
Heim >Technologie-Peripheriegeräte >KI >NVIDIAs neue Forschung: Die Kontextlänge ist ernsthaft falsch und nicht viele 32K-Leistungen sind qualifiziert
NVIDIAs neue Forschung: Die Kontextlänge ist ernsthaft falsch und nicht viele 32K-Leistungen sind qualifiziert

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-05 16:22:471209Durchsuche
Das falsche Standardphänomen großer Modelle mit „langem Kontext“ wird schonungslos aufgedeckt –
NVIDIAs neue Untersuchung ergab, dass 10 große Modelle, darunter GPT-4, Kontextlängen von 128.000 oder sogar 1 Mio. erzeugen.
Aber nach einigen Tests ist der neue Indikator „effektiver Kontext“ stark geschrumpft, und nicht viele können 32K erreichen.
Der neue Benchmark heißt RULER und umfasst Abruf, Multi-Hop-Tracking, Aggregation sowie Frage und Antwort 4 Kategorien mit insgesamt 13 Aufgaben. RULER definiert die „effektive Kontextlänge“, also die maximale Länge, bei der das Modell die gleiche Leistung wie die Llama-7B-Basislinie bei 4K-Länge aufrechterhalten kann.

Diese Studie wurde von Wissenschaftlern als „sehr aufschlussreich“ bewertet.

Nachdem viele Internetnutzer diese neue Studie gesehen hatten, wollten sie auch die Ergebnisse der Herausforderung der Kontextlängenkönig-Spieler Claude und Gemini sehen. (Wird im Artikel nicht behandelt)


Werfen wir einen Blick darauf, wie NVIDIA den Indikator „effektiver Kontext“ definiert.

Es gibt immer schwierigere Testaufgaben
Um die Langtextverständnisfähigkeit großer Modelle zu bewerten, müssen Sie zunächst einen guten Standard auswählen, z. B. ZeroSCROLLS, L-Eval, LongBench, InfiniteBench usw Beliebt im Kreis, oder nur bewerten Die Fähigkeit zum Abrufen von Modellen ist entweder durch die Einmischung von Vorwissen eingeschränkt.
Die von NVIDIA eliminierte RULER-Methode lässt sich also in einem Satz zusammenfassen: „Stellen Sie sicher, dass sich die Bewertung auf die Fähigkeit des Modells konzentriert, lange Kontexte zu verarbeiten und zu verstehen, und nicht auf die Fähigkeit, Informationen aus den Trainingsdaten abzurufen“ . Die Bewertungsdaten von
