
Heim >Technologie-Peripheriegeräte >KI >Hype und Realität von KI-Agenten: GPT-4 kann dies nicht einmal unterstützen und die Erfolgsquote realer Aufgaben beträgt weniger als 15 %
Hype und Realität von KI-Agenten: GPT-4 kann dies nicht einmal unterstützen und die Erfolgsquote realer Aufgaben beträgt weniger als 15 %

- PHPzOriginal
- 2024-06-03 18:38:421105Durchsuche
Im Einklang mit der kontinuierlichen Weiterentwicklung und Selbstinnovation großer Sprachmodelle wurden Leistung, Genauigkeit und Stabilität erheblich verbessert, was durch verschiedene Benchmark-Problemsätze bestätigt wurde.
Allerdings scheinen die umfassenden Funktionen bestehender Versionen von LLM nicht in der Lage zu sein, KI-Agenten vollständig zu unterstützen.

Multimodale, Multi-Task- und Multi-Domain-Inferenz sind zu notwendigen Anforderungen für KI-Agenten im öffentlichen Medienraum geworden, aber die tatsächlichen Auswirkungen, die sich in bestimmten funktionalen Praktiken zeigen, variieren stark. Dies scheint alle KI-Roboter-Startups und großen Technologieriesen noch einmal daran zu erinnern, die Realität zu erkennen: Seien Sie bodenständiger, verbreiten Sie den Stall nicht zu weit und beginnen Sie mit KI-Verbesserungsfunktionen.
Kürzlich wurde in einem Blog über die Kluft zwischen der Bekanntheit und der tatsächlichen Leistung von KI-Agenten ein Punkt hervorgehoben: „KI-Agenten sind ein Riese in der Werbung, aber die Realität ist sehr schlecht. Dieser Satz drückt genau die Ansichten vieler Menschen aus.“ KI-Technologie. Mit der kontinuierlichen Weiterentwicklung von Wissenschaft und Technologie wurde die KI mit vielen auffälligen Funktionen und Fähigkeiten ausgestattet. In praktischen Anwendungen treten jedoch häufig einige Probleme auf und
Der Hintergrund, dass autonome KI-Agenten komplexe Aufgaben ausführen können große Sorge aufgeregt. Durch die Interaktion mit externen Tools und Funktionen können LLMs mehrstufige Arbeitsabläufe ohne menschliches Eingreifen abschließen.
Aber es stellte sich heraus, dass es anspruchsvoller war als erwartet.
WebArena Leaderboard ist eine reale und reproduzierbare Netzwerkumgebung zur Bewertung der Leistung praktischer Agenten. Ein Benchmarking der Leistung von LLM-Agenten bei realen Aufgaben zeigte, dass selbst das leistungsstärkste Modell eine Erfolgsquote von nur 35,8 % aufwies.
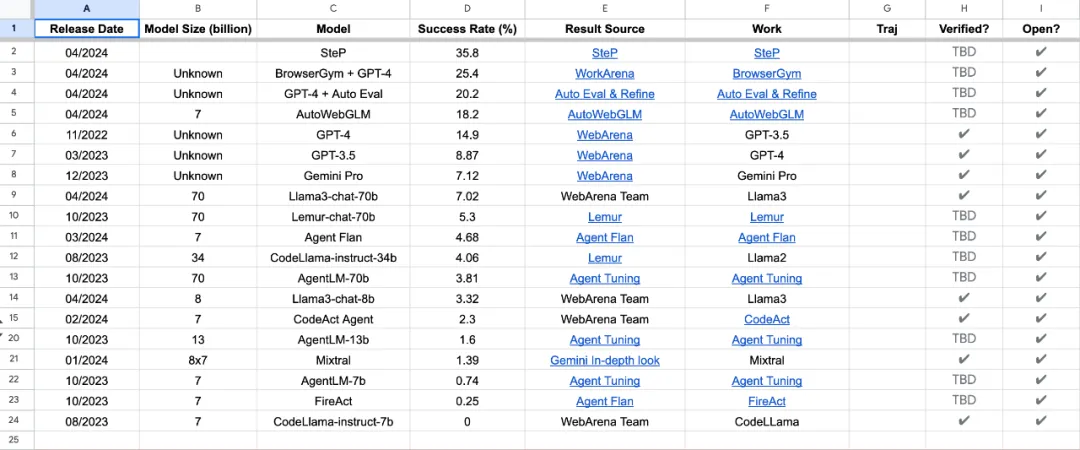
WebArena-Rangliste Benchmark-Ergebnisse der LLM-Agentenleistung bei realen Aufgaben: Das SteP-Modell schnitt beim Erfolgsratenindikator am besten ab und erreichte 35,8 %, während das bekannte GPT-4 die Erfolgsquote erreichte nur 14,9 %.
Was ist ein KI-Agent?
Der Begriff „KI-Agent“ ist nicht wirklich definiert und es gibt viele Kontroversen darüber, was genau ein Agent ist.
KI-Agent kann definiert werden als „ein LLM, dem die Fähigkeit gegeben wird, zu handeln (in der Regel Funktionsaufrufe in einer RAG-Umgebung durchzuführen), um Entscheidungen auf hoher Ebene darüber zu treffen, wie Aufgaben in der Umgebung ausgeführt werden.“ Derzeit gibt es zwei Hauptarchitekturmethoden zum Erstellen von KI-Agenten:
Einzelner Agent: Ein großes Modell übernimmt die gesamte Aufgabe und trifft alle Entscheidungen und Aktionen auf der Grundlage seines umfassenden Kontextverständnisses. Diese Methode nutzt die Emergenzleistung großer Modelle und vermeidet den durch Zerlegungsaufgaben verursachten Informationsverlust.
- Multi-Agenten-System: Unterteilen Sie die Aufgabe in Unteraufgaben. Jede Unteraufgabe wird von einem kleineren, spezialisierteren Agenten bearbeitet. Anstatt zu versuchen, einen großen Generalagenten einzusetzen, der schwer zu kontrollieren und zu testen ist, kann man viele kleinere Agenten einsetzen, um die richtige Strategie für eine bestimmte Teilaufgabe auszuwählen. Dieser Ansatz ist manchmal aufgrund praktischer Einschränkungen erforderlich, beispielsweise aufgrund von Einschränkungen bei der Länge des Kontextfensters oder der Notwendigkeit unterschiedlicher Fähigkeiten.
- Theoretisch ist ein einzelner Agent mit unendlicher Kontextlänge und perfekter Aufmerksamkeit ideal. Aufgrund des kürzeren Kontexts werden Multi-Agenten-Systeme bei einem bestimmten Problem immer schlechter abschneiden als ein einzelnes System.
Herausforderungen in der Praxis
Nachdem der Autor viele Versuche mit KI-Agenten miterlebt hat, glaubt er, dass diese noch zu früh, zu kostspielig, zu langsam und nicht zuverlässig genug sind. Viele KI-Agenten-Startups scheinen auf einen Modelldurchbruch zu warten, um den Wettlauf um die Produktion ihrer Agenten zu starten.
Die Leistung von KI-Agenten in tatsächlichen Anwendungen ist nicht ausgereift genug, was sich in Problemen wie ungenauer Ausgabe, unbefriedigender Leistung, höheren Kosten, Vergütungsrisiken und der Unfähigkeit, Benutzervertrauen zu gewinnen, widerspiegelt:
- Zuverlässigkeit: Es ist bekannt, dass LLMs anfällig für Halluzinationen und Inkonsistenzen sind. Die Verbindung mehrerer KI-Schritte kann diese Probleme verschärfen, insbesondere bei Aufgaben, die eine präzise Ausgabe erfordern.
- Leistung und Kosten: GPT-4, Gemini-1.5 und Claude Opus funktionieren gut mit Tools/Funktionsaufrufen, sind aber immer noch langsam und teuer, insbesondere wenn Schleifen und automatische Wiederholungsversuche erforderlich sind.
- Rechtliche Fragen: Unternehmen können für die Fehler ihrer Vertreter haftbar gemacht werden. In einem aktuellen Beispiel wurde Air Canada dazu verurteilt, einen Kunden zu entschädigen, der durch den Chatbot der Fluggesellschaft in die Irre geführt wurde.
- Benutzervertrauen: Der „Black-Box“-Charakter von KI-Agenten und ähnlichen Beispielen macht es für Benutzer schwierig, ihre Ergebnisse zu verstehen und ihnen zu vertrauen. Bei sensiblen Aufgaben, bei denen es um Zahlungen oder persönliche Daten geht (z. B. Rechnungen bezahlen, Einkaufen usw.), wird es schwierig sein, das Vertrauen der Benutzer zu gewinnen.
Real-World-Versuche
Aktuell engagieren sich folgende Startups im Bereich KI-Agenten, die meisten befinden sich jedoch noch im Experimentierstadium oder sind nur auf Einladung erhältlich:
- adept.ai - 350 Millionen US-Dollar wurden gesammelt, aber der Zugang bleibt sehr begrenzt.
- MultiOn – Finanzierungsstatus unbekannt, ihr API-First-Ansatz sieht vielversprechend aus.
- HypeWrite – Bringt 2,8 Millionen US-Dollar ein, begann als KI-Schreibassistent und expandierte später zu Agenten.
- minion.ai – erregte zunächst einige Aufmerksamkeit, ist aber jetzt inaktiv und es gibt nur noch eine Warteliste.
Unter ihnen scheint nur MultiOn die Methode des „Erteilens von Anweisungen und Beobachten ihrer Ausführung“ zu verfolgen, was eher dem Versprechen von KI-Agenten entspricht.
Alle anderen Unternehmen gehen den RPA-Weg (Record-and-Replay), der in dieser Phase möglicherweise notwendig ist, um die Zuverlässigkeit sicherzustellen.
Gleichzeitig bringen einige große Unternehmen auch KI-Funktionen auf den Desktop und den Browser, und es sieht so aus, als würden sie eine native KI-Integration auf Systemebene erhalten.
OpenAI hat seine Mac-Desktop-App angekündigt, die mit dem Betriebssystembildschirm interagiert.
Auf der Google I/O demonstrierte Google Gemini zur Automatisierung von Einkaufsretouren.

Microsoft hat Copilot Studio angekündigt, mit dem Entwickler KI-Agentenroboter bauen können.
Diese technischen Demonstrationen sind beeindruckend, und die Leute können abwarten und sehen, wie diese Agentenfunktionen funktionieren, wenn sie öffentlich veröffentlicht und in realen Szenarien getestet werden, anstatt sich auf sorgfältig ausgewählte Demonstrationsfälle zu beschränken.
Welchen Weg werden KI-Agenten einschlagen?
Der Autor betont: „KI-Agenten wurden überbewertet und die meisten sind noch nicht bereit für den geschäftskritischen Einsatz.“
Angesichts der schnellen Entwicklung grundlegender Modelle und Architekturen sagte er jedoch, dass die Menschen dies immer noch können Wir freuen uns auf weitere erfolgreiche Praxiseinsätze.
Der vielversprechendste Weg für KI-Agenten könnte so aussehen:
- Der kurzfristige Schwerpunkt sollte auf der Erweiterung bestehender Tools durch KI liegen, anstatt eine breite Palette vollständig autonomer eigenständiger Dienste bereitzustellen.
- Die Methode der Mensch-Maschine-Kollaboration ermöglicht es Menschen, sich an der Überwachung und Bearbeitung von Grenzfällen zu beteiligen.
- Setzen Sie realistische Erwartungen basierend auf Ihren aktuellen Fähigkeiten und Einschränkungen.
Durch die Kombination eng begrenzter LLMs, guter Auswertungsdaten, kollaborativer Mensch-Maschine-Überwachung und traditioneller Engineering-Methoden ist es möglich, bei komplexen Aufgaben wie der Automatisierung zuverlässige und gute Ergebnisse zu erzielen.
Werden KI-Agenten mühsame und sich wiederholende Aufgaben wie Web Scraping, Formularausfüllen und Dateneingabe automatisieren?
Autor: „Ja, absolut.“
Wird ein KI-Agent also automatisch einen Urlaub ohne menschliches Eingreifen buchen?
Autor: „Zumindest in naher Zukunft unwahrscheinlich.“
Das obige ist der detaillierte Inhalt vonHype und Realität von KI-Agenten: GPT-4 kann dies nicht einmal unterstützen und die Erfolgsquote realer Aufgaben beträgt weniger als 15 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!