktwolkendaten. Punktwolken-Datenerweiterung
Freier Zugang: https://authors.elsevier.com/c/1j3TW77nKoLGMarXiv: https://arxiv.org/pdf/2308.12113Autoren-Homepage: https://zhuqinfeng1999.github.io Abbildung 1. Klassifizierung von Methoden zur Verbesserung von Punktwolkendaten. Punktwolken-Datenerweiterung
Im Bereich Deep Learning wird die Datenerweiterung häufig verwendet, wenn der verfügbare Trainingsdatensatz begrenzt ist. Dazu gehört die Durchführung einer bestimmten Reihe von Vorgängen zur Änderung oder Erweiterung der Originaldaten, wodurch die Größe und Vielfalt des Datensatzes erhöht wird. Datenerweiterung wird beim Training von Deep-Learning-Netzwerken fast immer als ideal angesehen, da ein hochwertiger erweiterter Datensatz dazu beiträgt, die Robustheit des Netzwerks zu verbessern, die Generalisierungsfähigkeiten zu verbessern und Überanpassungen zu reduzieren. Auf dem Gebiet der Bilddatenanreicherung und der Textdatenanreicherung ist eine umfassende Entwicklung zu beobachten.
In zahlreichen kürzlich veröffentlichten Forschungsarbeiten zu Punktwolkenverarbeitungsaufgaben haben Forscher verschiedene Methoden zur Verbesserung von Punktwolkendaten untersucht. Das breite Spektrum dieser Methoden stellt Forscher vor Herausforderungen bei der Auswahl geeigneter Methoden. Daher ist es von großem Wert, diese Methoden systematisch zu untersuchen und sie in verschiedene Gruppen einzuteilen.
Dieses Papier präsentiert eine umfassende Übersicht über Methoden zur Punktwolkendatenerweiterung.
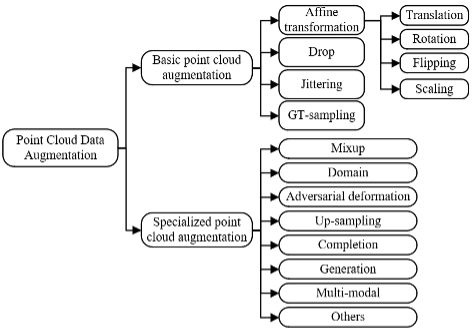
Basierend auf unserer Umfrage schlagen wir ein Klassifizierungssystem dieser Verbesserungsmethoden vor, wie in Abbildung 1 dargestellt.
Verbesserungsmethoden können in zwei Hauptkategorien unterteilt werden: grundlegende Punktwolkenverbesserung und spezifische Punktwolkenverbesserung, die den typischen Klassifizierungsmethoden der Bildverbesserung ähneln.
Grundlegende Punktwolkenerweiterung bezieht sich auf Methoden, die konzeptionell einfach und universell für verschiedene Aufgaben und Anwendungskontexte sind, was durch ihre weit verbreitete Verwendung in Kombination mit anderen Methoden in der Umfrageliteratur belegt wird. Spezifische Punktwolkenverbesserung bezieht sich auf Methoden, die normalerweise entwickelt werden, um bestimmte Herausforderungen zu lösen oder auf bestimmte Anwendungsumgebungen zu reagieren. In den meisten Fällen sind spezifische Punktwolkenverbesserungen rechentechnisch komplexer als Basisverbesserungen, abhängig von den Implementierungsdetails der Verbesserungsmethode. Die Unterkategorien in unserem vorgeschlagenen Klassifizierungssystem stellen eine Zusammenfassung verschiedener Methoden dar, die in der Literatur zur Verbesserung von Punktwolkendaten verwendet wurden oder möglicherweise zur Verbesserung von Punktwolkendaten eingesetzt werden können. Die Hauptbeiträge dieser Rezension sind wie folgt:
- Dies ist die erste Rezension, die Methoden zur Verbesserung von Punktwolkendaten umfassend untersucht und die neuesten Fortschritte bei der Verbesserung von Punktwolkendaten abdeckt. Basierend auf den Merkmalen des Verbesserungsvorgangs schlagen wir ein Klassifizierungssystem für Methoden zur Verbesserung von Punktwolkendaten vor.
