关键词:深度学习、卷积神经网络、可解释性、表征可视化、显著图
近年来, 以深度神经网络(Deep neural networks, DNN)为代表的机器学习方法逐渐兴起[1]. 由于训练数据的增加[2-3]及计算能力的大幅提升, DNN的网络结构及与之相适应的优化算法[4-6]变得更加复杂, DNN在各项任务上的性能表现也越来越好, 产生了多种适用于不同类型数据处理任务的经典深度网络结构, 如卷积神经网络(Convolutional neural network, CNN)和循环神经网络(Recurrent neural network, RNN). 对于图像数据处理与识别领域, CNN是一种十分常用的网络结构, 在图像分类、目标检测、语义分割等任务上取得了非常好的效果, 已经成为该领域应用最广泛的基础模型[7].
如图1所示, 传统机器学习算法采用人工设计的特征集, 按照专家经验和领域知识将其组织到机器学习算法中. 由于设计人员本身了解这些被定义特征的具体含义, 因此, 传统机器学习方法一定程度上是可解释的, 人们大致明白算法对各种特征的依赖以及算法的决策依据. 例如, 线性模型可使用特征对应的权重代表特征重要程度. 相比于传统机器学习算法, 以CNN为代表的深度学习算法属于特征学习或表示学习, 可对输入数据进行自动特征提取及分布式表示, 解决了人工特征设计的难题. 这一优势使其能够学习到更加丰富完备的且含有大量深层语义信息的特征及特征组合, 因此在性能表现上超过多数传统机器学习算法.
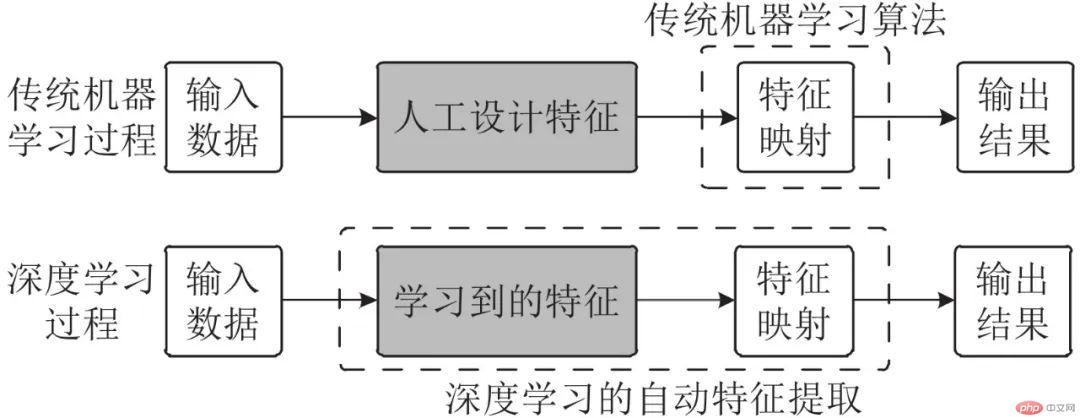
图 1 传统机器学习与深度学习的学习过程对比[8]
Fig. 1 Comparison of the learning process between traditional machine learning and deep learning[8]
然而, CNN这一优势的背后也存在着一定局限性. 一方面, 人们至今无法较好地理解CNN内部知识表示及其准确的语义含义. 即使是模型设计者也难以回答CNN到底学习到了哪些特征、特征的具体组织形式以及不同特征的重要性度量等问题, 导致CNN模型的诊断与优化成为经验性、甚至盲目性的反复试探, 这不仅影响了模型性能, 还可能遗留潜在的漏洞; 另一方面, 基于CNN模型的现实应用在日常中已经大量部署, 如人脸识别、行人检测和场景分割等, 但对于一些风险承受能力较低的特殊行业, 如医疗、金融、交通、军事等领域, 可解释性和透明性问题成为其拓展和深入的重大阻碍. 这些领域对CNN等深度学习模型有着强烈的现实需求, 但受限于模型安全性与可解释性问题, 目前仍无法大规模使用. 模型在实际中可能犯一些常识性错误, 且无法提供错误原因, 导致人们难以信任其决策.
