
Heim >Technologie-Peripheriegeräte >KI >Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern

- PHPzOriginal
- 2024-06-06 12:33:011216Durchsuche
01 Ausblick im Überblick
Derzeit ist es schwierig, das richtige Gleichgewicht zwischen Erkennungseffizienz und Erkennungsergebnissen zu finden. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird.
02 Hintergrund & Motivation
Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Die Objekterkennung spielt eine entscheidende Rolle bei der Interpretation von Fernerkundungsbildern und kann zur Segmentierung, Beschreibung und Zielverfolgung von Fernerkundungsbildern verwendet werden. Aufgrund ihres relativ großen Sichtfelds und der Notwendigkeit großer Höhen weisen optische Fernerkundungsbilder aus der Luft jedoch Unterschiede in Bezug auf Maßstab, Blickpunktspezifität, zufällige Ausrichtung und hohe Hintergrundkomplexität auf, während die meisten herkömmlichen Datensätze terrestrische Ansichten enthalten. Daher weisen die zur Konstruktion künstlicher Merkmalserkennung verwendeten Techniken traditionell große Unterschiede in Genauigkeit und Geschwindigkeit auf. Aufgrund der Bedürfnisse der Gesellschaft und der Unterstützung der Entwicklung von Deep Learning ist der Einsatz neuronaler Netze zur Zielerkennung in optischen Fernerkundungsbildern notwendig.
Derzeit können Zielerkennungsalgorithmen, die Deep Learning zur Analyse optischer Fernerkundungsfotos kombinieren, in drei Typen unterteilt werden: überwacht, unbeaufsichtigt und schwach überwacht. Aufgrund der Komplexität und Unsicherheit unbeaufsichtigter und schwach überwachter Algorithmen sind überwachte Algorithmen jedoch die am häufigsten verwendeten Algorithmen. Darüber hinaus können überwachte Objekterkennungsalgorithmen in einstufige oder zweistufige Algorithmen unterteilt werden. Basierend auf der Annahme, dass sich Flugzeuge normalerweise an Flughäfen und Schiffe normalerweise an Häfen und Ozeanen befinden, können durch die Erkennung von Flughäfen und Häfen in heruntergesampelten Sternbildern und die anschließende Zuordnung