CURD的常用操作:
样式代码:
// 增加四条数据insert staffs (name, gender, salary, email, birthday) values ('小王', 'male', 3440, 'abc@bb.com', '1999-11-11'), ('小李', 'female', 4550, 'cvb@cvb.con', '2000-11-11'), ('小白', 'male', 3566, 'nbn@bn.com', '1999-09-19'), ('小张', 'female', 6700, 'nsb@wd.com', '2001-01-21');// 删除小王delete from staffs where name = '小王';// 小白工资改为8566update staffs set salary = salary + 5000 where name = '小白';// 查看小白select name, gender, salary, email, birthday from staffs where name = '小白';
效果预览:

select查询:
样式代码:
// 一. 分组查询: 按性别查询:select gender 性别,count(1) 数量 from staffs group by gender;
效果预览:

// 二. 条件查询: 工资大于6000且性别为女select name,salary from staffs where salary>=6000 and gender = 'female';
效果预览:

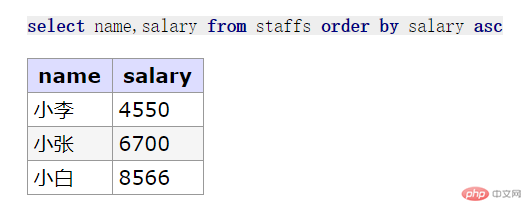
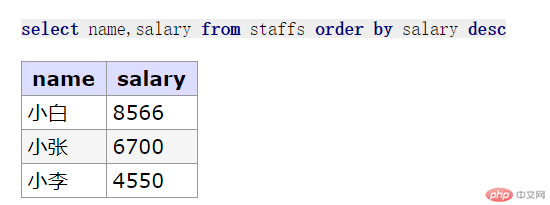
//三. 排序: 按工资进行排序select name,salary from staffs order by salary asc;// 降序: 按工资进行降序select name,salary from staffs order by salary desc;
效果预览:
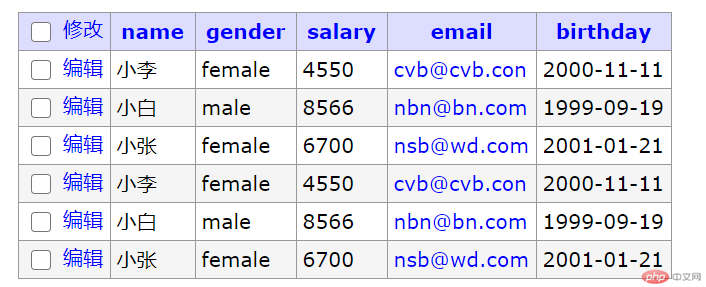
//四. 子查询式插入/复制插入insert staffs (name,gender, salary, email,birthday)(select name,gender, salary, email,birthday from staffs);
效果预览:
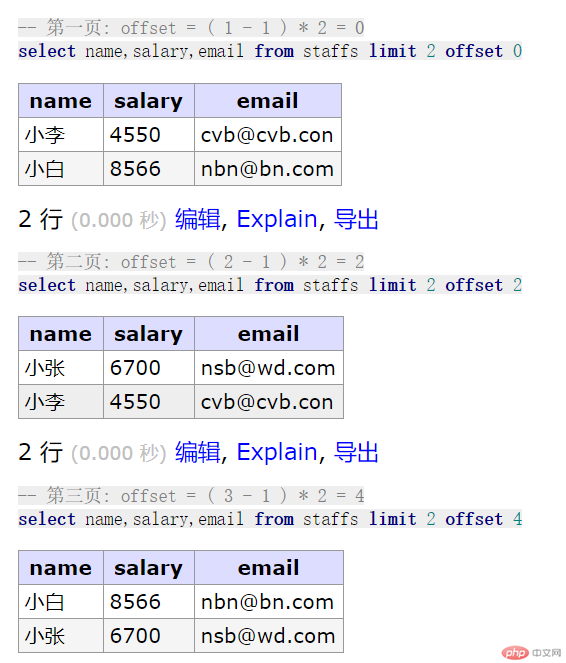