- Diese Studie fasst verschiedene Methoden zur Punktwolkendatenerweiterung zusammen, diskutiert ihre Anwendungen bei typischen Punktwolkenverarbeitungsaufgaben wie Erkennung, Segmentierung und Klassifizierung und liefert Vorschläge für mögliche zukünftige Forschung.
Grundlegende PunktwolkenverbesserungAffine Transformation beinhaltet die Transformation des affinen Raums, wodurch Kollinearität und Entfernungsskala erhalten bleiben. Zu den bei der Bilddatenverbesserung häufig verwendeten affinen Transformationsmethoden gehören Skalierung, Translation, Rotation, Spiegelung und Scherung. Ebenso können affine Transformationen auch auf die Erweiterung von Punktwolkendaten angewendet werden. Zu den typischen Methoden gehören Translation, Rotation, Spiegelung und Skalierung. Diese Methoden werden häufig zur Generierung zusätzlicher neuer Trainingsdaten eingesetzt. Diese Operationen können auf den gesamten Punktwolkendatensatz oder auf ausgewählte Instanzen in den Punktwolkendaten unter Verwendung spezifischer Strategien (Instanzen beziehen sich auf semantische Objekte wie das in Abbildung 2(a) gezeigte Fahrzeug) angewendet oder auf angewendet werden einen bestimmten Teil der ausgewählten Instanz. Allerdings können durch affine Transformation verbesserte Daten mit Problemen wie Informationsverlust oder unangemessener Semantik konfrontiert sein. Die spezifischen Operationen und die Diskussion dieser affinen Transformationen werden im Artikel detailliert beschrieben.射 Abbildung 2. Beispiele zur Verbesserung der Punktwolkendaten durch Nachahmungstransformation: (a) ursprüngliche Punktwolkendaten, (b) Übergangsfahrzeug, (C) rotierende Fahrzeuge, (D) zoomendes Fahrzeug, (e) Szene umdrehen. Verwerfen-Verbesserung bezieht sich auf das Verwerfen einiger Datenpunkte in den Punktwolkendaten, wie in Abbildung 3 dargestellt. Die Auswahl der Entnahmepunkte wird durch die konkrete Strategie bestimmt. Die verworfenen Punkte können Teil der gesamten Punktwolkendaten oder zufällig ausgewählte Punkte in der Szene sein. Durch die Dropout-Erweiterung werden Deep-Learning-Modelle robuster gegenüber fehlenden oder unvollständigen Daten, die verdeckte oder teilweise sichtbare Szenen darstellen. Es verhindert außerdem, dass Deep-Learning-Modelle zu sehr von bestimmten Datenpunkten im Trainingsdatensatz abhängig werden. Der Verlust übermäßiger oder kritischer Punktwolkeninformationen kann jedoch zu unrealistischen Darstellungen realer Objekte in den Trainingsdaten führen und das Training von Deep-Learning-Modellen beeinträchtigen. Verschiedene Methoden und Diskussionen, die auf der Dropout-Verstärkung basieren, werden im Artikel detailliert beschrieben.弃 Abbildung 3. Beispiel für die Verstärkung einer verstärkten Verbesserung: (A) Original-Punktwolkendaten, (b) zufällige Verwerfung der Verbesserungspunktwolke, (C) Verwerfen eines Teils der Verbesserungspunktwolke. Jitter bezieht sich auf die Anwendung kleiner Störungen oder Rauschen auf die Position eines einzelnen Punkts in einer Punktwolke, wie in Abbildung 4 dargestellt. Verschiedene Methoden und Diskussionen, die auf der Jitter-Verstärkung basieren, werden im Artikel detailliert beschrieben. 
增 Abbildung 4. Beispiel für die Beurteilung einer Verbesserung: (a) ursprüngliche Punktwolkendaten, (b) durch Jitter verbesserte Punktwolkendaten.
In Punktwolkendatensätzen auf Szenenebene, wie z. B. autonomen Fahrszenen im Freien, sind die gekennzeichneten Instanzen normalerweise begrenzt. In diesem Fall wird GT-Sampling zu einer einfachen und effektiven Methode zur Datenerweiterung.
GT-Stichprobe bezieht sich auf den Vorgang des Hinzufügens gekennzeichneter Instanzen zum Trainingsdatensatz. Wie in Abbildung 5 dargestellt, stammen die gekennzeichneten GT-Instanzen aus demselben Trainingsdatensatz oder anderen Datensätzen. GT-Sampling eignet sich normalerweise für Punktwolkendatensätze auf Szenenebene, während Punktwolkendatensätze auf Instanzebene wie ShapeNet normalerweise nicht berücksichtigt werden. Verschiedene Methoden und Diskussionen, die auf der GT-Sampling-Verbesserung basieren, werden im Artikel detailliert beschrieben.