der entdeckten Objekte auf die ursprünglichen ultrahochaufgelösten Satellitenbilder Objekte von erkannt werden verschiedene Größen gleichzeitig. Einige Forscher haben eine auf RCNN basierende rotierende Zielerkennungsmethode vorgeschlagen, die die Genauigkeit der Zielerkennung in Fernerkundungsbildern verbessert, indem das Randomisierungsproblem der Zielrichtungen gelöst wird.
03 Neue Algorithmusforschung
Die meisten Erkennungsköpfe der aktuellen YOLO-Serie basieren auf den Ausgabeeigenschaften von FPN und PAFPN. Darunter sind FPN-basierte Netzwerke wie YOLOv3 und ihre Varianten in Abbildung dargestellt a unten Sie nutzen direkt die Einweg-Fusionsfunktion für die Ausgabe. YOLOv4 und YOLOv5 basieren auf dem PAFPN-Algorithmus und fügen auf dieser Basis einen Low-Level-zu-High-Level-Kanal hinzu, der Low-Level-Signale direkt nach oben überträgt (b unten).
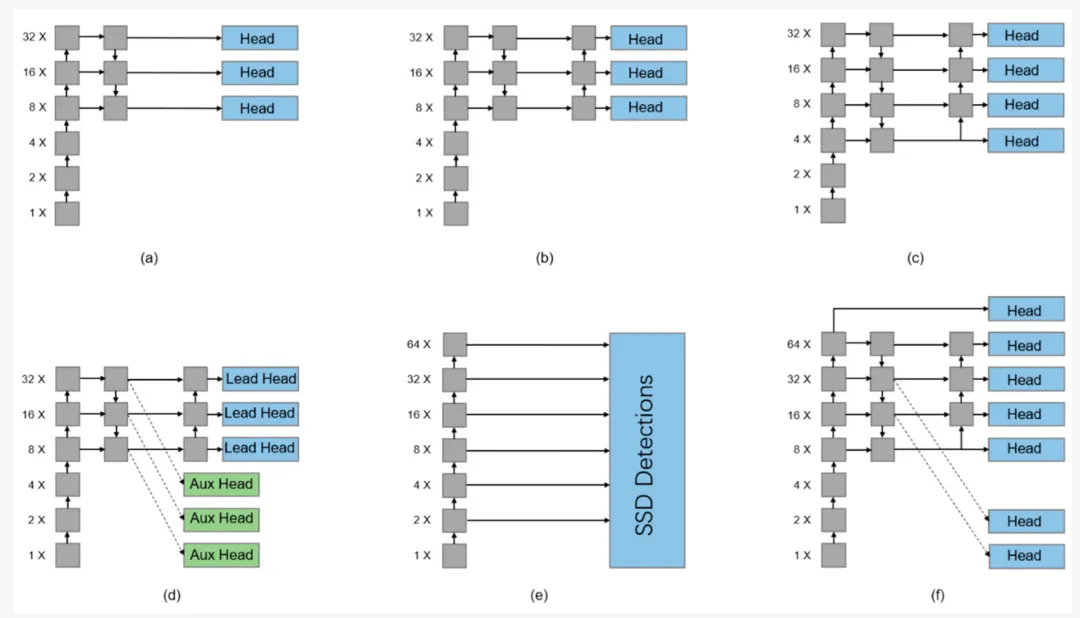
Wie in der Abbildung oben gezeigt, wurde in einigen Studien ein Erkennungskopf für bestimmte Erkennungsaufgaben im TPH-YOLOv5-Modell hinzugefügt. In den Abbildungen b und c oben kann nur die PAFPN-Funktion für die Ausgabe verwendet werden, während die FPN-Funktion nicht vollständig genutzt wird. Daher verbindet YOLOv7 drei Hilfsköpfe mit dem FPN-Ausgang, wie in Abbildung d oben gezeigt, obwohl die Hilfsköpfe nur für die „Grobauswahl“ verwendet werden und eine geringere Gewichtsbewertung haben. Der SSD-Erkennungskopf soll das zu grobe Ankersatzdesign des YOLO-Netzwerks verbessern und ein dichtes Ankerdesign basierend auf mehreren Maßstäben vorschlagen. Wie in Abbildung f gezeigt, kann diese Strategie gleichzeitig die Funktionsinformationen von PANet und FPN nutzen. Darüber hinaus gibt es einen 64-fachen Downsampling-Prozess, der die Ausgabe direkt hinzufügt, wodurch das Netzwerk frühere globale Informationen enthält.
Die Mehrfacherkennungskopfmethode kann die Ausgabefunktionen des Netzwerks effektiv nutzen. Verbessertes YOLO ist ein Objekterkennungsnetzwerk für hochauflösende Fernerkundungsfotos. Wie in der folgenden Abbildung dargestellt:

Die Grundstruktur des Backbone-Netzwerks ist ein CSP-dichtes Netzwerk mit C3- und Faltungsmodulen als Kern. Nach der Datenerweiterung werden Bilder in das Netzwerk eingespeist und nach der Kanalmischung durch das Conv-Modul mit Kernelgröße 6 führen viele Faltungsmodule den Feature-Abruf durch. Nach einem Funktionserweiterungsmodul namens SPPF werden sie mit dem PANet von Neck verbunden. Um die Erkennungsfähigkeit des Netzwerks zu verbessern, wird eine bidirektionale Merkmalsfusion durchgeführt. Conv2d wird verwendet, um die fusionierten Feature-Layer unabhängig zu erweitern, um mehrschichtige Ausgaben zu generieren. Wie in der folgenden Abbildung dargestellt, kombiniert der NMS-Algorithmus die Ausgaben aller Einzelschichtdetektoren, um den endgültigen Erkennungsrahmen zu generieren.

Abbildung b unten beschreibt die strukturelle Zusammensetzung jedes Moduls des verbesserten YOLO-Netzwerks.

Conv umfasst eine 2D-Faltungsschicht, eine BN-Schicht-Batch-Normalisierung und eine Silu-Aktivierungsfunktion, C3 enthält zwei 2D-Faltungsschichten und eine Engpassschicht und Upsample ist eine Upsampling-Schicht. Das SPPF-Modul ist eine beschleunigte Version des SPP-Moduls, das MAB-Modul ist wie oben erwähnt und das ECA ist wie in der unteren linken Ecke dargestellt. Nach dem globalen Durchschnittspooling auf Kanalebene ohne Dimensionsreduzierung werden schnelle 1D-Faltungen der Größe k verwendet, um lokale kanalübergreifende Interaktionsinformationen zu erfassen, wobei die Beziehung jedes Kanals zu seinen k Nachbarn berücksichtigt wird, wodurch ECA effizient durchgeführt wird. Die beiden oben genannten Transformationen sammeln Merkmale entlang zweier Raumrichtungen, um ein Paar richtungsbezogener Merkmalskarten zu erzeugen, die dann mithilfe von Faltungs- und Sigmoidfunktionen verkettet und modifiziert werden, um eine Aufmerksamkeitsausgabe bereitzustellen.
04 Experiment und Visualisierung
Der SIMD-Datensatz ist ein Open-Source-Datensatz zur Erkennung hochauflösender Fernerkundungsobjekte mit mehreren Kategorien, der insgesamt 15 Kategorien enthält, wie in Abbildung 4 dargestellt. Darüber hinaus ist der SIMD-Datensatz stärker auf kleine und mittelgroße Ziele verteilt (w


Sie können den Ausgang des SPPF-Moduls mit dem Ausgangsheader verbinden, um große Ziele im Bild zu identifizieren. Die Ausgabe des SPPF-Moduls verfügt jedoch über mehrere Verbindungen und umfasst Ziele in mehreren Maßstäben. Daher führt die direkte Verwendung für den Erkennungskopf zur Identifizierung großer Objekte zu einer schlechten Modelldarstellung, wie in der Abbildung oben vor und nach dem Hinzufügen dargestellt MAB-Modul Visueller Vergleich von Heatmaps einiger Erkennungsergebnisse. Nach dem Hinzufügen des MAB-Moduls konzentriert sich der Erkennungskopf auf die Erkennung großer Ziele und weist die Vorhersage kleiner Ziele anderen Vorhersageköpfen zu, was den Ausdruckseffekt des Modells verbessert und besser den Anforderungen der Aufteilung des Erkennungskopfs nach Ziel entspricht Größe im YOLO-Algorithmus.

Einige Testergebnisse sind im Bild oben dargestellt. Den einzelnen Erkennungsergebnissen nach zu urteilen, gibt es keinen großen Unterschied zu anderen Algorithmen. Im Vergleich zu anderen Algorithmen verbessert der von uns untersuchte Algorithmus jedoch den Erkennungseffekt des Modells und stellt gleichzeitig sicher, dass der Zeitverbrauch nicht wesentlich ansteigt, und nutzt den Aufmerksamkeitsmechanismus Verbessern Sie den Ausdruckseffekt des Modells.

Das obige ist der detaillierte Inhalt vonVerbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Unsicherer Verschlüsselungsalgorithmus
- Aus welchen zwei Teilen muss ein rekursiver Algorithmus bestehen?
- So erkennen Sie Duplikate zwischen zwei Word-Dokumenten
- Wie hoch ist die zeitliche Komplexität eines Programms, das den binären Suchalgorithmus verwendet?
- So implementieren Sie den Blasensortierungsalgorithmus in PHP