因此, 对CNN的理解和解释逐渐受到人们关注, 研究者们尝试从不同角度出发, 解释CNN的特征编码和决策机制. 表征可视化作为其中一种解释方法, 采用基于特征重要性的解释思路, 寻找输入变量、特征编码及输出结果之间的相关性, 并以视觉展示的方式直观呈现, 是一种较为直接的理解CNN的途径. 本文对该领域的现有研究进行了系统性整理和回顾, 对其中涉及的相关概念及内容、典型方法、效果评估、应用等方面作了归纳总结, 着重介绍了可视化方法的分类及算法的具体过程. 最后, 分析了该领域仍存在的难点并展望了未来研究趋势.
相关概念与研究内容
1.1.1
CNN
目前, CNN已成为基于深度学习的图像识别领域应用最广泛、效果最佳的网络结构. 最早的CNN由LeCun等[9]于1998年提出, 用于手写体数字识别. CNN的基本结构中含有输入层、卷积层、全连接层及输出层. 其中输入层、全连接层、输出层与其他网络大致相同, 仅卷积层是CNN特有的结构. 经典CNN卷积层中含有卷积、激活和池化3种操作: 1)卷积操作使用多个卷积核(滤波器)在输入张量上平移作内积运算, 得到对应的特征图. 同层的不同卷积核用来提取不同模式的特征, 不同层的卷积核则用来提取不同层级的特征. 2)激活操作使用非线性激活函数处理卷积结果, 用于提升网络的非线性特性, 增强非线性拟合能力, 常用的激活函数如tanh、sigmoid、rectified linear unit (ReLU)[6]和改进版[10-11]等. 3)池化操作一般使用最大值池化和平均值池化, 按照池化窗口处理整个窗口内的值, 用于压缩参数和降低过拟合.
稀疏连接和权重共享是CNN相对于前馈神经网络的主要特点. 基于这些经典的CNN结构及其特性, 研究人员通过不断改进和优化[12], 逐渐设计出结构更复杂且识别性能更优异的CNN, 以在Imagenet Large Scale Visual Recognition Competition (ILSVRC)数据集[2]图像分类任务上的优胜CNN模型为例:
2012年, Krizhevsky等[1]提出了AlexNet, 在图像分类任务上以巨大优势取得冠军, 成功吸引了学术界的关注, 成为新阶段CNN兴起的标志.
2013年, Zeiler等[13]提出了ZFNet, 利用反卷积可视化技术诊断AlexNet的内部表征, 然后对其针对性地做了改进, 使用较小的卷积核和步长, 从而提升了性能.
2014年, 谷歌公司Szegedy等[14]提出了GoogLeNet, 核心是其中的Inception模块, 使用了不同尺寸的卷积核进行多尺度的特征提取和融合, 从而更好地表征图像. 同年, 牛津大学的Simonyan等[15]提出了视觉几何组网络(Visual geometry group network, VGGNet), 仅使用2 × 2和3 × 3两种典型的卷积核, 通过简单地增加层的深度实现了性能提升.
2015年, 微软公司He等[16]提出了残差网络(Residual networks, ResNet), 使用残差连接实现跨层的信息传播, 缓解了之前由于深度增加引起的梯度消失问题, 并以3.57%的错误率首次超越人类水平.
2016年, Huang等[17]提出了DenseNet, 相比于ResNet, 使用了密集连接操作, 强化特征的传播和复用.
2017年, Hu等[18]提出了压缩激励网络(Squeeze-and-excitation networks, SENet), 通过特征图各通道间的权值自适应再调整, 实现各个通道之间的特征重标定, 提升了网络的特征提取能力.
CNN在图像数据处理上有天然的优势, 因而在图像分类、目标检测、语义分割和场景识别等领域应用广泛, 在其他模态的数据如视频、语音和文本等领域也有较多应用. 图像分类是CNN最典型的应用领域, 许多图像分类系统使用预训练的CNN进行部署. 预训练的CNN是指已经在某个数据集上完成训练的CNN模型. 一般情况下, 预训练的CNN由研究人员设计并调整至最佳状态, 在实际场景中可以直接使用而无需再训练. 由于预训练CNN模型在现实中经常使用, 因此, 针对预训练CNN模型的理解和解释是可解释性研究中的一项重要内容.