. (b) Semantisch unvernünftiges GT-Sampling, ein Auto befindet sich innerhalb der Gebäudewand und das andere innerhalb der Bäume.
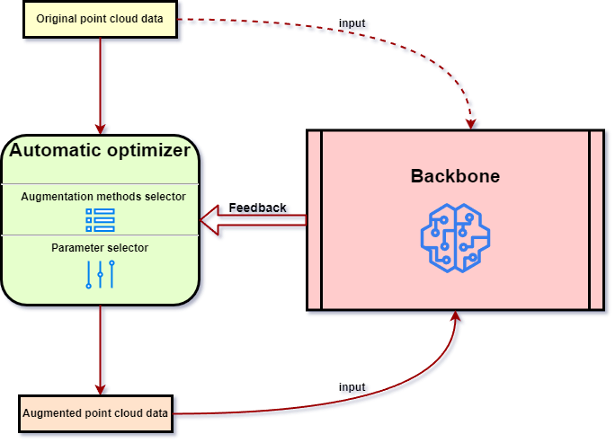
Darüber hinaus werden in diesem Artikel auch Strategien vorgestellt, die auf grundlegende Methoden zur Verbesserung von Punktwolkendaten angewendet werden, z. B. Patch-basierte Strategien und automatische Optimierungsstrategien (siehe Abbildung 6). In diesem Artikel werden typische grundlegende Methoden zur Punktwolkenverbesserung zusammengefasst, wie in Tabelle 1 dargestellt. Abbildung 6. Gemeinsamer Prozess der automatischen Optimierung. Tabelle 1. Repräsentative grundlegende Methoden zur Punktwolkenverbesserung.
Spezifische PunktwolkenverbesserungSpezifische Punktwolkenverbesserungsmethoden sind in der Regel darauf ausgelegt, eine bestimmte Herausforderung oder ein bestimmtes Anwendungsszenario zu lösen. Spezifische Punktwolkenverbesserungen umfassen: Mixup-Verbesserung, Domänenverbesserung, kontroverse Verformungsverbesserung, Upsampling-Verbesserung, Vervollständigungsverbesserung, generative Verbesserung, multimodale Verbesserung und andere. 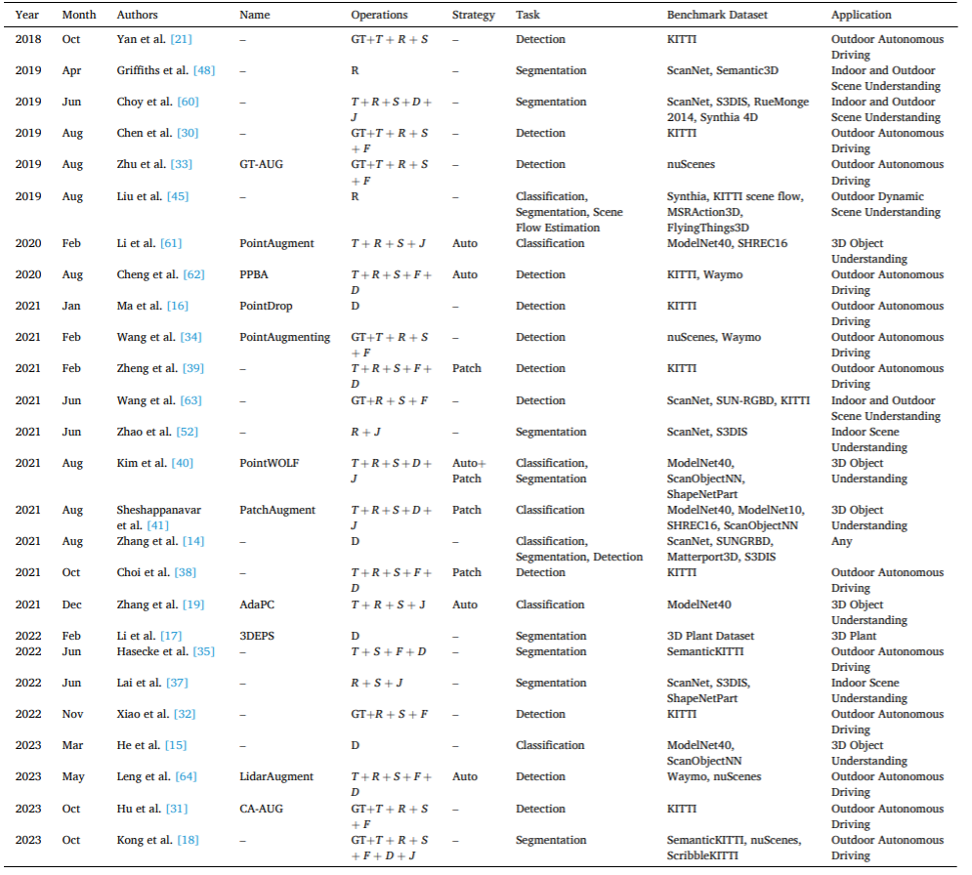
Die spezifischen Definitionen und Diskussionen dieser spezifischen Verbesserungsmethoden sind im Text ausführlich beschrieben. Tabelle 2 gibt einen Überblick über die Entwicklung repräsentativer spezifischer Verbesserungsmethoden und bietet verschiedene Informationen. Tabelle 2. Repräsentative spezifische Methoden zur Punktwolkenverbesserung. Es ist zu beachten, dass einige aktuelle kontradiktorische Deformations-, Upsampling-, Vervollständigungs- und Generierungstechnologien nicht direkt auf die Verbesserung von Punktwolkendaten angewendet werden, wie in Tabelle 3 gezeigt. Um eine umfassende Klassifizierung spezifischer Methoden zu ermöglichen, werden diese potenziellen Methoden auch in diesem Artikel berücksichtigt und diskutiert. Tabelle 3. Mögliche spezifische Methoden zur Punktwolkenverbesserung. Diskussion
Die anwendbaren Aufgaben und Szenarien der Punktwolkendatenverbesserungsmethode werden im Artikel ausführlich besprochen und die Rolle der Punktwolkendatenverbesserung beim Konsistenzlernen wird hervorgehoben. wie in Abbildung 7 gezeigt. 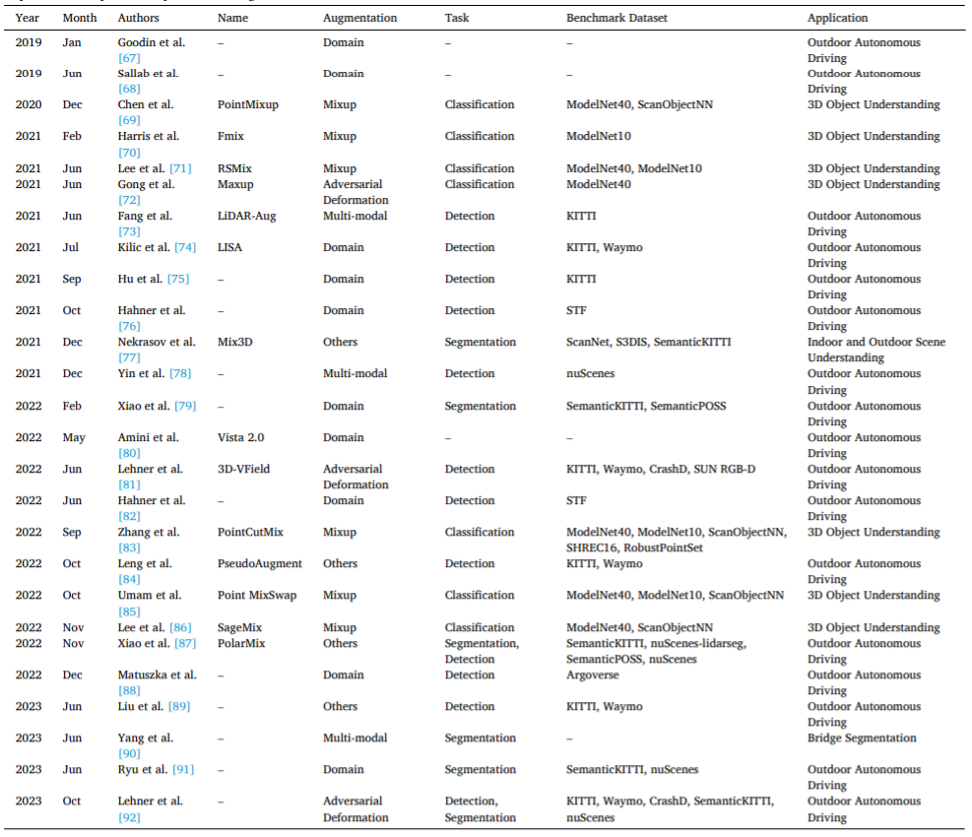
Abbildung 7. (a) Konventionelles Deep-Learning-Training, Senden der Originaldaten und erweiterter Daten an das Deep-Learning-Netzwerk zum Trainieren und Erhalten des trainierten Modells, (b) Konsistenzlernen unter Verwendung verschiedener Verbesserungsmethoden zum Ändern der Eingabepunkte; Die Cloud-Daten werden transformiert, um mehrere erweiterte Variablen zu generieren, die dann für konsistentes Lernen in mehrere Netzwerke eingespeist werden und so während des Trainings konsistente Vorhersagen treffen. Tabelle 4 organisiert die Literatur zur quantitativen Auswertung vor und nach der Datenanreicherung und zeigt die Wirkung der Datenanreicherung. Als weiteren Teil des Vergleichs verschiedener Augmentationsmethoden bietet der Anhang (Einzelheiten siehe Dokument) auch einen Überblick über die quantitative Leistung nachgelagerter Aufgaben unter Verwendung erweiterter Punktwolkendaten und die bei diesen Aufgaben eingesetzten Augmentationsmethoden.增 Tabelle 4. Berichtsergebnisse für verbesserte Modellleistung in Punktwolkendaten. ... Versarialverzerrung, Upsampling, Vervollständigung und Generierung zur Datenerweiterung. Angesichts der Fortschritte bei GANs und Diffusionsmodellen können diese Modelle verwendet werden, um realistische und vielfältige Punktwolkeninstanzen zu generieren. Zukünftige Forschungen sollten diese Methoden anhand von Benchmark-Datensätzen zu bestimmten Punktwolkenverarbeitungsaufgaben evaluieren, um ihre Wirksamkeit als Erweiterungstechniken zu bewerten. 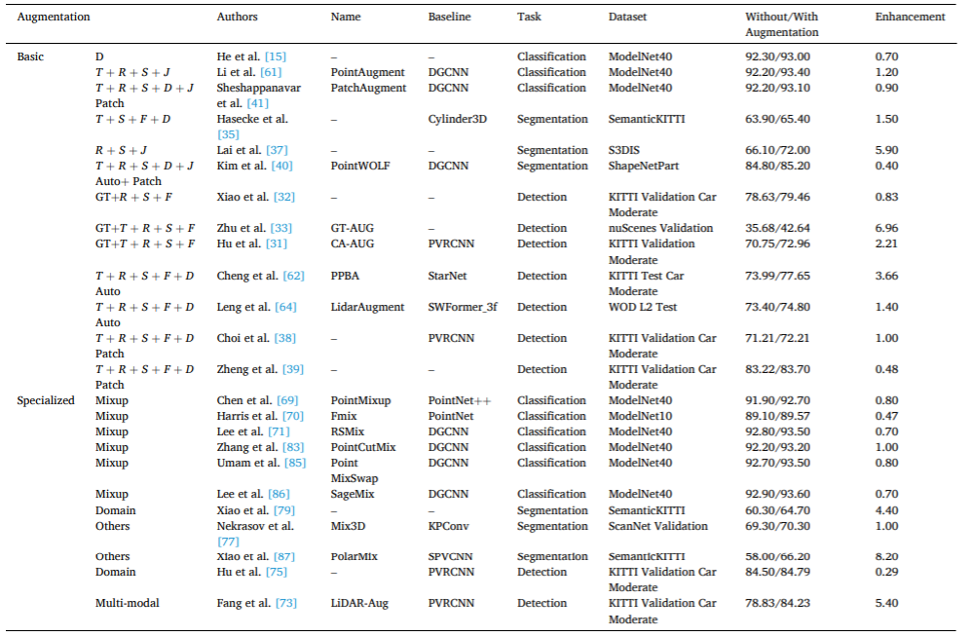
Derzeit gibt es nur wenige Studien, die konsistente Basisnetzwerke und Datensätze verwenden, um die Leistung von Methoden zur Punktwolkendatenerweiterung für verschiedene Punktwolkenverarbeitungsaufgaben zu bewerten. Eine solche Bewertung wird unser Verständnis der Leistung verschiedener Augmentationsmethoden verbessern. Daher könnten sich zukünftige Forschungsbemühungen auf die Etablierung neuer Methoden, Metriken und/oder Datensätze konzentrieren, um die Wirksamkeit von Methoden zur Punktwolkendatenerweiterung und deren Auswirkungen auf die Leistung von Deep-Learning-Modellen zu bewerten. Einige spezifische Erweiterungsmethoden können rechenintensiv sein, wenn sie auf große Punktwolkendatensätze angewendet werden. Zukünftige Arbeiten können sich auf die Entwicklung effizienter Algorithmen konzentrieren, die einen Kompromiss zwischen Rechenkosten und verbesserter Effizienz bieten. Darüber hinaus sind einige spezifische Methoden zur Punktwolkenverbesserung relativ komplex und schwer zu reproduzieren. Es wird empfohlen, einen Plug-and-Play-Ansatz zu entwickeln, um seine breite Akzeptanz zu fördern. Für die Verbesserung von Punktwolkendaten fehlt eine allgemein akzeptierte Kombination grundlegender Verbesserungsoperationen. Daher sind zukünftige Arbeiten erforderlich, um ein Standardprotokoll zur Auswahl von Erweiterungsvorgängen für verschiedene Anwendungsdomänen, Aufgaben und/oder Datensätze zu etablieren, ohne die Effizienz der Erweiterung zu beeinträchtigen.
-
Mehrere durch Augmentation generierte Punktwolkenvarianten wirken sich auf die Wirksamkeit des Konsistenzlernens aus. Derzeit werden nach unserem besten Wissen nur grundlegende Boosting-Methoden beim Konsistenzlernen verwendet. Die Erforschung spezifischer Methoden zur Punktwolkenverbesserung, wie z. B. kontradiktorische Verformung und generative Verbesserung, bietet eine interessante Möglichkeit, die Wirksamkeit des Konsistenzlernens zu verbessern, und wird als wertvolle zukünftige Forschungsrichtung angesehen.
