


超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件、目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问、操作,从而获取我们想要的内容。对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了。
首先要说明的是,urllib2并非是urllib的升级版,虽然同样作为处理url的相关模块,个人推荐尽量使用urllib2的接口,但我们并不能用urllib2完全代替urllib,处理URL资源有时会需要urllib中的一些函数(如urllib.urllencode)来处理数据。但二者处理url的大致思想都是通过底层封装好的接口让我们能够对url像对本地文件一样进行读取等操作。
下面就是一个获取百度页面内容的代码:
import urllib2
connect= urllib2.Request('http://www.baidu.com')
url1 = urllib2.urlopen(connect)
print url.read()
短短4行在运行之后,就会显示出百度页面的源代码。它的机理是什么呢?
当我们使用urllib2.Request的命令时,我们就向百度搜索的url(“www.baidu.com”)发出了一次HTTP请求,并将该请求映射到connect变量中,当我们使用urllib2.urlopen操作connect后,就会将connect的值返回到url1中,然后我们就可以像操作本地文件一样对url1进行操作,比如这里我们就使用了read()函数来读取该url的源代码。
这样,我们就可以写一只属于自己的简单爬虫了~下面是我写的抓取天涯连载的爬虫:
import urllib2
url1="http://bbs.tianya.cn/post-16-835537-"
url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB"
for i in range(1,481):
a=urllib2.Request(url1+str(i)+url3)
b=urllib2.urlopen(a)
path=str("D:/noval/天眼传人"+str(i)+".html")
c=open(path,"w+")
code=b.read()
c.write(code)
c.close
print "当前下载页数:",i
事实上,上面的代码使用urlopen就可以达到相同的效果了:
import urllib2
url1="http://bbs.tianya.cn/post-16-835537-"
url3=".shtml#ty_vip_look[%E6%8B%89%E9%A3%8E%E7%86%8A%E7%8C%AB"
for i in range(1,481):
#a=urllib2.Request(url1+str(i)+url3)
b=urllib2.urlopen((url1+str(i)+url3)
path=str("D:/noval/天眼传人"+str(i)+".html")
c=open(path,"w+")
code=b.read()
c.write(code)
c.close
print "当前下载页数:",i
为什么我们还需要先对url进行request处理呢?这里需要引入opener的概念,当我们使用urllib处理url的时候,实际上是通过urllib2.OpenerDirector实例进行工作,他会自己调用资源进行各种操作如通过协议、打开url、处理cookie等。而urlopen方法使用的是默认的opener来处理问题,也就是说,相当的简单粗暴~对于我们post数据、设置header、设置代理等需求完全满足不了。
因此,当面对稍微高点的需求时,我们就需要通过urllib2.build_opener()来创建属于自己的opener,这部分内容我会在下篇博客中详细写~
而对于一些没有特别要求的网站,仅仅使用urllib的2个模块其实就可以获取到我们想要的信息了,但是一些需要模拟登陆或者需要权限的网站,就需要我们处理cookies后才能顺利抓取上面的信息,这时候就需要Cookielib模块了。cookielib 模块就是专门用来处理cookie相关了,其中比较常用的方法就是能够自动处理cookie的CookieJar()了,它可以自动存储HTTP请求生成的cookie,并向传出HTTP的请求中自动添加cookie。正如我前文所提到的,想要使用它的话,需要创建一个新的opener:
import cookielib, urllib2 cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
经过这样的处理后,cookie的问题就解决了~
而想要将cookies输出出来的话,使用print cj._cookies.values()命令后就可以了~
抓取豆瓣同城、登陆图书馆查询图书归还
在掌握了urllib几个模块的相关用法后,接下来就是进入实战步骤了~
(一)抓取豆瓣网站同城活动
豆瓣北京同城活动 该链接指向豆瓣同城活动的列表,向该链接发起request:
# encoding=utf-8 import urllib import urllib2 import cookielib import re cj=cookielib.CookieJar() opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) url="http://beijing.douban.com/events/future-all?start=0" req=urllib2.Request(url) event=urllib2.urlopen(req) str1=event.read()
我们会发现返回的html代码中,除了我们需要的信息之外,还夹杂了大量的页面布局代码:

如上图所示,我们只需要中间那些关于活动的信息。而为了提取信息,我们就需要正则表达式了~
正则表达式是一种跨平台的字符串处理工具/方法,通过正则表达式,我们可以比较轻松的提取字符串中我们想要的内容~
这里不做详细介绍了,个人推荐余晟老师的正则指引,挺适合新手入门的。下面给出正则表达式的大致语法:
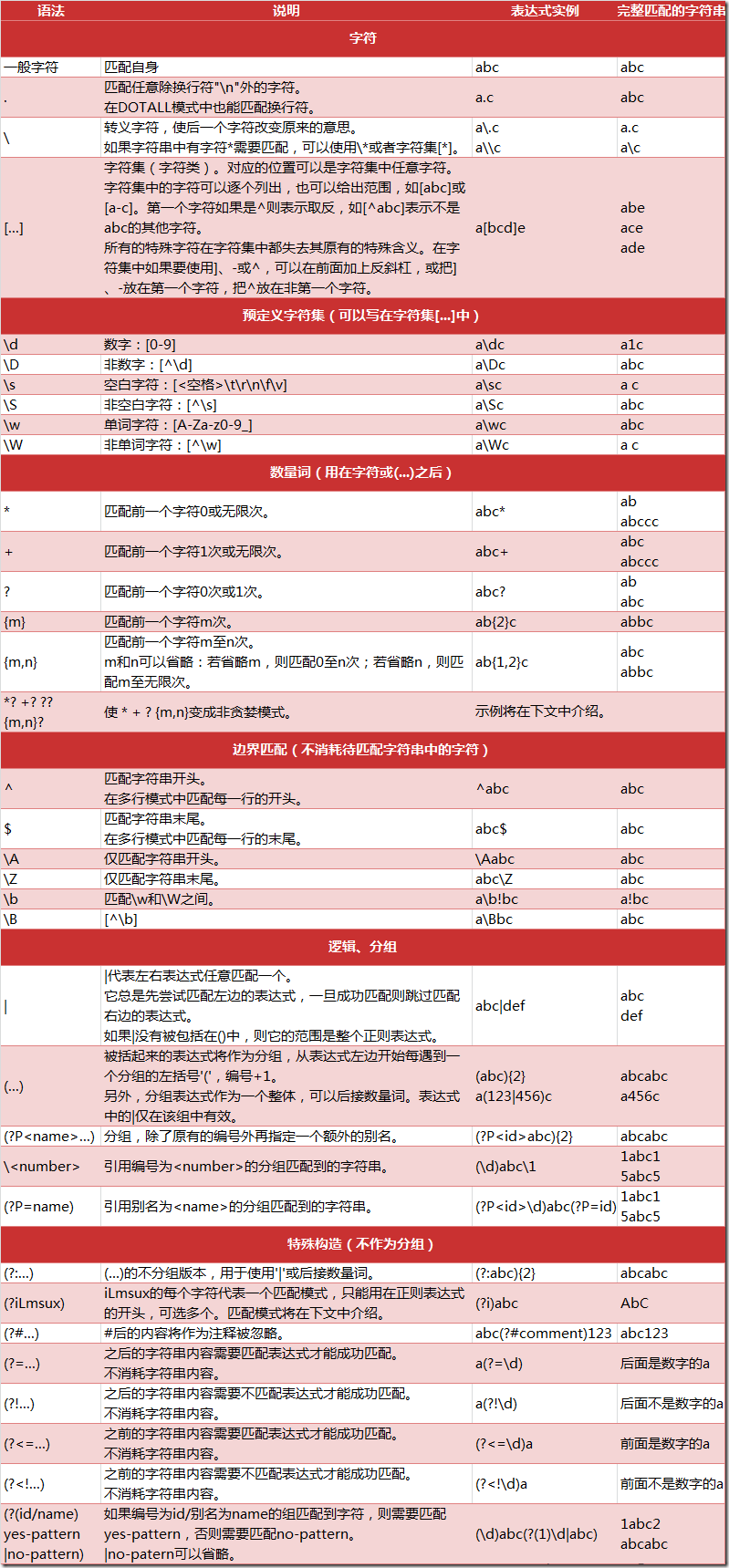
这里我使用捕获分组,将活动四要素(名称,时间,地点,费用)为标准进行分组,得到的表达式如下:
regex=re.compile(r'summary">([\d\D]*?)[\d\D]*?class="hidden-xs">([\d\D]*?)

 Was sind die Alternativen zur Verkettung von zwei Listen in Python?May 09, 2025 am 12:16 AM
Was sind die Alternativen zur Verkettung von zwei Listen in Python?May 09, 2025 am 12:16 AMEs gibt viele Methoden, um zwei Listen in Python zu verbinden: 1. Verwenden Sie Operatoren, die in großen Listen einfach, aber ineffizient sind; 2. Verwenden Sie die Erweiterungsmethode, die effizient ist, die ursprüngliche Liste jedoch ändert. 3.. Verwenden Sie den operator =, der sowohl effizient als auch lesbar ist; 4. Verwenden Sie die Funktion iterertools.chain, die Speichereffizient ist, aber zusätzlichen Import erfordert. 5. Verwenden Sie List Parsing, die elegant ist, aber zu komplex sein kann. Die Auswahlmethode sollte auf dem Codekontext und den Anforderungen basieren.
 Python: Effiziente Möglichkeiten, zwei Listen zusammenzuführenMay 09, 2025 am 12:15 AM
Python: Effiziente Möglichkeiten, zwei Listen zusammenzuführenMay 09, 2025 am 12:15 AMEs gibt viele Möglichkeiten, Python -Listen zusammenzuführen: 1. Verwenden von Operatoren, die einfach, aber nicht für große Listen effizient sind; 2. Verwenden Sie die Erweiterungsmethode, die effizient ist, die ursprüngliche Liste jedoch ändert. 3. Verwenden Sie iTertools.chain, das für große Datensätze geeignet ist. 4. Verwenden Sie * Operator, fusionieren Sie kleine bis mittelgroße Listen in einer Codezeile. 5. Verwenden Sie Numpy.concatenate, das für große Datensätze und Szenarien mit hohen Leistungsanforderungen geeignet ist. 6. Verwenden Sie die Append -Methode, die für kleine Listen geeignet ist, aber ineffizient ist. Bei der Auswahl einer Methode müssen Sie die Listengröße und die Anwendungsszenarien berücksichtigen.
 Kompiliert gegen interpretierte Sprachen: Vor- und NachteileMay 09, 2025 am 12:06 AM
Kompiliert gegen interpretierte Sprachen: Vor- und NachteileMay 09, 2025 am 12:06 AMCompiledLanguageOfferSpeedandSecurity, während interpretedLanguagesProvideaseofuseAnDportabilität.1) kompiledlanguageslikec areFasterandSecurebuthavelongerDevelopmentCyclesandplatformDependency.2) InterpretedLanguages -pythonareaToReAndoreAndorePortab
 Python: Für und während Schleifen der vollständigste LeitfadenMay 09, 2025 am 12:05 AM
Python: Für und während Schleifen der vollständigste LeitfadenMay 09, 2025 am 12:05 AMIn Python wird eine für die Schleife verwendet, um iterable Objekte zu durchqueren, und eine WHHE -Schleife wird verwendet, um Operationen wiederholt durchzuführen, wenn die Bedingung erfüllt ist. 1) Beispiel für Schleifen: Überqueren Sie die Liste und drucken Sie die Elemente. 2) Während des Schleifens Beispiel: Erraten Sie das Zahlenspiel, bis Sie es richtig erraten. Mastering -Zyklusprinzipien und Optimierungstechniken können die Code -Effizienz und -zuverlässigkeit verbessern.
 Python verkettet listet in eine Zeichenfolge aufMay 09, 2025 am 12:02 AM
Python verkettet listet in eine Zeichenfolge aufMay 09, 2025 am 12:02 AMUm eine Liste in eine Zeichenfolge zu verkettet, ist die Verwendung der join () -Methode in Python die beste Wahl. 1) Verwenden Sie die monjoy () -Methode, um die Listelemente in eine Zeichenfolge wie "" .Join (my_list) zu verkettet. 2) Für eine Liste, die Zahlen enthält, konvertieren Sie die Karte (STR, Zahlen) in eine Zeichenfolge, bevor Sie verkettet werden. 3) Sie können Generatorausdrücke für komplexe Formatierung verwenden, wie z. 4) Verwenden Sie bei der Verarbeitung von Mischdatentypen MAP (STR, MIXED_LIST), um sicherzustellen, dass alle Elemente in Zeichenfolgen konvertiert werden können. 5) Verwenden Sie für große Listen '' .Join (large_li
 Pythons Hybridansatz: Zusammenstellung und Interpretation kombiniertMay 08, 2025 am 12:16 AM
Pythons Hybridansatz: Zusammenstellung und Interpretation kombiniertMay 08, 2025 am 12:16 AMPythonusesahybridapproach, kombinierte CompilationTobyteCodeAnDinterpretation.1) codiscompiledtoplatform-unintenpendentBytecode.2) BytecodeIsinterpretedBythepythonvirtualMachine, EnhancingEfficiency und Portablabilität.
 Erfahren Sie die Unterschiede zwischen Pythons 'für' und 'while the' LoopsMay 08, 2025 am 12:11 AM
Erfahren Sie die Unterschiede zwischen Pythons 'für' und 'while the' LoopsMay 08, 2025 am 12:11 AMDie Keedifferzences -zwischen Pythons "für" und "während" Loopsare: 1) "für" LoopsareideAlForiteratingOvercesorknownowniterations, während 2) "LoopsarebetterForContiningUtilAconditionismethoutnredefineditInations.un
 Python verkettet Listen mit DuplikatenMay 08, 2025 am 12:09 AM
Python verkettet Listen mit DuplikatenMay 08, 2025 am 12:09 AMIn Python können Sie Listen anschließen und doppelte Elemente mit einer Vielzahl von Methoden verwalten: 1) Verwenden von Operatoren oder erweitert (), um alle doppelten Elemente beizubehalten; 2) Konvertieren in Sets und kehren Sie dann zu Listen zurück, um alle doppelten Elemente zu entfernen. Die ursprüngliche Bestellung geht jedoch verloren. 3) Verwenden Sie Schleifen oder listen Sie Verständnisse auf, um Sätze zu kombinieren, um doppelte Elemente zu entfernen und die ursprüngliche Reihenfolge zu verwalten.


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Sicherer Prüfungsbrowser
Safe Exam Browser ist eine sichere Browserumgebung für die sichere Teilnahme an Online-Prüfungen. Diese Software verwandelt jeden Computer in einen sicheren Arbeitsplatz. Es kontrolliert den Zugriff auf alle Dienstprogramme und verhindert, dass Schüler nicht autorisierte Ressourcen nutzen.

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