RULER reduzieren die Abhängigkeit von „parametrisiertem Wissen“, also dem Wissen, das das große Modell während des Trainingsprozesses in seine eigenen Parameter kodiert hat.
Konkret erweitert der RULER-Benchmark den beliebten „Nadel im Heuhaufen“-Test um vier neue Aufgabenkategorien.
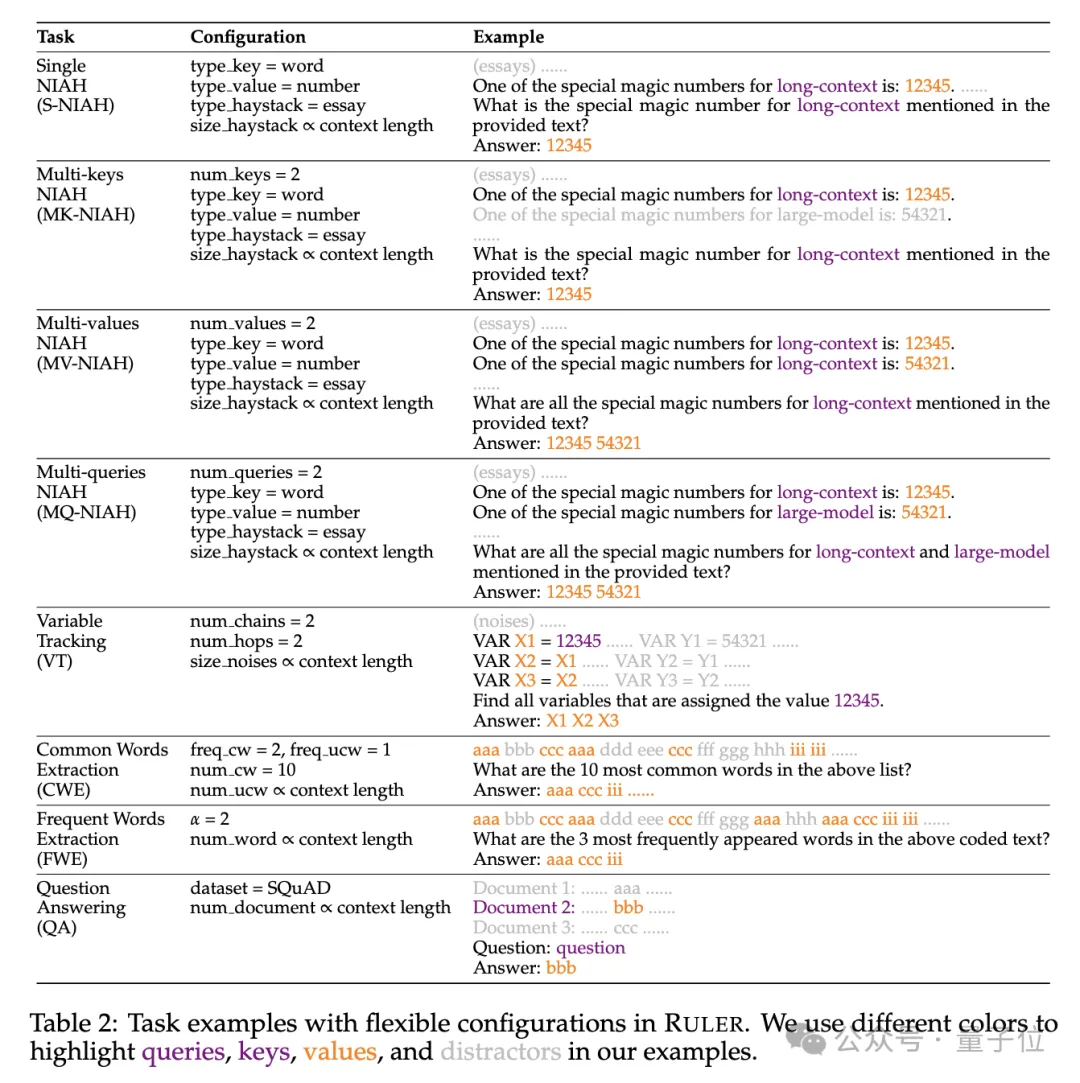
In Bezug auf das Suchen wurden ausgehend von der standardmäßigen Einzelnadel-Suchaufgabe, eine Nadel im Heuhaufen zu finden, die folgenden neuen Typen hinzugefügt:
- Suchen mit mehreren Tasten (Multi -Schlüssel NIAH, MK-NIAH): Fügen Sie mehrere Interferenzstifte in den Kontext ein, und das Modell muss den angegebenen abrufen
- Mehrwertabruf (Mehrwertwerte NIAH, MV-NIAH) : Ein Schlüssel(Schlüssel) entspricht mehreren Werten (Werte), das Modell muss alle Werte abrufen, die einem bestimmten Schlüssel zugeordnet sind.
- Abruf mehrerer Abfragen (Mehrfachabfragen NIAH, MQ-NIAH): Das Modell muss mehrere entsprechende Nadeln im Text basierend auf mehreren Abfragen abrufen.
Zusätzlich zur aktualisierten Version des Abrufs fügt RULER auch die Herausforderung „Multi-Hop-Tracing“ (Multi-Hop-Tracing) hinzu. Konkret schlugen die Forscher Variable Tracking
(VT)vor, das die minimale Aufgabe der Koreferenzauflösung simuliert und erfordert, dass das Modell die Zuweisungskette von Variablen im Text verfolgt, selbst wenn diese Zuweisungen im Text vorhanden sind nicht kontinuierlich. Die dritte Ebene der Herausforderung ist Aggregation(Aggregation)
, einschließlich:Common Words Extraction
- (CWE)
- : Das Modell muss die häufigsten Wörter aus dem Text extrahieren. Frequent Words Extraction (Frequent Words Extraction, FWE)
-
: Ähnlich wie CWE, aber die Häufigkeit eines Wortes wird anhand seiner Rangfolge im Vokabular und des Zeta-Verteilungsparameters α bestimmt.
Die vierte Ebene der Herausforderung ist die Frage- und Antwortaufgabe (QA) Basierend auf dem vorhandenen Leseverständnisdatensatz (z. B. SQuAD) wird eine große Anzahl von Interferenzabsätzen eingefügt, um die lange Sequenz zu testen Qualitätssicherungsfähigkeit.