1.1.2
可解释性
可解释性是近年来深度学习领域的研究热点. 可解释性与可理解性的含义并不相同[19-20], 文献[19]从CNN特征表示形式的角度出发, 对CNN的“可解释性”和“可理解性”做了区分: 可解释性表示从抽象概念(向量空间、非结构化特征空间)到人类可理解的领域(图像和文字等)的映射, 而可理解性表示可解释域内促使模型产生特定决策的一组特征. 从这种区分看, “可解释性”研究重点在于将参数化形式表示的特征映射到人类可直观感受的表示形式, 而“可理解性”侧重在人类可理解的领域中寻找与模型某个决策相关的具体特征. 也就是说, “解释”是一种从不可解释域到可解释域的映射动作, “理解”则是一种在可解释域内寻找感兴趣证据的过程. 麻省理工的研究人员认为[20], 通过“解释”能够实现对深度网络的“理解”, 可解释性的研究目标是以某种人类可理解的方式描述一个系统的内部机制. 同时, 将可解释性的研究内容分为DNN处理过程的理解、DNN内部表征的理解和自解释的DNN三个方面.
深度学习可解释性的研究内容非常丰富, 本文从可解释性研究的模型对象出发, 根据待解释的目标模型是否已经完成训练, 将深度学习可解释性研究划分为两部分: 事后解释和自解释模型, 如图2所示[21].
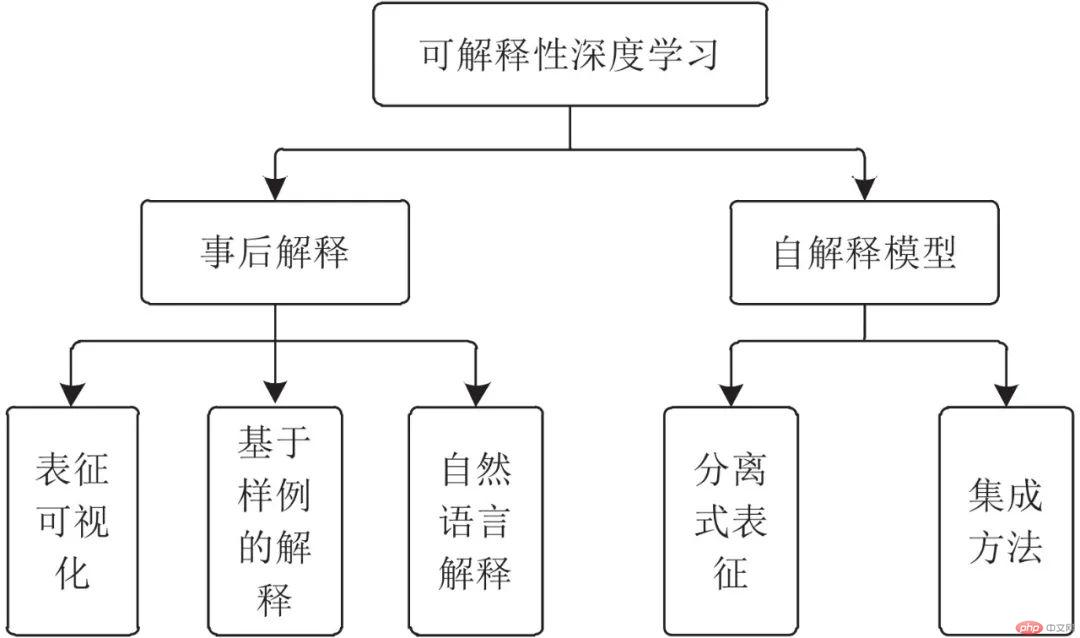
图 2 可解释性深度学习的研究内容划分
Fig. 2 The division of the research content of the interpretable deep learning
事后解释是对预训练模型的解释. 现实中, 由于模型已经完成训练和部署, 而重新训练模型耗费的时间和资源成本过大, 因此不具备重新训练的可能性. 针对这种模型的解释, 需要在不修改模型自身结构及参数的情况下完成, 结合预训练模型的输入、中间层参数和输出等信息, 实现对模型内部表征及决策结果的解释.
