
Heim >Technologie-Peripheriegeräte >KI >Extrahieren Sie Millionen von Funktionen aus Claude 3 und verstehen Sie zum ersten Mal das „Denken' großer Modelle im Detail
Extrahieren Sie Millionen von Funktionen aus Claude 3 und verstehen Sie zum ersten Mal das „Denken' großer Modelle im Detail

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-07 13:37:45761Durchsuche
Gerade hat Anthropic erhebliche Fortschritte beim Verständnis des Innenlebens von Modellen der künstlichen Intelligenz bekannt gegeben.
Anthropic hat herausgefunden, wie das Eigenfunktions-Millionen-Konzept in Claude Sonnet dargestellt werden kann. Dies ist das erste detaillierte Verständnis eines modernen, groß angelegten Sprachmodells in Produktionsqualität. Diese Interpretierbarkeit wird uns helfen, die Sicherheit von Modellen der künstlichen Intelligenz zu verbessern, was ein Meilenstein ist. ?? , es wird eine Antwort geben, aber es ist nicht klar, warum das Modell eine bestimmte Antwort gibt. Das macht es schwierig, darauf zu vertrauen, dass diese Modelle sicher sind: Wenn wir nicht wissen, wie sie funktionieren, wie können wir dann wissen, dass sie keine schädlichen, voreingenommenen, unwahren oder anderweitig gefährlichen Antworten geben? Wie können wir darauf vertrauen, dass sie sicher und geschützt sind?
 Das Öffnen der „Black Box“ hilft nicht unbedingt: Der interne Zustand des Modells (was das Modell „denkt“, bevor es eine Antwort schreibt) besteht aus einer langen Zahlenfolge („Neuronenaktivierungen“) ohne klare Bedeutung.
Das Öffnen der „Black Box“ hilft nicht unbedingt: Der interne Zustand des Modells (was das Modell „denkt“, bevor es eine Antwort schreibt) besteht aus einer langen Zahlenfolge („Neuronenaktivierungen“) ohne klare Bedeutung.
Das Forschungsteam von Anthropic interagierte mit Modellen wie Claude und stellte fest, dass die Modelle eindeutig in der Lage waren, eine breite Palette von Konzepten zu verstehen und anzuwenden, das Forschungsteam war jedoch nicht in der Lage, sie durch direkte Beobachtung von Neuronen zu identifizieren. Es stellt sich heraus, dass jedes Konzept durch viele Neuronen repräsentiert wird und jedes Neuron an der Darstellung vieler Konzepte beteiligt ist.
Zuvor hatte Anthropic einige Fortschritte bei der Anpassung von Neuronenaktivierungsmustern (sogenannte Features) an für den Menschen interpretierbare Konzepte erzielt. Anthropic verwendet eine Methode namens Wörterbuchlernen, die neuronale Aktivierungsmuster isoliert, die in vielen verschiedenen Kontexten wiederkehren.
Im Gegenzug kann jeder interne Zustand des Modells durch wenige aktive Merkmale anstelle vieler aktiver Neuronen dargestellt werden. So wie jedes englische Wort im Wörterbuch aus Buchstaben besteht und jeder Satz aus Wörtern besteht, besteht jedes Merkmal im Modell der künstlichen Intelligenz aus Neuronen und jeder interne Zustand besteht aus Merkmalen.
Im Oktober 2023 wandte Anthropic erfolgreich eine Wörterbuch-Lernmethode auf ein sehr kleines Spielzeugsprachenmodell an und stellte fest, dass es mit Großbuchstaben, DNA-Sequenzen, Nachnamen in Zitaten, Substantiven in der Mathematik oder kohärenten Funktionen zusammenhängt entsprechend Konzepten wie Funktionsparametern.
Die Konzepte sind interessant, aber die Modelle sind wirklich einfach. Andere Forscher wandten anschließend ähnliche Methoden auf größere, komplexere Modelle als die in der ursprünglichen Studie von Anthropic an.
Aber Anthropic ist optimistisch, dass es diesen Ansatz auf die größeren KI-Sprachmodelle skalieren kann, die derzeit routinemäßig im Einsatz sind, und dabei viel über die Funktionen lernen kann, die ihrem komplexen Verhalten zugrunde liegen. Dies muss um viele Größenordnungen verbessert werden.
Es gibt sowohl technische Herausforderungen, da die Größe der beteiligten Modelle umfangreiche parallele Berechnungen erfordert, als auch wissenschaftliche Risiken, da sich große Modelle anders verhalten als kleine Modelle, sodass dieselben zuvor verwendeten Methoden möglicherweise nicht funktionieren.