// 五. 分页查询: 每页显示两条数据// 第一页: offset = ( 1 - 1 ) * 2 = 0select name,salary,email from staffs limit 2 offset 0;// 第二页: offset = ( 2 - 1 ) * 2 = 2select name,salary,email from staffs limit 2 offset 2;// 第三页: offset = ( 3 - 1 ) * 2 = 4select name,salary,email from staffs limit 2 offset 4;
效果预览:
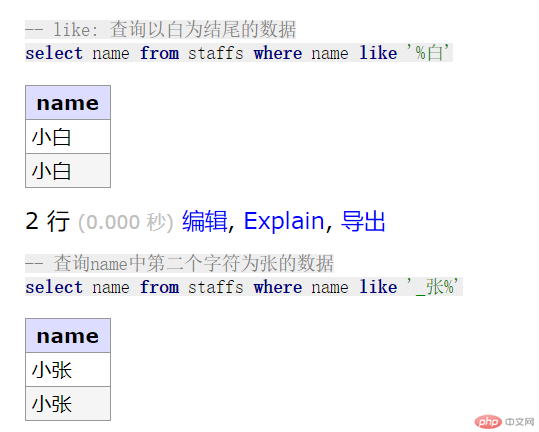
// 六. like: 查询name中以白为结尾的数据select name from staffs where name like '%白';// 查询name中第二个字为张的数据select name from staffs where name like '_张%';
效果预览:
关联操作:
样式代码:
//先创建一个信息热榜再来一个栏目表// 信息热榜create table wzb (aid int unsigned not null auto_increment,title varchar(100) not null comment '文章标题',cid int unsigned not null comment '栏目 id',primary Key (aid)) engine = innodb collate=utf8mb4_unicode_ci;-- ------------------------------------------insert wzb (title,cid) values ('有哪些给年轻人的忠告?',1), ('如何判断对方是个海王?',1), ('又遇跳槽季,在选择工作时有什么建议?', 2), ('校招c大概学习到什么程度?', 2);// 栏目表create table categories( cid int unsigned not null auto_increment, name varchar(100) not null comment '栏目名称', primary key (cid)) engine = innodb collate=utf8mb4_unicode_ci;-- -------------------------------------------insert