Wie lang ist eigentlich jeder Modellkontext?
In der experimentellen Phase haben die Forscher, wie eingangs erwähnt, 10 Sprachmodelle ausgewertet, die angeblich den langen Kontext unterstützen, darunter GPT-4, und 9 Open-Source-Modelle Command-R, Yi-34B, Mixtral (8x7B), Mixtral ( 7B), ChatGLM, LWM, Together, LongChat, LongAlpaca.
Diese Modellparametergrößen reichen von 6B bis 8x7B mit MoE-Architektur, und die maximale Kontextlänge reicht von 32K bis 1M.
Im RULER-Benchmark-Test wurde jedes Modell anhand von 13 verschiedenen Aufgaben bewertet, die 4 Aufgabenkategorien abdecken, die von einfach bis komplex reichen. Für jede Aufgabe werden 500 Testbeispiele mit Eingabelängen von 4K bis 128K in 6 Stufen (4K, 8K, 16K, 32K, 64K, 128K) generiert.
 Um zu verhindern, dass das Modell die Beantwortung der Frage verweigert, wird der Eingabe ein Antwortpräfix angehängt und das Vorhandensein der Zielausgabe anhand der abrufbasierten Genauigkeit überprüft. Die Forscher haben auch die Metrik „effektive Kontextlänge“ definiert, das heißt, das Modell kann bei dieser Länge das gleiche Leistungsniveau wie das Basismodell Llama-7B bei 4K-Länge beibehalten.
Um zu verhindern, dass das Modell die Beantwortung der Frage verweigert, wird der Eingabe ein Antwortpräfix angehängt und das Vorhandensein der Zielausgabe anhand der abrufbasierten Genauigkeit überprüft. Die Forscher haben auch die Metrik „effektive Kontextlänge“ definiert, das heißt, das Modell kann bei dieser Länge das gleiche Leistungsniveau wie das Basismodell Llama-7B bei 4K-Länge beibehalten. Für einen detaillierteren Modellvergleich wird der gewichtete Durchschnittswert
(Weighted Average, wAvg)als umfassender Indikator verwendet, um einen gewichteten Durchschnitt der Leistung bei verschiedenen Längen zu ermitteln. Es werden zwei Gewichtungsschemata verwendet:
wAvg(inc): Das Gewicht nimmt linear mit der Länge zu und simuliert Anwendungsszenarien, die von langen Sequenzen dominiert werden.- wAvg(dec): Das Gewicht nimmt linear mit der Länge ab, wodurch hauptsächlich Szenen mit kurzen Sequenzen simuliert werden
- um das Ergebnis zu sehen.
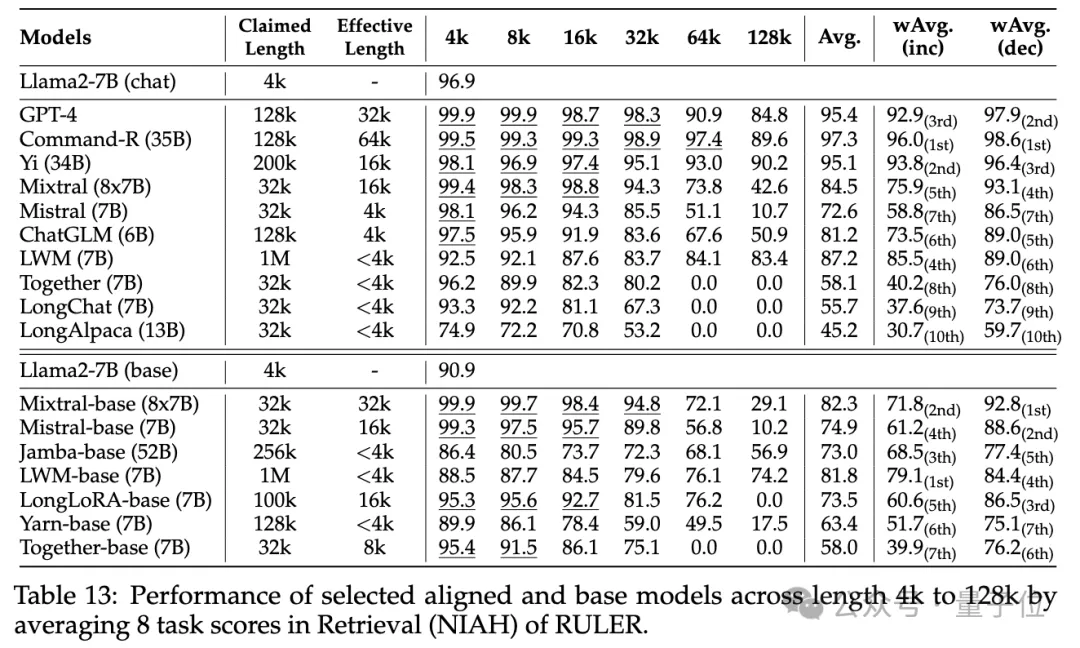
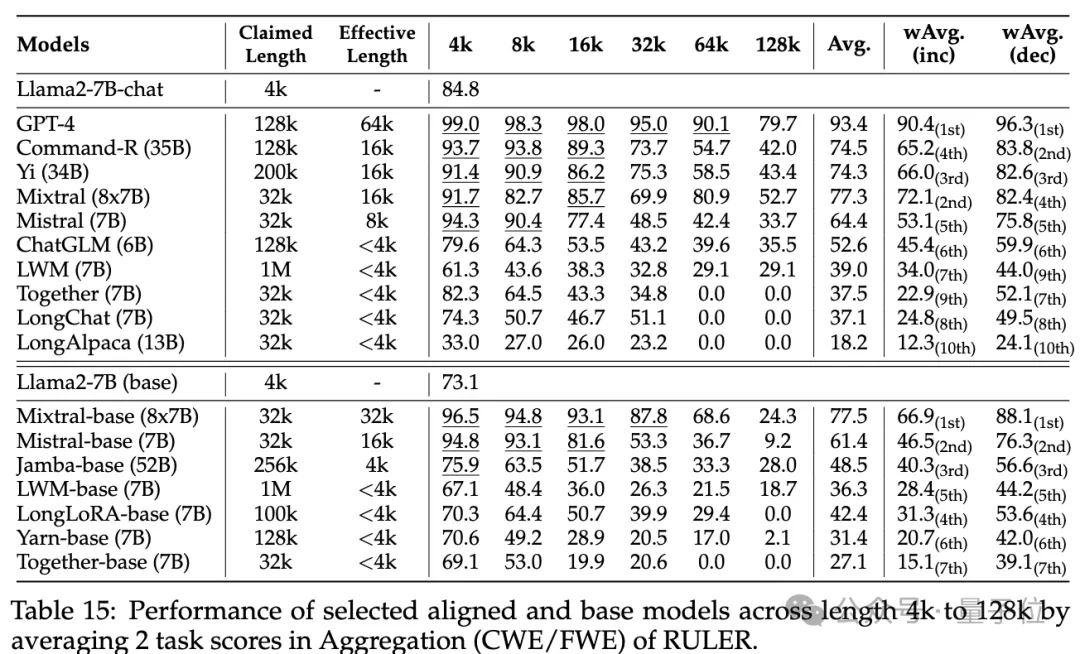
Bei den gewöhnlichen Nadel-im-Heuhaufen- und Passwort-Retrieval-Tests ist kein Unterschied erkennbar, da fast alle Modelle innerhalb ihres beanspruchten Kontextlängenbereichs perfekte Ergebnisse erzielen.
Obwohl viele Modelle behaupten, mit RULER Kontexte von 32K-Tokens oder mehr verarbeiten zu können, behält kein Modell außer Mixtral eine Leistung bei, die über der Llama2-7B-Basislinie bei der beanspruchten Länge liegt.
(15,4 %)Weitere Ergebnisse sind wie folgt: Insgesamt schneidet GPT-4 bei einer Länge von 4 KB am besten ab und zeigt minimale Leistungseinbußen , wenn der Kontext auf 128 KB erweitert wird. Die drei besten Open-Source-Modelle sind Command-R, Yi-34B und Mixtral, die alle RoPE mit einer größeren Basisfrequenz verwenden und mehr Parameter als andere Modelle haben.
(bis zu 256K) Darüber hinaus führten die Forscher eine eingehende Analyse der Leistung des Yi-34B-200K-Modells bei zunehmenden Eingabelängen und komplexeren Aufgaben durch, um das Verständnis zu verbessern die Aufgaben Auswirkungen von Konfiguration und Fehlermodi auf RULER. Sie analysierten auch die Auswirkungen der Trainingskontextlänge, der Modellgröße und der Architektur auf die Modellleistung und stellten fest, dass das Training mit größeren
-Kontexten im Allgemeinen zu einer besseren Leistung führt, die Rangfolge langer Sequenzen jedoch möglicherweise inkonsistent ist. Mit zunehmender Modellgröße gibt es erhebliche Vorteile für die Modellierung langer Kontexte; Nicht-Transformer-Architekturen (wie RWKV und Mamba) liegen deutlich hinter dem Transformer-basierten Llama2-7B auf RULER zurück. Für weitere Details können interessierte Leser das Originalpapier einsehen.
Papierlink: https://arxiv.org/abs/2404.06654
 Um zu verhindern, dass das Modell die Beantwortung der Frage verweigert, wird der Eingabe ein Antwortpräfix angehängt und das Vorhandensein der Zielausgabe anhand der abrufbasierten Genauigkeit überprüft.
Um zu verhindern, dass das Modell die Beantwortung der Frage verweigert, wird der Eingabe ein Antwortpräfix angehängt und das Vorhandensein der Zielausgabe anhand der abrufbasierten Genauigkeit überprüft.  Die Forscher haben auch die Metrik „effektive Kontextlänge“ definiert, das heißt, das Modell kann bei dieser Länge das gleiche Leistungsniveau wie das Basismodell Llama-7B bei 4K-Länge beibehalten.
Die Forscher haben auch die Metrik „effektive Kontextlänge“ definiert, das heißt, das Modell kann bei dieser Länge das gleiche Leistungsniveau wie das Basismodell Llama-7B bei 4K-Länge beibehalten.  Weitere Ergebnisse sind wie folgt: Insgesamt schneidet GPT-4 bei einer Länge von 4 KB am besten ab und zeigt minimale Leistungseinbußen
Weitere Ergebnisse sind wie folgt: Insgesamt schneidet GPT-4 bei einer Länge von 4 KB am besten ab und zeigt minimale Leistungseinbußen 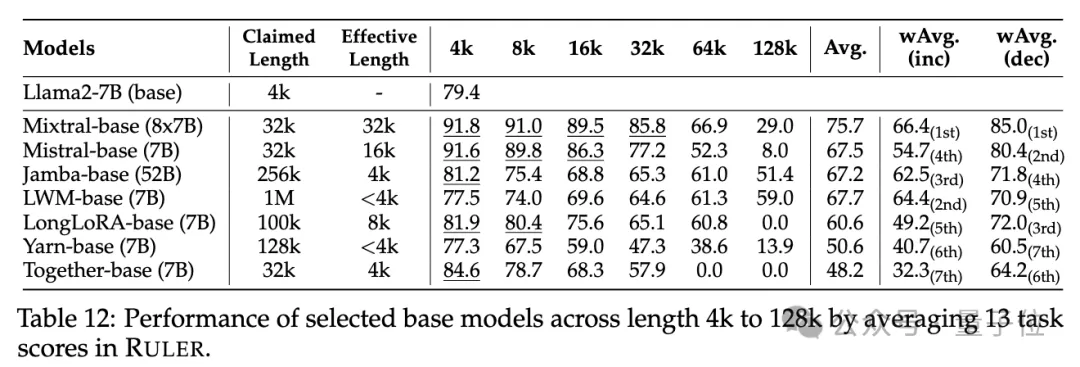

 Darüber hinaus führten die Forscher eine eingehende Analyse der Leistung des Yi-34B-200K-Modells bei zunehmenden Eingabelängen
Darüber hinaus führten die Forscher eine eingehende Analyse der Leistung des Yi-34B-200K-Modells bei zunehmenden Eingabelängen Das obige ist der detaillierte Inhalt vonNVIDIAs neue Forschung: Die Kontextlänge ist ernsthaft falsch und nicht viele 32K-Leistungen sind qualifiziert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Der Unterschied zwischen has und with im Laravel-Assoziationsmodell (ausführliche Einführung)
- Was bedeutet das Python-IPO-Modell?
- Welches Datenmodell verwenden derzeit die meisten Datenbankverwaltungssysteme?
- Nvidia plant, im zweiten Quartal nächsten Jahres die Blackwell B100-GPU der nächsten Generation mit HBM3E-Speicher auf den Markt zu bringen
- Neue US-Exportbestimmungen trafen NVIDIA und führten zu einem sofortigen Rückgang des Aktienkurses um 8 %