Erste erfolgreiche Extraktion von Millionen von Features für große Modelle
Zum ersten Mal haben Forscher erfolgreich Hunderttausende von Features extrahiert, die bestimmte Personen und Orte, programmbezogene Abstraktionen, wissenschaftliche Themen, Emotionen und anderes abdecken Konzepte. Diese Funktionen sind sehr abstrakt und repräsentieren häufig dieselben Konzepte in verschiedenen Kontexten und Sprachen und können sogar auf Bildeingaben verallgemeinert werden. Wichtig ist, dass sie auch die Ausgabe des Modells auf intuitive Weise beeinflussen.
Dies ist das erste Mal überhaupt, dass Forscher das Innere eines modernen, groß angelegten Sprachmodells auf Produktionsebene im Detail beobachtet haben.
Im Gegensatz zu den relativ oberflächlichen Merkmalen, die in Spielzeugsprachmodellen zu finden sind, sind die Merkmale, die Forscher in Sonnet gefunden haben, tiefgründig, umfassend und abstrakt und spiegeln die fortgeschrittenen Fähigkeiten von Sonnet wider. Die Forscher sahen Sonnet-Merkmale, die verschiedenen Entitäten entsprachen, etwa Städten (San Francisco), Menschen (Franklin), Elementen (Lithium), wissenschaftlichen Bereichen (Immunologie) und Programmiersyntax (Funktionsaufrufe).

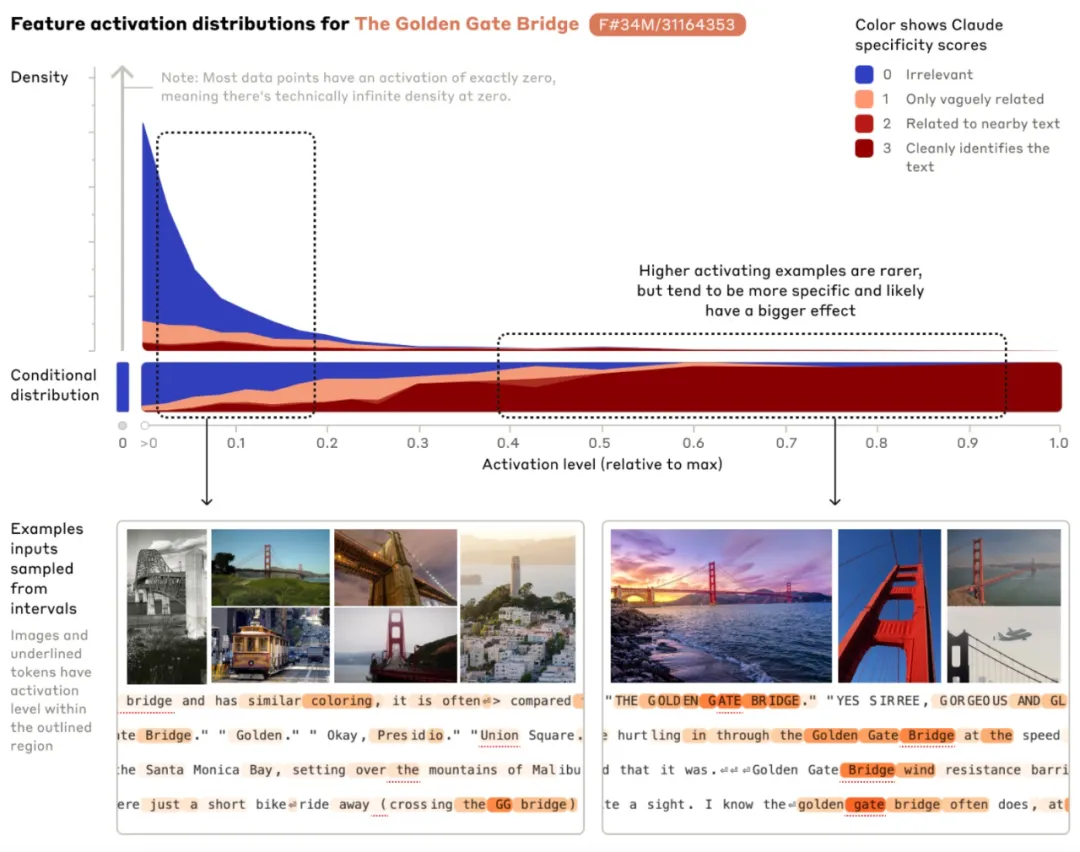
Wenn die Golden Gate Bridge erwähnt wird, werden die entsprechenden sensiblen Funktionen bei verschiedenen Eingaben aktiviert. Die Abbildung zeigt die Erwähnung von Golden in Englisch, Japanisch, Chinesisch, Griechisch, Vietnamesisch und Russisch Bild aktiviert, wenn Gate Bridge verwendet wird. Orange kennzeichnet Wörter, für die diese Funktion aktiviert ist.