对于预训练模型的事后解释方法, 现有研究主要分为以下3类:
表征可视化. 表征可视化是一种基于特征重要性的解释方法, 主要研究模型内部的特征表示及这些特征与模型输入、输出之间的关系. 梯度归因方法[22-23]是最具代表性的表征可视化方法, 使用输入空间中像素自身的梯度 (或绝对值、平方等)来衡量该像素与结果的关联程度. 表征可视化与模型结构可视化不同, 前者重在研究模型内部特征(以参数的形式)的语义理解, 以及输入、特征编码及输出之间的因果关系, 后者研究模型结构、数据流向及形状的变化.
基于样例的解释. 基于样例的解释是一种基于样本重要性的解释方法, 采用训练数据中的样本原型作为当前决策结果的解释[24-25]. 这种方法模拟人对事物的解释过程[26], 从数据集中已有样本(已经学习过)中找到相似样本, 作为对新的样本结果的比较.
自然语言解释. 自然语言解释以人类可理解的自然语言形式, 对CNN识别结果进行解释[27]. 该过程中, 需要将CNN的图像特征编码映射为RNN的自然语言特征编码, 通过跨模态的表征融合来生成用于解释CNN输入与输出的自然语言. 该过程与图像描述[28]和视觉问答[29]相似.
自解释模型不同于事后解释, 其在模型设计时即考虑了内在可解释性, 在此基础上进行训练和优化, 形成结构上或逻辑上具有内生可解释性的模型. 自解释模型能够在应用的同时由其自身为用户提供对输出结果的解释.
对于建立具有自身可解释性的模型, 现有研究主要分为以下2类:
分离式表征: 在模型结构或优化过程中添加一些约束, 以降低模型复杂性, 同时保证模型的性能, 使模型内部的表征分离可理解. 例如, Zhang等[30]对滤波器的学习进行约束, 训练出可解释的滤波器, 使每个滤波器有针对性地关注特定目标部位.
集成方法: 结合传统可解释性较好的机器学习方法, 构建在深度神经网络的识别性能和传统方法的可解释性之间折衷的新模型. 例如, 将神经网络集成到决策树算法中, 使用神经网络提取的特征作为输入, 这样训练得到的模型同时具有两者的优点, 可实现决策路径的清晰可理解[31].
1.1.3
表征可视化
表征可视化是一种事后解释方法, 通常以视觉的方式对CNN内部表征和输出决策进行解释. 表征可视化尝试解释CNN内部特征的表示形式、输入–内部特征–输出三者之间的关系、促使网络做出当前的输入等问题。与其他方法相比, 表征可视化方法具有以下优点: 1)简单直观, 从视觉上为用户提供观察. 2)便于深度分析网络表征, 诊断训练效果, 进而改进网络结构设计. 3)无需修改模型结构, 多数表征可视化方法可在模型完成训练之后进行特征分析与决策结果解释, 无需修改或重新训练模型. 表征可视化方法生成的解释结果以热力图的方式呈现. 热力图是一个由不同颜色强度构成的图像, 像素颜色的强度与其重要性相对应. 从数学角度看, 热力图实际上是一组与输入变量对应的重要性值 (或相关性值)的集合, 集合中的每个元素值表示其对应的输入变量与输出结果之间的相关性.
1) CNN表征可视化
表征可视化过程与CNN过程相互依赖, 如图3所示. 图3上方为CNN过程, 下方为可视化方法的解释过程, 箭头表示这两个过程中各阶段之间的相互关系.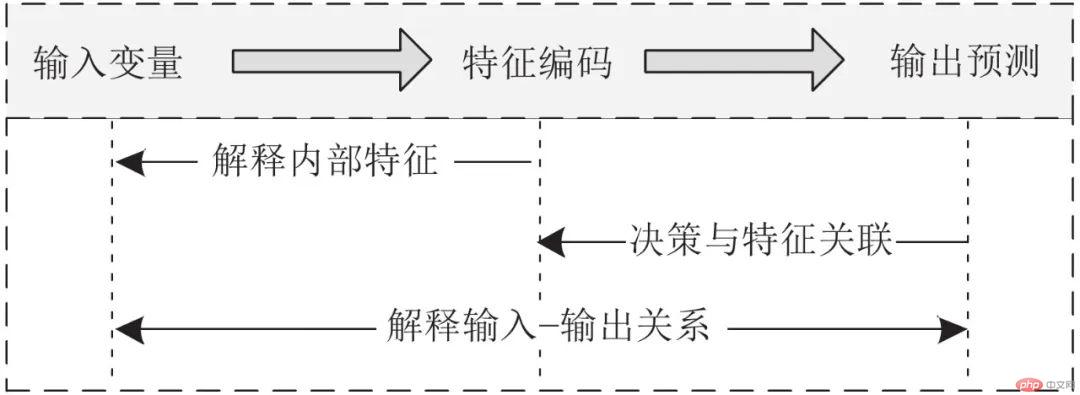
图 3 CNN表征可视化的研究思路
Fig. 3 The research idea of CNN representation visualization
CNN过程: 实现从输入变量到输出的映射. 其中, 输入变量对应的输入空间被认为是人类可理解的空间(例如图像和语言文本), 而特征编码对应的特征空间经过了CNN的自动特征提取与特征组合. 可视化解释CNN的目的就是将中间层特征编码和输出层结果反向映射到输入空间, 实现不可解释域向可解释域的映射.