categories (name) value('国内新闻'),('影视新闻'),('职场新闻'),('校园新闻');// 内连接select a.aid ,title, c.name from wzb as a, categories as c where a.cid = c.cid;// 简化select aid,title,name from wzb a, categories c where a.cid = c.cid;// 外连接: 左外连接,右外连接// 左外连接: 左表是主表,右边是从表select *from wzb aleft join categories con a.cid = c.cid;// 右外连接: 右表是主表,左边是从表select *from wzb aright join categories con a.cid = c.cid;// 转内连接select *from wzb aright join categories con a.cid = c.cidwhere a.aid is not null;// 将从表的为null的字段过滤掉// 自然连接: 是内连接的一个特例, 前提关联表中的存在同名字段,连using()都不要了, 如果用不到表别名,别名也不用了select aid,title,name from wzb natural join categories;
内连接效果预览:

左外连接效果预览:
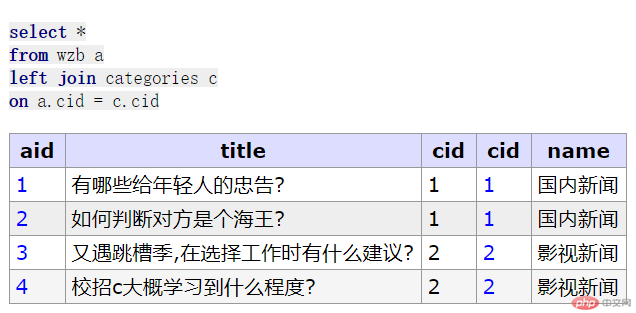
右外连接效果预览:
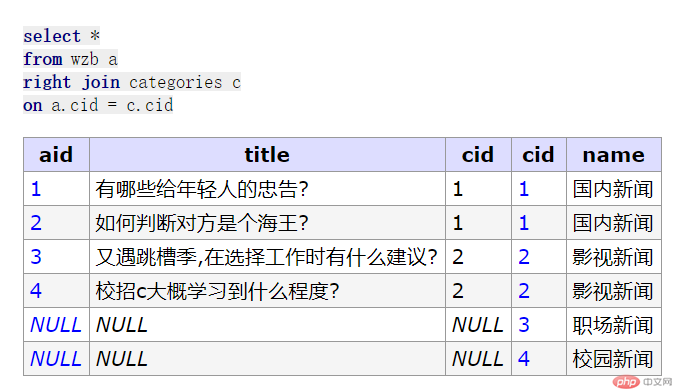
转内连接效果预览:
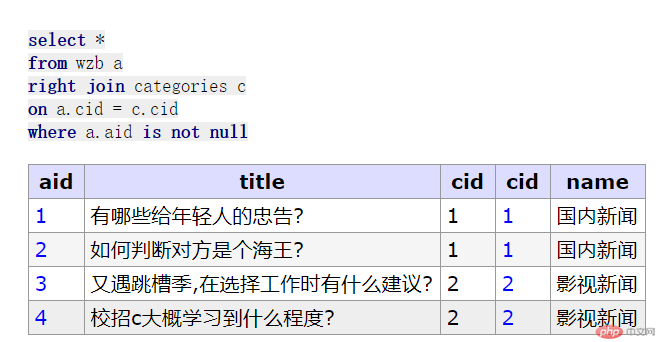
自然连接效果预览:
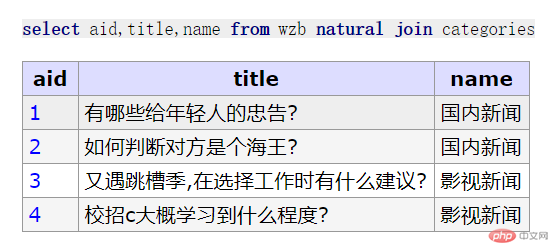
预处理原理:
防止 SQL 注入攻击, SQL 语句中的数据,只有在执行阶段再与字段进行绑定
样式代码:
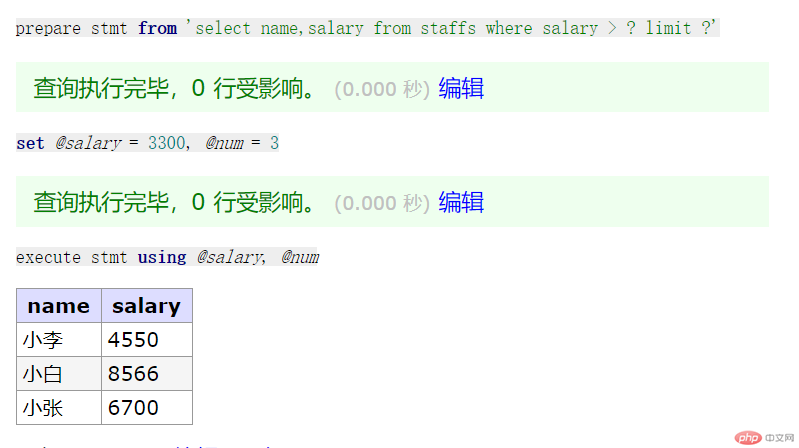
// 生成预处理的sql语句prepare stmt from 'select name,salary from staffs where salary > ? limit ?';// 将真实的数据绑定到预处理语句中的占位符上 ?set @salary = 3300, @num = 3;execute stmt using @salary, @num;
效果预览: