Heim > Artikel > Backend-Entwicklung > Python爬虫模拟登录带验证码网站
Python爬虫模拟登录带验证码网站

- WBOYOriginal
- 2016-06-10 15:06:281630Durchsuche
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的url库,想做到这个并不难。这里以登录学校教务系统为例,做一个简单的例子。
首先得明白cookie的作用,cookie是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。因此我们需要用Cookielib模块来保持网站的cookie。
这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.aspx
可以发现这个验证码是动态更新的每次打开都不一样,一般这种验证码和cookie是同步的。其次想识别验证码肯定是吃力不讨好的事,因此我们的思路是首先访问验证码页面,保存验证码、获取cookie用于登录,然后再直接向登录地址post数据。
首先通过抓包工具或者火狐或者谷歌浏览器分析登录页面需要post的request和header信息。以谷歌浏览器为例。
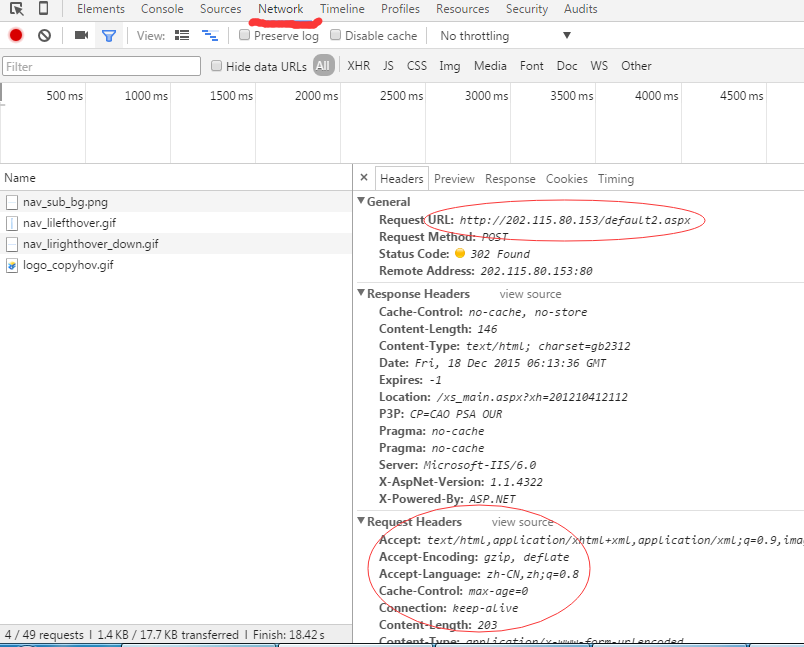
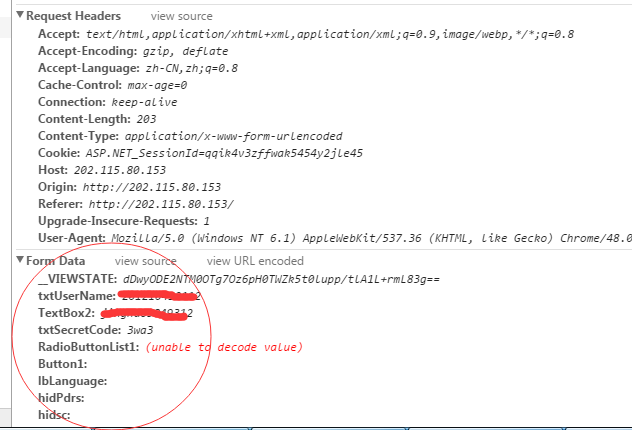
从中可以看出需要post的url并不是访问的页面,而是http://202.115.80.153/default2.aspx,
其中需要提交的表单数据中txtUserName和TextBox2分别用户名和密码。
现在直接到关键部分 上代码!!
import urllib2
import cookielib
import urllib
import re
import sys
'''模拟登录'''
reload(sys)
sys.setdefaultencoding("utf-8")
# 防止中文报错
CaptchaUrl = "http://202.115.80.153/CheckCode.aspx"
PostUrl = "http://202.115.80.153/default2.aspx"
# 验证码地址和post地址
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
# 将cookies绑定到一个opener cookie由cookielib自动管理
username = 'username'
password = 'password123'
# 用户名和密码
picture = opener.open(CaptchaUrl).read()
# 用openr访问验证码地址,获取cookie
local = open('e:/image.jpg', 'wb')
local.write(picture)
local.close()
# 保存验证码到本地
SecretCode = raw_input('输入验证码: ')
# 打开保存的验证码图片 输入
postData = {
'__VIEWSTATE': 'dDwyODE2NTM0OTg7Oz6pH0TWZk5t0lupp/tlA1L+rmL83g==',
'txtUserName': username,
'TextBox2': password,
'txtSecretCode': SecretCode,
'RadioButtonList1': '学生',
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': '',
}
# 根据抓包信息 构造表单
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',
}
# 根据抓包信息 构造headers
data = urllib.urlencode(postData)
# 生成post数据 ?key1=value1&key2=value2的形式
request = urllib2.Request(PostUrl, data, headers)
# 构造request请求
try:
response = opener.open(request)
result = response.read().decode('gb2312')
# 由于该网页是gb2312的编码,所以需要解码
print result
# 打印登录后的页面
except urllib2.HTTPError, e:
print e.code
# 利用之前存有cookie的opener登录页面
登录成功后便可以利用该openr访问其他需要登录才能访问的页面。
Stellungnahme:
Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn
Vorheriger Artikel:深入剖析Python的爬虫框架Scrapy的结构与运作流程Nächster Artikel:实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Erläuterung von Python-bezogenen Operationsbeispielen auf JSON
- Python Fabric implementiert die Remote-Bereitstellung
- So implementieren Sie den SSH-Fernzugriff mit Python Paramiko
- Python Fabric implementiert Beispiele für Remote-Betrieb und -Bereitstellung
- Python Fabric implementiert die Remote-Bereitstellung