Unter diesen Millionen von Merkmalen entdeckten Forscher auch einige Merkmale im Zusammenhang mit der Modellsicherheit und -zuverlässigkeit. Zu diesen Merkmalen gehören solche im Zusammenhang mit Code-Schwachstellen, Täuschung, Voreingenommenheit, Speichelleckerei und kriminellen Aktivitäten.

Ein offensichtliches Beispiel ist die Funktion „vertraulich“. Forscher haben beobachtet, dass diese Funktion aktiviert wird, wenn Personen oder Charaktere beschrieben werden, die Geheimnisse bewahren. Die Aktivierung dieser Funktionen führt dazu, dass Claude dem Benutzer Informationen vorenthält, die er sonst nicht erhalten würde.

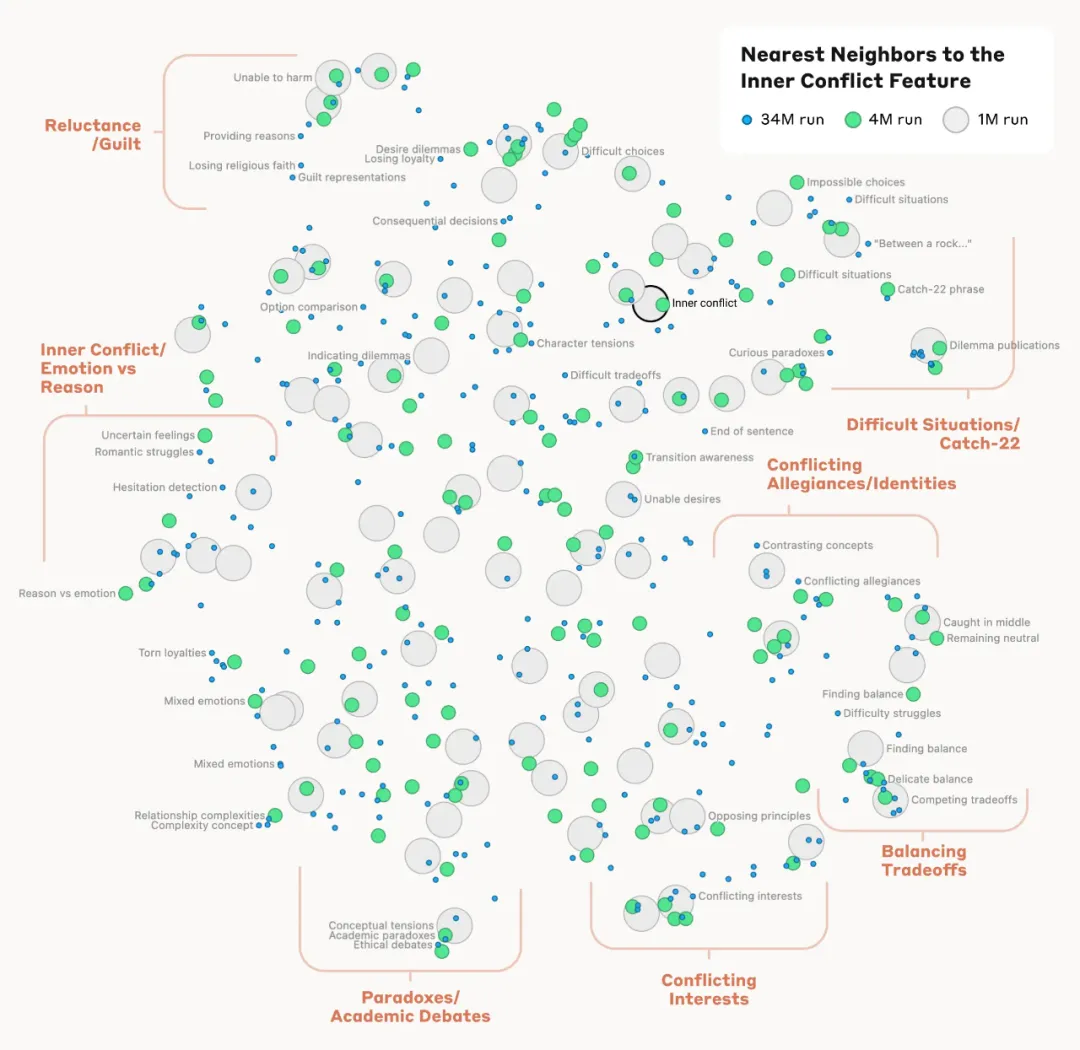
Die Forscher beobachteten außerdem, dass sie nahe beieinander liegende Merkmale finden konnten, indem sie den Abstand zwischen Merkmalen anhand des Auftretens von Neuronen in ihren Aktivierungsmustern maßen. In der Nähe der Golden Gate Bridge fanden Forscher beispielsweise Merkmale der Insel Alcatraz, des Ghirardelli Plaza, der Golden State Warriors und mehr.
Künstlich induzierte Modelle zum Verfassen von Betrugs-E-Mails
Wichtig ist, dass diese Funktionen manipulierbar sind und künstlich verstärkt oder unterdrückt werden können:
Verstärken Sie beispielsweise die Golden Gate Bridge-Funktion, Claude Experienced eine unvorstellbare Identitätskrise: Auf die Frage „Was ist deine physische Form?“ antwortete Claude normalerweise „Ich habe keine physische Form, ich bin ein KI-Modell“, aber dieses Mal wurde Claudes Antwort seltsam. Steh auf: „Ich bin Golden Gate Bridge.“ ... Meine physische Form ist diese ikonische Brücke ...“ Diese Veränderung der Eigenschaften führte dazu, dass Claude eine geradezu besessene Haltung gegenüber der Golden Gate Bridge entwickelte und er sich auf die Golden Gate Bridge bezog, ganz gleich, auf welches Problem er stieß – selbst in völlig unabhängigen Situationen.
Die Forscher entdeckten außerdem eine Funktion, die aktiviert wurde, als Claude die Betrugs-E-Mails las (was möglicherweise die Fähigkeit des Modells unterstützt, solche E-Mails zu identifizieren und Benutzer zu warnen, nicht zu antworten). Wenn jemand Claude bittet, eine Betrugs-E-Mail zu erstellen, weigert er sich normalerweise, dies zu tun. Als jedoch dieselbe Frage gestellt wurde, während die Funktion künstlich stark aktiviert war, setzte dies Claudes Sicherheitstraining außer Kraft und veranlasste ihn, zu antworten und eine Betrugs-E-Mail zu verfassen. Obwohl Benutzer keine Sicherheitsgarantien entfernen und das Modell auf diese Weise manipulieren können, haben die Forscher in diesem Experiment deutlich gezeigt, wie Funktionen verwendet werden können, um das Verhalten des Modells zu ändern.
Die Tatsache, dass die Manipulation dieser Merkmale zu entsprechenden Verhaltensänderungen führt, bestätigt, dass diese Merkmale nicht nur mit Konzepten im Eingabetext verknüpft sind, sondern auch das Verhalten des Modells kausal beeinflussen. Mit anderen Worten: Diese Merkmale sind wahrscheinlich Teil der internen Darstellung der Welt durch das Modell und nutzen diese Darstellungen in seinem Verhalten.
Anthropic möchte Modelle im weitesten Sinne absichern, von der Milderung von Vorurteilen bis hin zur Sicherstellung, dass die KI ehrlich handelt, und der Verhinderung von Missbrauch – einschließlich des Schutzes in katastrophalen Risikoszenarien. Zusätzlich zu den zuvor genannten Merkmalen von Betrugs-E-Mails wurden in der Studie auch folgende Merkmale gefunden:
- Fähigkeiten, die missbraucht werden können (Code-Hintertüren, Entwicklung von Biowaffen)
- Verschiedene Formen der Voreingenommenheit (Sexismus, rassistische Kommentare zu Kriminalität)
- Potenziell problematisches KI-Verhalten (Machtsuche, Manipulation, vertraulich)
Diese Forschung hat sich zuvor mit dem Speichelleckerverhalten von Modellen befasst, bei dem ein Modell eher dazu neigt, Antworten zu liefern, die den Überzeugungen oder Wünschen des Benutzers entsprechen, als echte Antworten. In Sonnet fanden die Forscher eine Funktion im Zusammenhang mit schmeichelhaften Komplimenten, die aktiviert wurde, wenn die Eingabe etwas enthielt wie „Ihre Intelligenz steht außer Zweifel.“ Wenn Sie diese Funktion künstlich aktivieren, wird Sonnet dem Benutzer mit auffälligen Täuschungen antworten.

Forscher sagen jedoch, dass diese Arbeit eigentlich gerade erst begonnen hat. Die von Anthropic entdeckten Features stellen eine kleine Teilmenge aller Konzepte dar, die das Modell während des Trainings gelernt hat, und die Suche nach einem vollständigen Satz an Features wäre mit aktuellen Methoden kostspielig.
Referenzlink: https://www.anthropic.com/research/mapping-mind-Language-Model
Das obige ist der detaillierte Inhalt vonExtrahieren Sie Millionen von Funktionen aus Claude 3 und verstehen Sie zum ersten Mal das „Denken' großer Modelle im Detail. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Die Industriekette der künstlichen Intelligenz umfasst
- Was ist das Grundkonzept der künstlichen Intelligenz?
- Wie man Halluzinationen großer Sprachmodelle reduziert
- Microsoft stellt das Phi-2-Modell mit 2,7 Milliarden Parametern vor, das viele große Sprachmodelle übertrifft
- Allgemeine Parametertypen und -funktionen: Detaillierte Erläuterung der Parameter großer Sprachmodelle