-
Derzeit gibt es nur begrenzte Forschungsergebnisse zur Kombination grundlegender Methoden zur Punktwolkenverbesserung mit spezifischen Methoden zur Punktwolkenverbesserung. Eine solche Kombination hat das Potenzial, die Vielseitigkeit der Datenerweiterung weiter zu erhöhen und verdient künftige Forschung.
-
Augmentation muss Änderungen in Punktwolkendaten realistisch simulieren, wie z. B. Änderungen der Objektgröße, Position, Ausrichtung, Erscheinung und Umgebung, um sicherzustellen, dass die simulierten Daten mit realen Situationen übereinstimmen und semantisch bleiben richtig. Zukünftige Forschung könnte sich mit der Standardisierung der verschiedenen Verbesserungsbereiche befassen, um sie an bestimmte Anwendungsszenarien anzupassen.
-
Einige Anwendungen, wie z. B. die Objekterkennung, können dynamische Objekte in der Szene beinhalten. In dynamischen Umgebungen erfasste Punktwolken erfordern möglicherweise spezielle Erweiterungsstrategien, die zeitliche Änderungen in Objekten berücksichtigen. Beispielsweise kann eine bestimmte Flugbahn eines sich bewegenden Objekts entworfen werden, was durch eine Reihe kombinierter Verbesserungsoperationen wie Translation, Rotation und Verwerfen erreicht werden kann.
-
ViT erreicht auch eine starke Leistung bei Segmentierungs- und Klassifizierungsaufgaben durch die einfache Kombination grundlegender Operationen. Es wäre sinnvoll, die Leistung der verbesserten Methode zu untersuchen, wenn sie in das hochmoderne ViT als Backbone-Netzwerk integriert wird.
-
-
-
[1] Qinfeng Zhu, Lei Fan, Ningxin Weng, Advancements in Point
-
Cloud-Datenerweiterung für Deep Lernen: Eine Umfrage, Mustererkennung (2024), doi:
https://doi.org/10.1016/j.patcog.2024.110532Das obige ist der detaillierte Inhalt vonXJTLU und die University of Liverpool schlagen vor: die erste umfassende Überprüfung der Verbesserung von Punktwolkendaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!