可视化方法的解释过程涉及3种: 1)解释内部特征: 研究黑盒中间编码了哪些知识, 以怎样的形式组织这些知识的. 2)决策与特征关联: 研究中间层的知识与输出之间的关系. 3)解释输入–输出关系: 研究输入变量、中间层特征编码和输出三者之间的关系.
2) CNN、RNN和生成对抗网络表征可视化的比较
CNN在图像数据处理领域应用较为广泛, 层次化的表征方式使其适用于图像数据逐层学习的特性, 与人类非常相似. 因此, CNN表征可视化主要研究各个隐含层所编码的特征、这些特征的语义含义及与输入输出之间的关系. 对于另外两种常见的DNN: 循环神经网络(RNN)与生成对抗网络(Generative adversarial network, GAN), 表征可视化研究的关注点略有不同.
RNN是一种随时间步迭代的深度网络, 有长短时记忆网络 、门控循环单元等扩展版结构, 擅长处理时序型数据, 在自然语言处理领域应用广泛. RNN的主要特点在于其迭代式的处理数据, 这些迭代信息存储于网络结构中的隐状态中, 每个时间步的隐状态含义不同, RNN的长距离依赖关系学习能力也在于这些隐状态的学习效果. 因此, RNN可视化研究多专注于对这些隐藏状态的理解与解释. 例如, 文献[32]可视化RNN的隐状态对于输入的预期响应, 用于观察RNN内部的正面与负面输入时的激活分布. 文献[33]开发了一个长短时记忆网络可视化工具, 用于了解这些隐藏状态的动力学过程. 文献[34]通过可视化的方式解释了长短时记忆网络在长距离依赖关系学习上的优势. 此外, 一些图像领域常用的表征可视化方法如层级相关性反馈(Layer-wise relevance propagation, LRP)方法, 也被用于解释RNN的表征及量化输入–输出之间的关系[35-36].
GAN是一种生成式神经网络, 由生成器和判别器两部分构成, 二者之间通过对抗学习的方式互相提升性能[37]. 从结构上看, GAN的生成器一般使用反卷积结构, 判别器可视为一个CNN结构. 由于GAN主要用于学习数据的潜在分布, 然后用于生成式任务, 因此, GAN可视化的关注点主要在于生成器部分. 更具体地, 在于理解和解释生成器隐变量的作用. 典型的如InfoGAN[38], 对输入向量进行分解, 使其转为可解释的隐变量及不可压缩的噪声, 进而约束隐变量与输出之间的关系, 从而学习可解释的特征表达. 文献[39]和文献[40]通过操纵生成器的隐变量来观察生成结果的变化情况, 进而理解GAN的过程. 文献[41]专门研究了GAN隐空间的语义解纠缠问题, 提出了一种效果较好的人脸编辑方法, 可通过编辑GAN的隐空间来调整生成人脸的属性, 如姿势、性别和年龄等.

博客列表 >卷积神经网络表征可视化研究综述
卷积神经网络表征可视化研究综述
- P粉320606482原创转载
- 2022年08月09日 11:01:00596浏览
上一条:JS中的事件冒泡及事件代理下一条:基于互联网群体智能的知识图谱构造方法
声明:本文内容转载自脚本之家,由网友自发贡献,版权归原作者所有,如您发现涉嫌抄袭侵权,请联系admin@php.cn 核实处理。
全部评论
文明上网理性发言,请遵守新闻评论服务协议